 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Analysis of Agent Behavior for AI Safety
Mar 05, 2021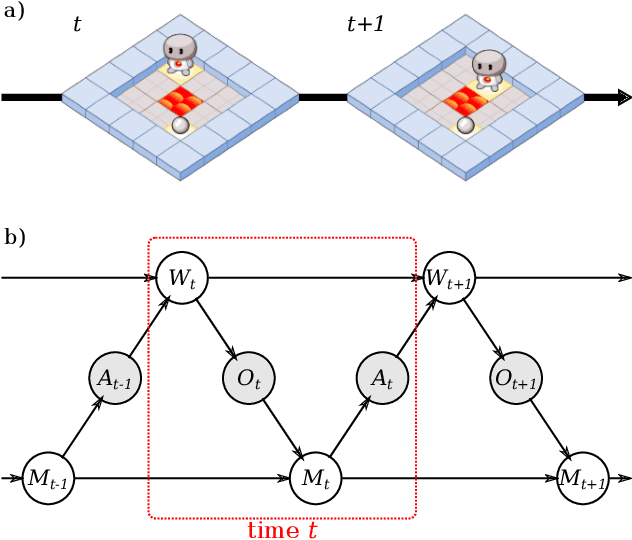
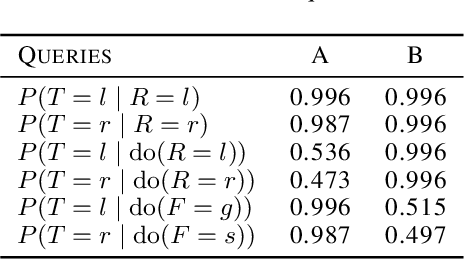
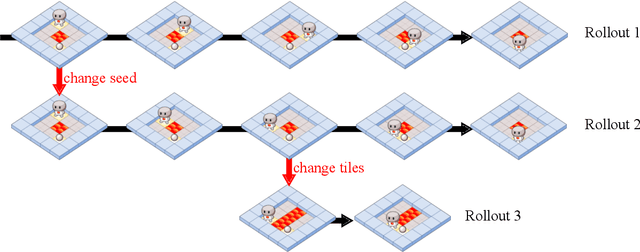

As machine learning systems become more powerful they also become increasingly unpredictable and opaque. Yet, finding human-understandable explanations of how they work is essential for their safe deployment. This technical report illustrates a methodology for investigating the causal mechanisms that drive the behaviour of artificial agents. Six use cases are covered, each addressing a typical question an analyst might ask about an agent. In particular, we show that each question cannot be addressed by pure observation alone, but instead requires conducting experiments with systematically chosen manipulations so as to generate the correct causal evidence.
Algorithms for Causal Reasoning in Probability Trees
Nov 12, 2020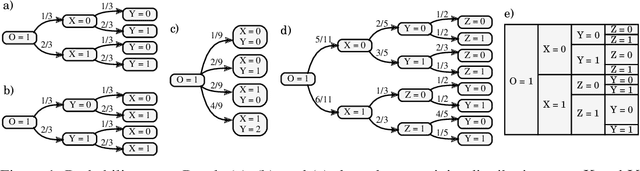
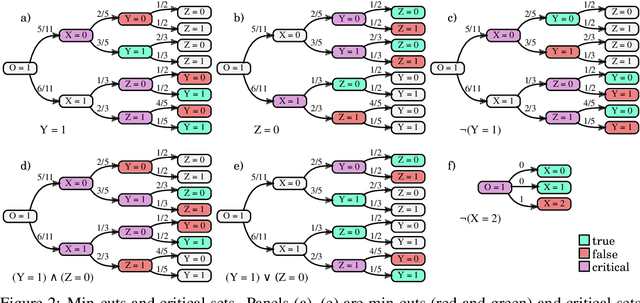


Probability trees are one of the simplest models of causal generative processes. They possess clean semantics and -- unlike causal Bayesian networks -- they can represent context-specific causal dependencies, which are necessary for e.g. causal induction. Yet, they have received little attention from the AI and ML community. Here we present concrete algorithms for causal reasoning in discrete probability trees that cover the entire causal hierarchy (association, intervention, and counterfactuals), and operate on arbitrary propositional and causal events. Our work expands the domain of causal reasoning to a very general class of discrete stochastic processes.
