 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaStar Unplugged: Large-Scale Offline Reinforcement Learning
Aug 07, 2023



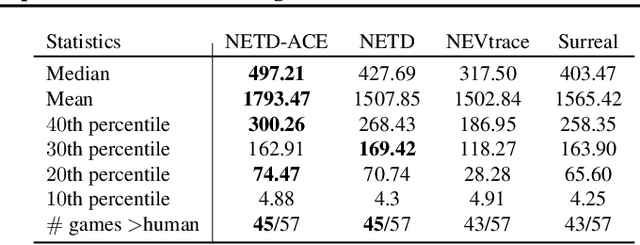
StarCraft II is one of the most challenging simulated reinforcement learning environments; it is partially observable, stochastic, multi-agent, and mastering StarCraft II requires strategic planning over long time horizons with real-time low-level execution. It also has an active professional competitive scene. StarCraft II is uniquely suited for advancing offline RL algorithms, both because of its challenging nature and because Blizzard has released a massive dataset of millions of StarCraft II games played by human players. This paper leverages that and establishes a benchmark, called AlphaStar Unplugged, introducing unprecedented challenges for offline reinforcement learning. We define a dataset (a subset of Blizzard's release), tools standardizing an API for machine learning methods, and an evaluation protocol. We also present baseline agents, including behavior cloning, offline variants of actor-critic and MuZero. We improve the state of the art of agents using only offline data, and we achieve 90% win rate against previously published AlphaStar behavior cloning agent.
Scaling Goal-based Exploration via Pruning Proto-goals
Feb 09, 2023



One of the gnarliest challenges in reinforcement learning (RL) is exploration that scales to vast domains, where novelty-, or coverage-seeking behaviour falls short. Goal-directed, purposeful behaviours are able to overcome this, but rely on a good goal space. The core challenge in goal discovery is finding the right balance between generality (not hand-crafted) and tractability (useful, not too many). Our approach explicitly seeks the middle ground, enabling the human designer to specify a vast but meaningful proto-goal space, and an autonomous discovery process to refine this to a narrower space of controllable, reachable, novel, and relevant goals. The effectiveness of goal-conditioned exploration with the latter is then demonstrated in three challenging environments.
Human-level Atari 200x faster
Sep 15, 2022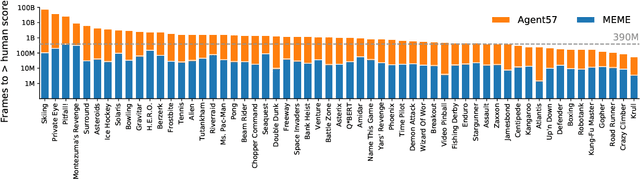
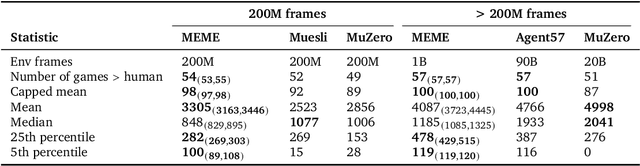
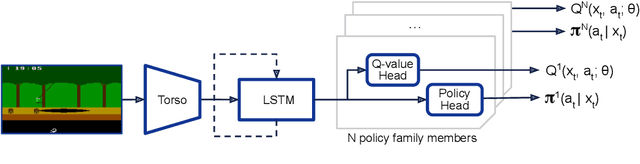

The task of building general agents that perform well over a wide range of tasks has been an important goal in reinforcement learning since its inception. The problem has been subject of research of a large body of work, with performance frequently measured by observing scores over the wide range of environments contained in the Atari 57 benchmark. Agent57 was the first agent to surpass the human benchmark on all 57 games, but this came at the cost of poor data-efficiency, requiring nearly 80 billion frames of experience to achieve. Taking Agent57 as a starting point, we employ a diverse set of strategies to achieve a 200-fold reduction of experience needed to out perform the human baseline. We investigate a range of instabilities and bottlenecks we encountered while reducing the data regime, and propose effective solutions to build a more robust and efficient agent. We also demonstrate competitive performance with high-performing methods such as Muesli and MuZero. The four key components to our approach are (1) an approximate trust region method which enables stable bootstrapping from the online network, (2) a normalisation scheme for the loss and priorities which improves robustness when learning a set of value functions with a wide range of scales, (3) an improved architecture employing techniques from NFNets in order to leverage deeper networks without the need for normalization layers, and (4) a policy distillation method which serves to smooth out the instantaneous greedy policy overtime.
