 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Sentiment Bias in Language Models via Counterfactual Evaluation
Nov 08, 2019

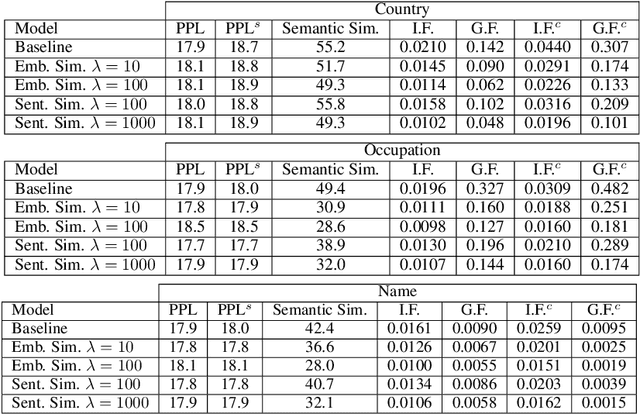
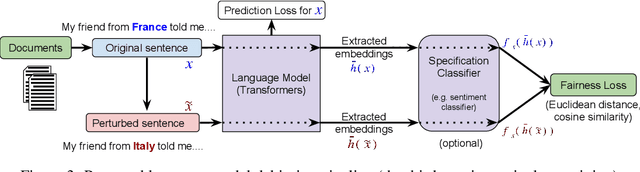
Recent improvements in large-scale language models have driven progress on automatic generation of syntactically and semantically consistent text for many real-world applications. Many of these advances leverage the availability of large corpora. While training on such corpora encourages the model to understand long-range dependencies in text, it can also result in the models internalizing the social biases present in the corpora. This paper aims to quantify and reduce biases exhibited by language models. Given a conditioning context (e.g. a writing prompt) and a language model, we analyze if (and how) the sentiment of the generated text is affected by changes in values of sensitive attributes (e.g. country names, occupations, genders, etc.) in the conditioning context, a.k.a. counterfactual evaluation. We quantify these biases by adapting individual and group fairness metrics from the fair machine learning literature. Extensive evaluation on two different corpora (news articles and Wikipedia) shows that state-of-the-art Transformer-based language models exhibit biases learned from data. We propose embedding-similarity and sentiment-similarity regularization methods that improve both individual and group fairness metrics without sacrificing perplexity and semantic similarity---a positive step toward development and deployment of fairer language models for real-world applications.
Scalable agent alignment via reward modeling: a research direction
Nov 19, 2018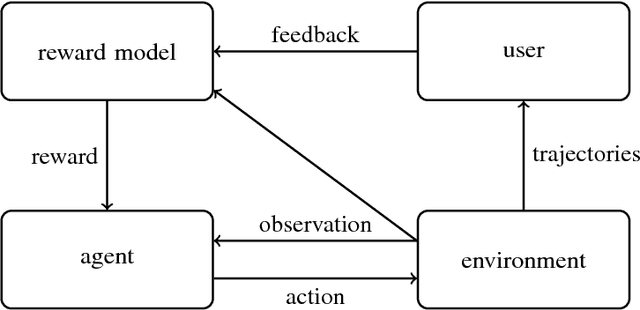
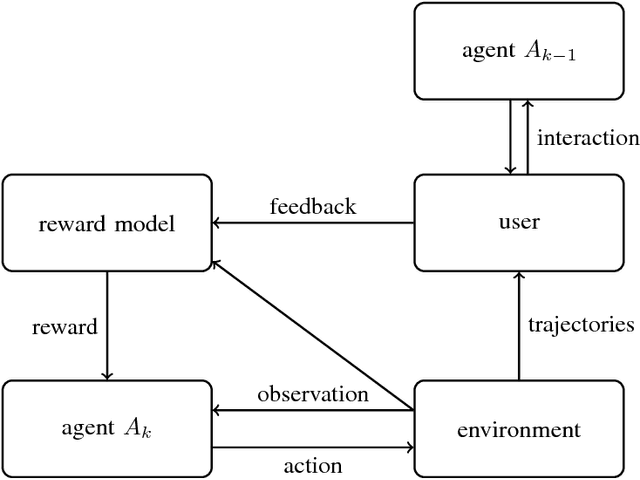

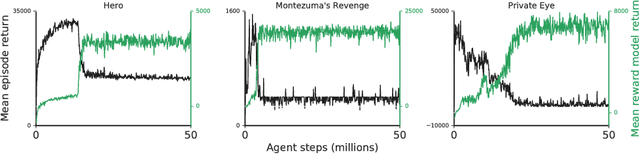
One obstacle to applying reinforcement learning algorithms to real-world problems is the lack of suitable reward functions. Designing such reward functions is difficult in part because the user only has an implicit understanding of the task objective. This gives rise to the agent alignment problem: how do we create agents that behave in accordance with the user's intentions? We outline a high-level research direction to solve the agent alignment problem centered around reward modeling: learning a reward function from interaction with the user and optimizing the learned reward function with reinforcement learning. We discuss the key challenges we expect to face when scaling reward modeling to complex and general domains, concrete approaches to mitigate these challenges, and ways to establish trust in the resulting agents.