Meta-trained agents implement Bayes-optimal agents
Oct 21, 2020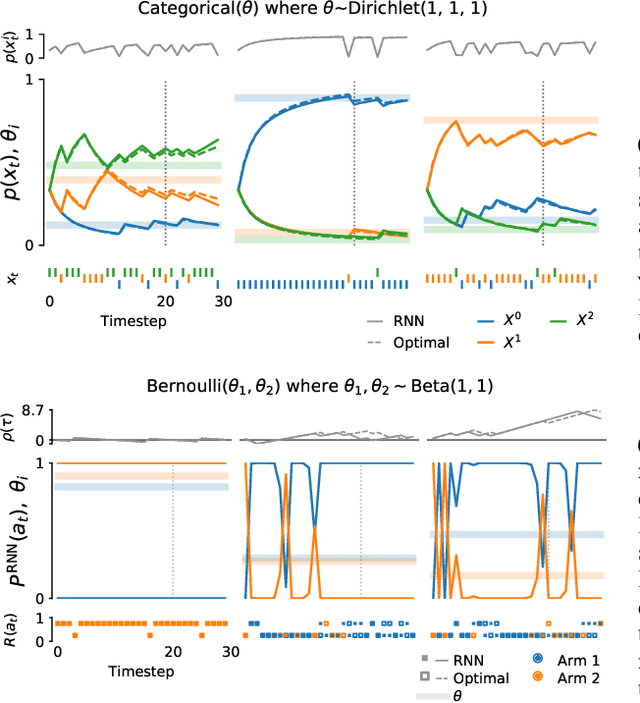

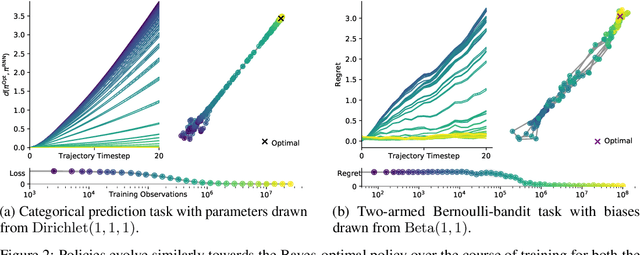
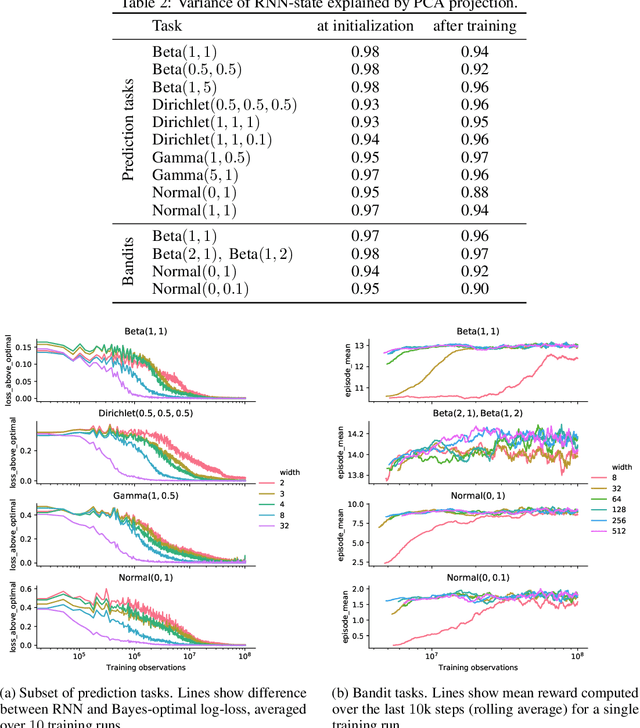
Memory-based meta-learning is a powerful technique to build agents that adapt fast to any task within a target distribution. A previous theoretical study has argued that this remarkable performance is because the meta-training protocol incentivises agents to behave Bayes-optimally. We empirically investigate this claim on a number of prediction and bandit tasks. Inspired by ideas from theoretical computer science, we show that meta-learned and Bayes-optimal agents not only behave alike, but they even share a similar computational structure, in the sense that one agent system can approximately simulate the other. Furthermore, we show that Bayes-optimal agents are fixed points of the meta-learning dynamics. Our results suggest that memory-based meta-learning might serve as a general technique for numerically approximating Bayes-optimal agents - that is, even for task distributions for which we currently don't possess tractable models.