Learning Expected Emphatic Traces for Deep RL
Jul 12, 2021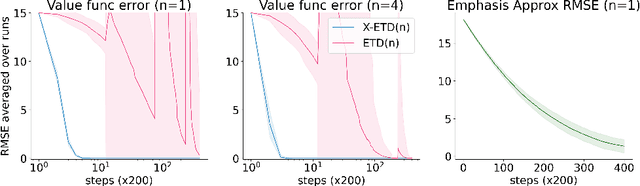

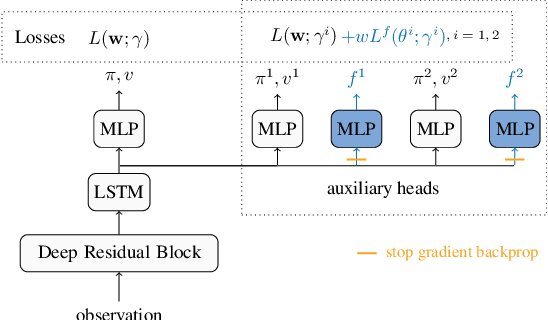
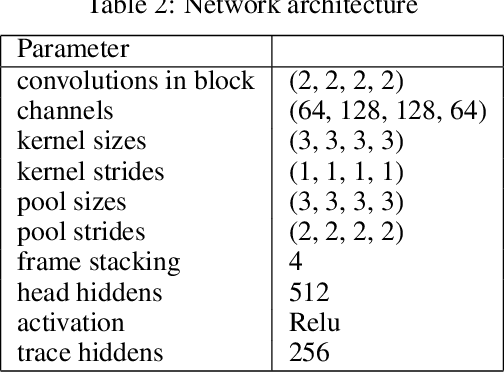
Off-policy sampling and experience replay are key for improving sample efficiency and scaling model-free temporal difference learning methods. When combined with function approximation, such as neural networks, this combination is known as the deadly triad and is potentially unstable. Recently, it has been shown that stability and good performance at scale can be achieved by combining emphatic weightings and multi-step updates. This approach, however, is generally limited to sampling complete trajectories in order, to compute the required emphatic weighting. In this paper we investigate how to combine emphatic weightings with non-sequential, off-line data sampled from a replay buffer. We develop a multi-step emphatic weighting that can be combined with replay, and a time-reversed $n$-step TD learning algorithm to learn the required emphatic weighting. We show that these state weightings reduce variance compared with prior approaches, while providing convergence guarantees. We tested the approach at scale on Atari 2600 video games, and observed that the new X-ETD($n$) agent improved over baseline agents, highlighting both the scalability and broad applicability of our approach.
