 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Defining Neural Averaging
Aug 20, 2025What does it even mean to average neural networks? We investigate the problem of synthesizing a single neural network from a collection of pretrained models, each trained on disjoint data shards, using only their final weights and no access to training data. In forming a definition of neural averaging, we take insight from model soup, which appears to aggregate multiple models into a singular model while enhancing generalization performance. In this work, we reinterpret model souping as a special case of a broader framework: Amortized Model Ensembling (AME) for neural averaging, a data-free meta-optimization approach that treats model differences as pseudogradients to guide neural weight updates. We show that this perspective not only recovers model soup but enables more expressive and adaptive ensembling strategies. Empirically, AME produces averaged neural solutions that outperform both individual experts and model soup baselines, especially in out-of-distribution settings. Our results suggest a principled and generalizable notion of data-free model weight aggregation and defines, in one sense, how to perform neural averaging.
Avoiding Tampering Incentives in Deep RL via Decoupled Approval
Nov 17, 2020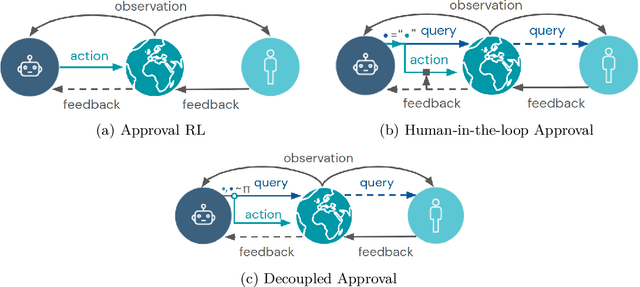
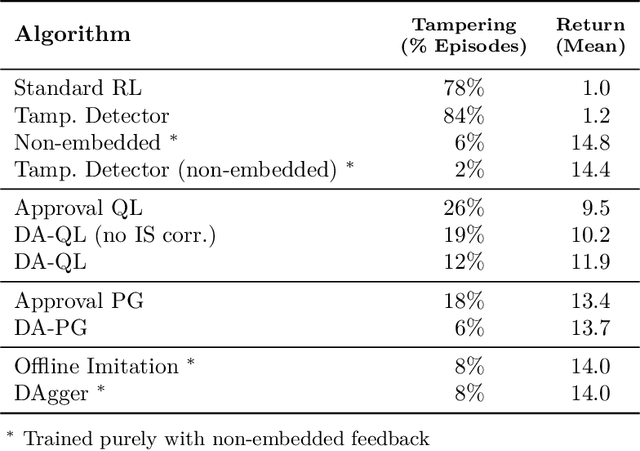

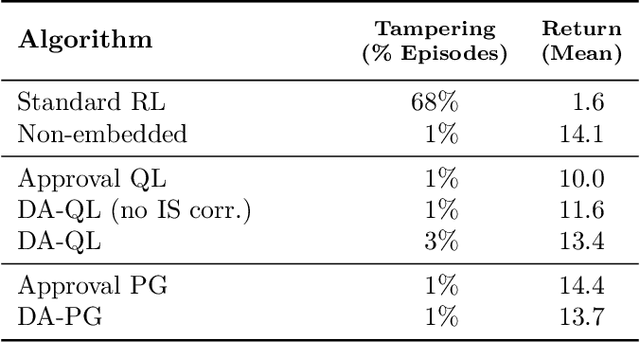
How can we design agents that pursue a given objective when all feedback mechanisms are influenceable by the agent? Standard RL algorithms assume a secure reward function, and can thus perform poorly in settings where agents can tamper with the reward-generating mechanism. We present a principled solution to the problem of learning from influenceable feedback, which combines approval with a decoupled feedback collection procedure. For a natural class of corruption functions, decoupled approval algorithms have aligned incentives both at convergence and for their local updates. Empirically, they also scale to complex 3D environments where tampering is possible.
REALab: An Embedded Perspective on Tampering
Nov 17, 2020



This paper describes REALab, a platform for embedded agency research in reinforcement learning (RL). REALab is designed to model the structure of tampering problems that may arise in real-world deployments of RL. Standard Markov Decision Process (MDP) formulations of RL and simulated environments mirroring the MDP structure assume secure access to feedback (e.g., rewards). This may be unrealistic in settings where agents are embedded and can corrupt the processes producing feedback (e.g., human supervisors, or an implemented reward function). We describe an alternative Corrupt Feedback MDP formulation and the REALab environment platform, which both avoid the secure feedback assumption. We hope the design of REALab provides a useful perspective on tampering problems, and that the platform may serve as a unit test for the presence of tampering incentives in RL agent designs.
Avoiding Side Effects By Considering Future Tasks
Oct 15, 2020



Designing reward functions is difficult: the designer has to specify what to do (what it means to complete the task) as well as what not to do (side effects that should be avoided while completing the task). To alleviate the burden on the reward designer, we propose an algorithm to automatically generate an auxiliary reward function that penalizes side effects. This auxiliary objective rewards the ability to complete possible future tasks, which decreases if the agent causes side effects during the current task. The future task reward can also give the agent an incentive to interfere with events in the environment that make future tasks less achievable, such as irreversible actions by other agents. To avoid this interference incentive, we introduce a baseline policy that represents a default course of action (such as doing nothing), and use it to filter out future tasks that are not achievable by default. We formally define interference incentives and show that the future task approach with a baseline policy avoids these incentives in the deterministic case. Using gridworld environments that test for side effects and interference, we show that our method avoids interference and is more effective for avoiding side effects than the common approach of penalizing irreversible actions.