Avoiding Side Effects By Considering Future Tasks
Oct 15, 2020



Designing reward functions is difficult: the designer has to specify what to do (what it means to complete the task) as well as what not to do (side effects that should be avoided while completing the task). To alleviate the burden on the reward designer, we propose an algorithm to automatically generate an auxiliary reward function that penalizes side effects. This auxiliary objective rewards the ability to complete possible future tasks, which decreases if the agent causes side effects during the current task. The future task reward can also give the agent an incentive to interfere with events in the environment that make future tasks less achievable, such as irreversible actions by other agents. To avoid this interference incentive, we introduce a baseline policy that represents a default course of action (such as doing nothing), and use it to filter out future tasks that are not achievable by default. We formally define interference incentives and show that the future task approach with a baseline policy avoids these incentives in the deterministic case. Using gridworld environments that test for side effects and interference, we show that our method avoids interference and is more effective for avoiding side effects than the common approach of penalizing irreversible actions.
Scaling shared model governance via model splitting
Dec 14, 2018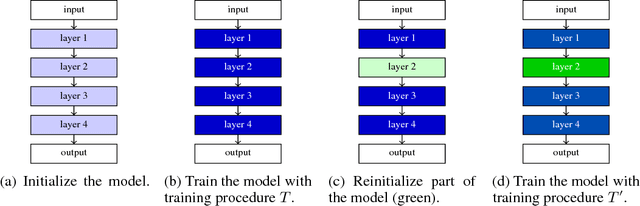



Currently the only techniques for sharing governance of a deep learning model are homomorphic encryption and secure multiparty computation. Unfortunately, neither of these techniques is applicable to the training of large neural networks due to their large computational and communication overheads. As a scalable technique for shared model governance, we propose splitting deep learning model between multiple parties. This paper empirically investigates the security guarantee of this technique, which is introduced as the problem of model completion: Given the entire training data set or an environment simulator, and a subset of the parameters of a trained deep learning model, how much training is required to recover the model's original performance? We define a metric for evaluating the hardness of the model completion problem and study it empirically in both supervised learning on ImageNet and reinforcement learning on Atari and DeepMind~Lab. Our experiments show that (1) the model completion problem is harder in reinforcement learning than in supervised learning because of the unavailability of the trained agent's trajectories, and (2) its hardness depends not primarily on the number of parameters of the missing part, but more so on their type and location. Our results suggest that model splitting might be a feasible technique for shared model governance in some settings where training is very expensive.
Scalable agent alignment via reward modeling: a research direction
Nov 19, 2018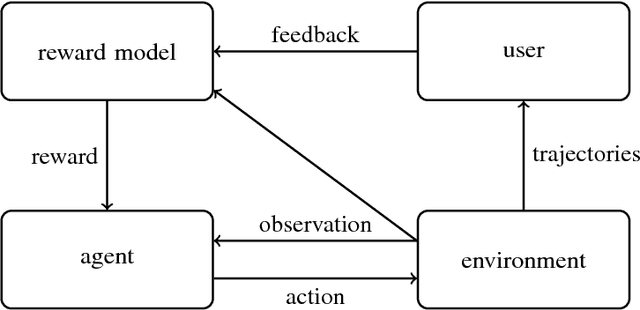
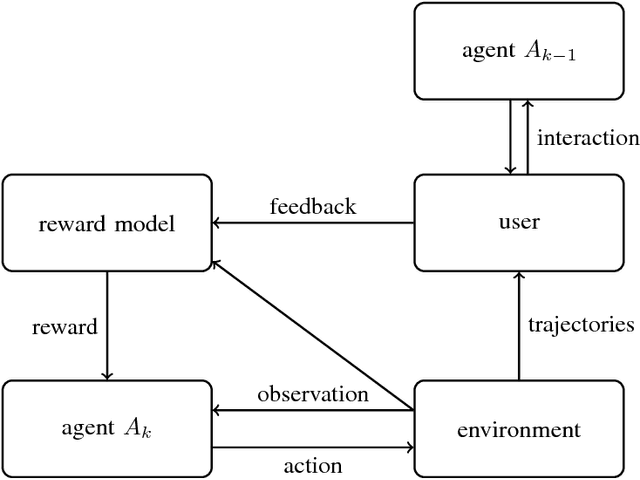

One obstacle to applying reinforcement learning algorithms to real-world problems is the lack of suitable reward functions. Designing such reward functions is difficult in part because the user only has an implicit understanding of the task objective. This gives rise to the agent alignment problem: how do we create agents that behave in accordance with the user's intentions? We outline a high-level research direction to solve the agent alignment problem centered around reward modeling: learning a reward function from interaction with the user and optimizing the learned reward function with reinforcement learning. We discuss the key challenges we expect to face when scaling reward modeling to complex and general domains, concrete approaches to mitigate these challenges, and ways to establish trust in the resulting agents.