Emphatic Algorithms for Deep Reinforcement Learning
Jun 21, 2021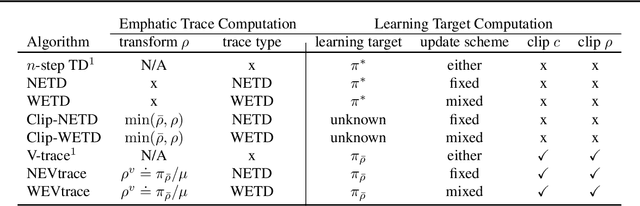
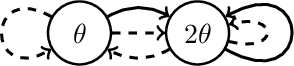
Off-policy learning allows us to learn about possible policies of behavior from experience generated by a different behavior policy. Temporal difference (TD) learning algorithms can become unstable when combined with function approximation and off-policy sampling - this is known as the ''deadly triad''. Emphatic temporal difference (ETD($\lambda$)) algorithm ensures convergence in the linear case by appropriately weighting the TD($\lambda$) updates. In this paper, we extend the use of emphatic methods to deep reinforcement learning agents. We show that naively adapting ETD($\lambda$) to popular deep reinforcement learning algorithms, which use forward view multi-step returns, results in poor performance. We then derive new emphatic algorithms for use in the context of such algorithms, and we demonstrate that they provide noticeable benefits in small problems designed to highlight the instability of TD methods. Finally, we observed improved performance when applying these algorithms at scale on classic Atari games from the Arcade Learning Environment.
Causally Correct Partial Models for Reinforcement Learning
Feb 07, 2020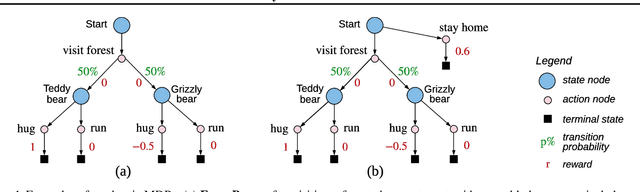


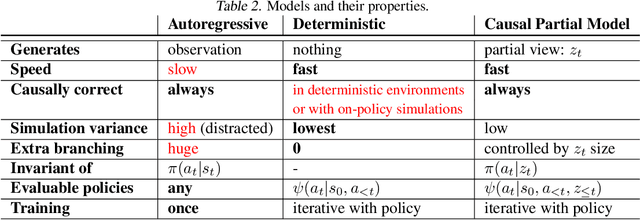
In reinforcement learning, we can learn a model of future observations and rewards, and use it to plan the agent's next actions. However, jointly modeling future observations can be computationally expensive or even intractable if the observations are high-dimensional (e.g. images). For this reason, previous works have considered partial models, which model only part of the observation. In this paper, we show that partial models can be causally incorrect: they are confounded by the observations they don't model, and can therefore lead to incorrect planning. To address this, we introduce a general family of partial models that are provably causally correct, yet remain fast because they do not need to fully model future observations.
Reducing Sentiment Bias in Language Models via Counterfactual Evaluation
Nov 08, 2019

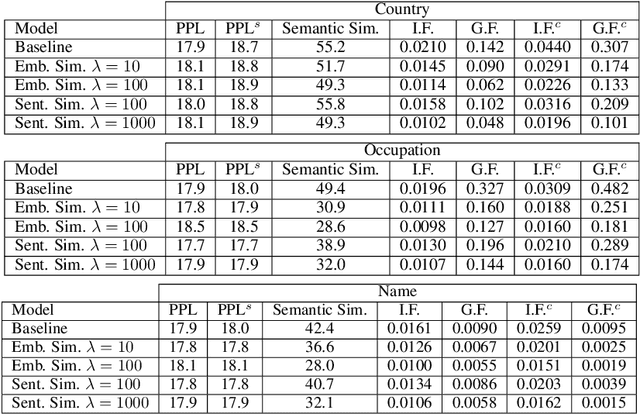
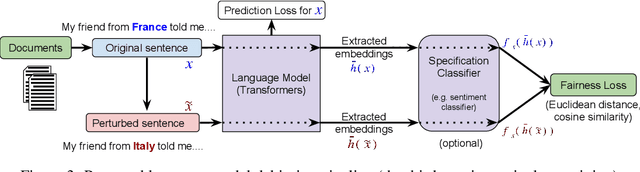
Recent improvements in large-scale language models have driven progress on automatic generation of syntactically and semantically consistent text for many real-world applications. Many of these advances leverage the availability of large corpora. While training on such corpora encourages the model to understand long-range dependencies in text, it can also result in the models internalizing the social biases present in the corpora. This paper aims to quantify and reduce biases exhibited by language models. Given a conditioning context (e.g. a writing prompt) and a language model, we analyze if (and how) the sentiment of the generated text is affected by changes in values of sensitive attributes (e.g. country names, occupations, genders, etc.) in the conditioning context, a.k.a. counterfactual evaluation. We quantify these biases by adapting individual and group fairness metrics from the fair machine learning literature. Extensive evaluation on two different corpora (news articles and Wikipedia) shows that state-of-the-art Transformer-based language models exhibit biases learned from data. We propose embedding-similarity and sentiment-similarity regularization methods that improve both individual and group fairness metrics without sacrificing perplexity and semantic similarity---a positive step toward development and deployment of fairer language models for real-world applications.
Wasserstein Fair Classification
Jul 28, 2019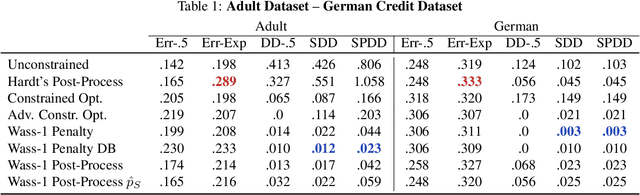
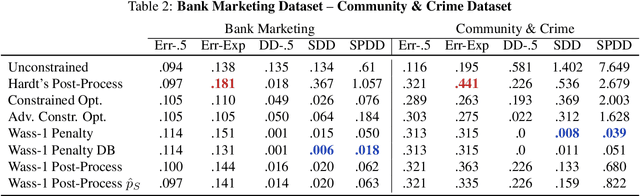
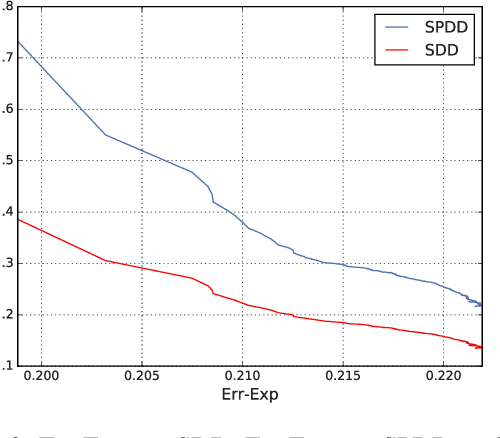
We propose an approach to fair classification that enforces independence between the classifier outputs and sensitive information by minimizing Wasserstein-1 distances. The approach has desirable theoretical properties and is robust to specific choices of the threshold used to obtain class predictions from model outputs. We introduce different methods that enable hiding sensitive information at test time or have a simple and fast implementation. We show empirical performance against different fairness baselines on several benchmark fairness datasets.