Measuring and avoiding side effects using relative reachability
Jun 04, 2018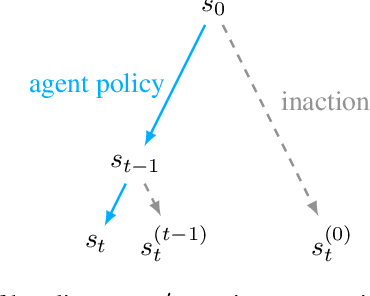
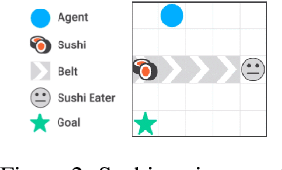
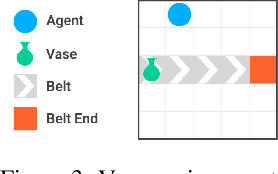
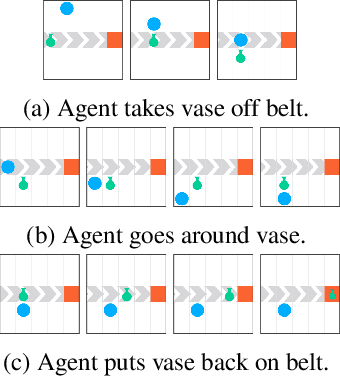
How can we design reinforcement learning agents that avoid causing unnecessary disruptions to their environment? We argue that current approaches to penalizing side effects can introduce bad incentives in tasks that require irreversible actions, and in environments that contain sources of change other than the agent. For example, some approaches give the agent an incentive to prevent any irreversible changes in the environment, including the actions of other agents. We introduce a general definition of side effects, based on relative reachability of states compared to a default state, that avoids these undesirable incentives. Using a set of gridworld experiments illustrating relevant scenarios, we empirically compare relative reachability to penalties based on existing definitions and show that it is the only penalty among those tested that produces the desired behavior in all the scenarios.
AI Safety Gridworlds
Nov 28, 2017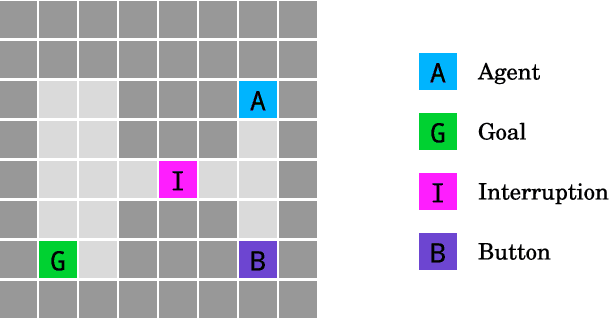
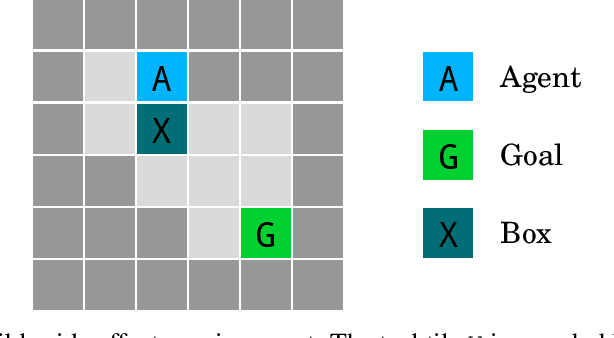
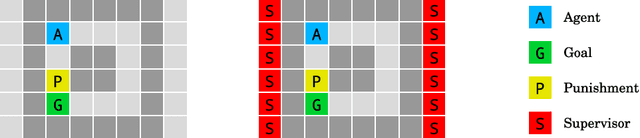
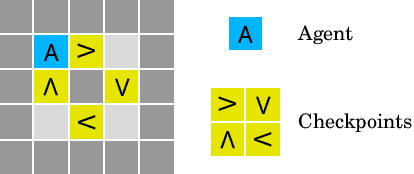
We present a suite of reinforcement learning environments illustrating various safety properties of intelligent agents. These problems include safe interruptibility, avoiding side effects, absent supervisor, reward gaming, safe exploration, as well as robustness to self-modification, distributional shift, and adversaries. To measure compliance with the intended safe behavior, we equip each environment with a performance function that is hidden from the agent. This allows us to categorize AI safety problems into robustness and specification problems, depending on whether the performance function corresponds to the observed reward function. We evaluate A2C and Rainbow, two recent deep reinforcement learning agents, on our environments and show that they are not able to solve them satisfactorily.