Degenerate Feedback Loops in Recommender Systems
Mar 27, 2019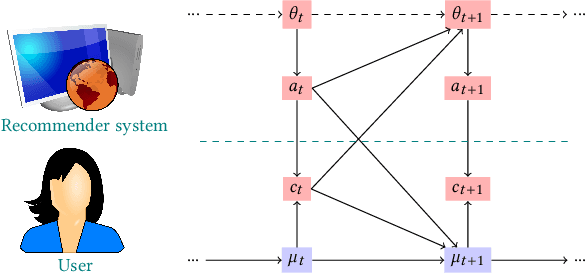
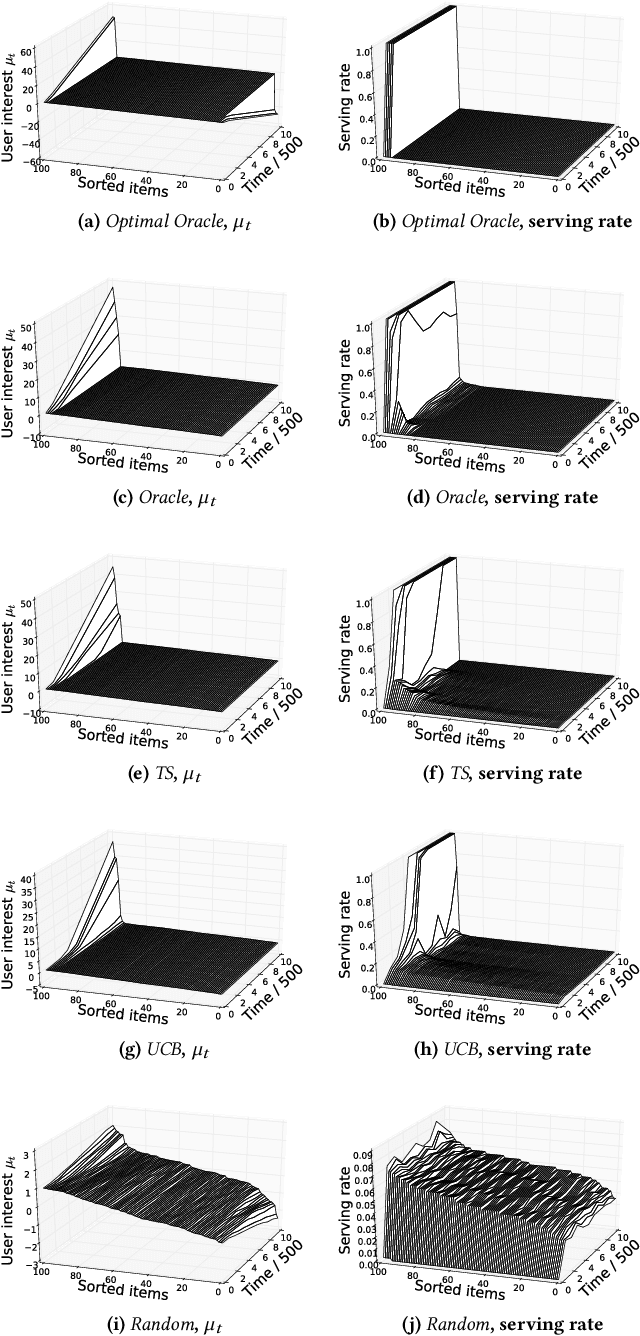
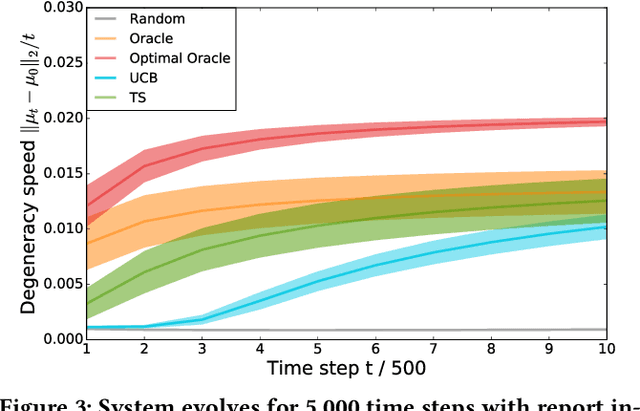
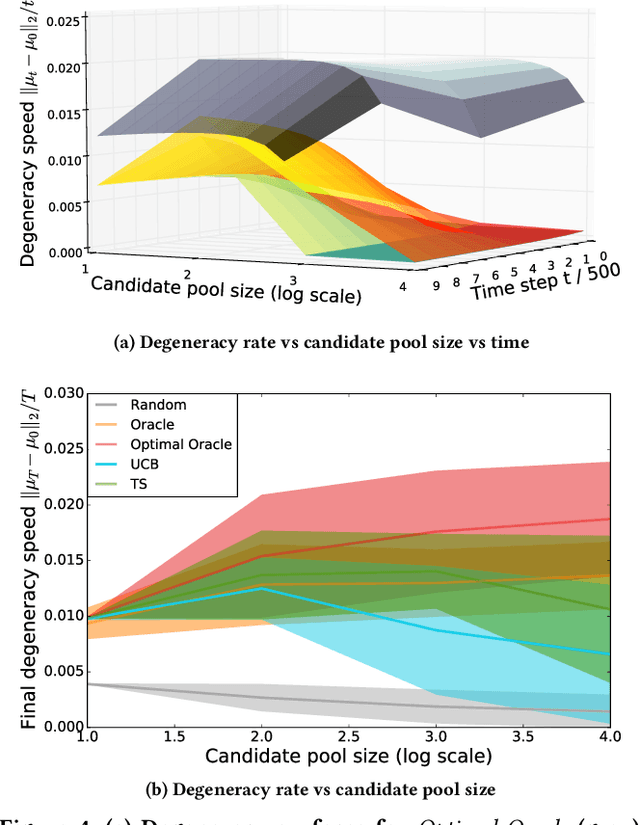
Machine learning is used extensively in recommender systems deployed in products. The decisions made by these systems can influence user beliefs and preferences which in turn affect the feedback the learning system receives - thus creating a feedback loop. This phenomenon can give rise to the so-called "echo chambers" or "filter bubbles" that have user and societal implications. In this paper, we provide a novel theoretical analysis that examines both the role of user dynamics and the behavior of recommender systems, disentangling the echo chamber from the filter bubble effect. In addition, we offer practical solutions to slow down system degeneracy. Our study contributes toward understanding and developing solutions to commonly cited issues in the complex temporal scenario, an area that is still largely unexplored.
Learning from Delayed Outcomes with Intermediate Observations
Jul 24, 2018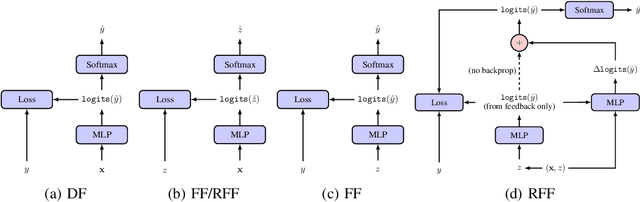

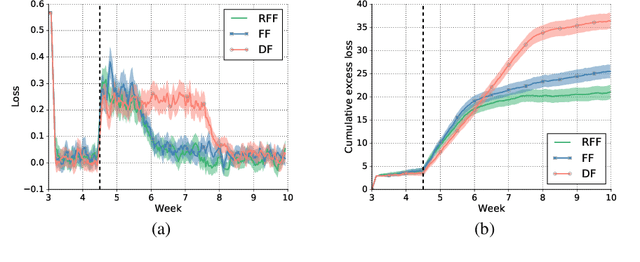
Optimizing for long term value is desirable in many practical applications, e.g. recommender systems. The most common approach for long term value optimization is supervised learning using long term value as the target. Unfortunately, long term metrics take a long time to measure (e.g., will customers finish reading an ebook?), and vanilla forecasters cannot learn from examples until the outcome is observed. In practical systems where new items arrive frequently, such delay can increase the training-serving skew, thereby negatively affecting the model's predictions for new products. We argue that intermediate observations (e.g., if customers read a third of the book in 24 hours) can improve a model's predictions. We formalize the problem as a semi-stochastic model, where instances are selected by an adversary but, given an instance, the intermediate observation and the outcome are sampled from a factored joint distribution. We propose an algorithm that exploits intermediate observations and theoretically quantify how much it can outperform any prediction method that ignores the intermediate observations. Motivated by the theoretical analysis, we propose two neural network architectures: Factored Forecaster (FF) which is ideal if our assumptions are satisfied, and Residual Factored Forecaster (RFF) that is more robust to model mis-specification. Experiments on two real world datasets, a dataset derived from GitHub repositories and another dataset from a popular marketplace, show that RFF outperforms both FF as well as an algorithm that ignores intermediate observations.