Deep reinforcement learning from human preferences
Jul 13, 2017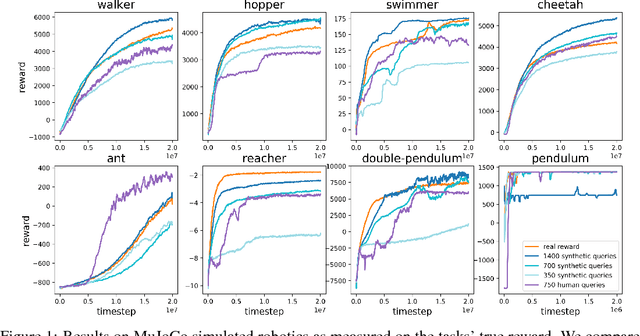
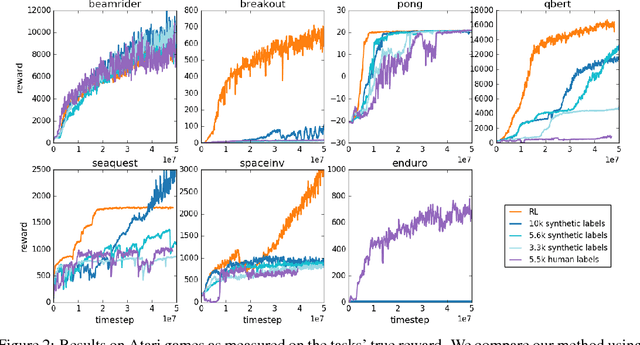
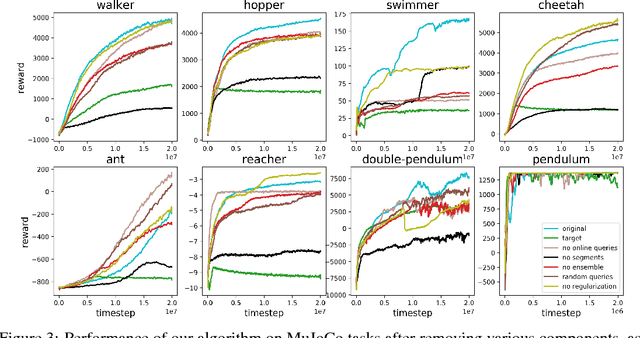
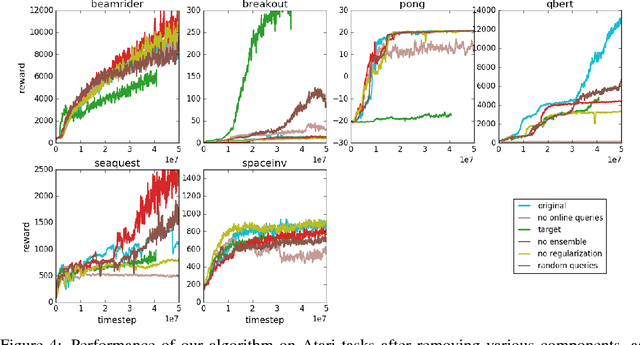
For sophisticated reinforcement learning (RL) systems to interact usefully with real-world environments, we need to communicate complex goals to these systems. In this work, we explore goals defined in terms of (non-expert) human preferences between pairs of trajectory segments. We show that this approach can effectively solve complex RL tasks without access to the reward function, including Atari games and simulated robot locomotion, while providing feedback on less than one percent of our agent's interactions with the environment. This reduces the cost of human oversight far enough that it can be practically applied to state-of-the-art RL systems. To demonstrate the flexibility of our approach, we show that we can successfully train complex novel behaviors with about an hour of human time. These behaviors and environments are considerably more complex than any that have been previously learned from human feedback.