 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft-Robust Actor-Critic Policy-Gradient
Oct 24, 2018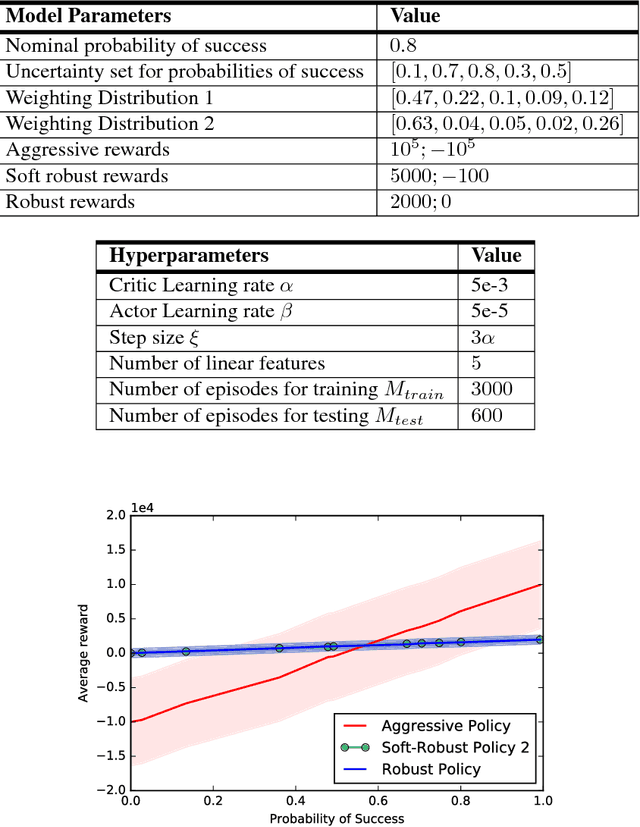
Robust Reinforcement Learning aims to derive optimal behavior that accounts for model uncertainty in dynamical systems. However, previous studies have shown that by considering the worst case scenario, robust policies can be overly conservative. Our soft-robust framework is an attempt to overcome this issue. In this paper, we present a novel Soft-Robust Actor-Critic algorithm (SR-AC). It learns an optimal policy with respect to a distribution over an uncertainty set and stays robust to model uncertainty but avoids the conservativeness of robust strategies. We show the convergence of SR-AC and test the efficiency of our approach on different domains by comparing it against regular learning methods and their robust formulations.
Learning from Delayed Outcomes with Intermediate Observations
Jul 24, 2018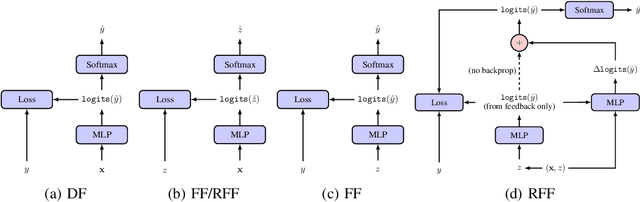

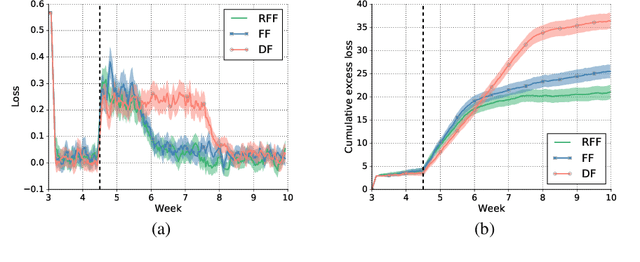
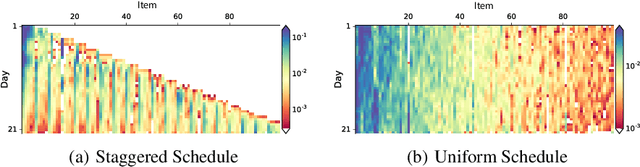
Optimizing for long term value is desirable in many practical applications, e.g. recommender systems. The most common approach for long term value optimization is supervised learning using long term value as the target. Unfortunately, long term metrics take a long time to measure (e.g., will customers finish reading an ebook?), and vanilla forecasters cannot learn from examples until the outcome is observed. In practical systems where new items arrive frequently, such delay can increase the training-serving skew, thereby negatively affecting the model's predictions for new products. We argue that intermediate observations (e.g., if customers read a third of the book in 24 hours) can improve a model's predictions. We formalize the problem as a semi-stochastic model, where instances are selected by an adversary but, given an instance, the intermediate observation and the outcome are sampled from a factored joint distribution. We propose an algorithm that exploits intermediate observations and theoretically quantify how much it can outperform any prediction method that ignores the intermediate observations. Motivated by the theoretical analysis, we propose two neural network architectures: Factored Forecaster (FF) which is ideal if our assumptions are satisfied, and Residual Factored Forecaster (RFF) that is more robust to model mis-specification. Experiments on two real world datasets, a dataset derived from GitHub repositories and another dataset from a popular marketplace, show that RFF outperforms both FF as well as an algorithm that ignores intermediate observations.
Beyond Greedy Ranking: Slate Optimization via List-CVAE
May 24, 2018
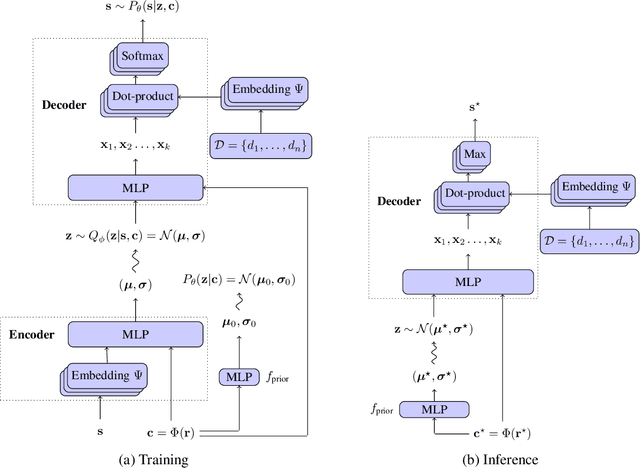
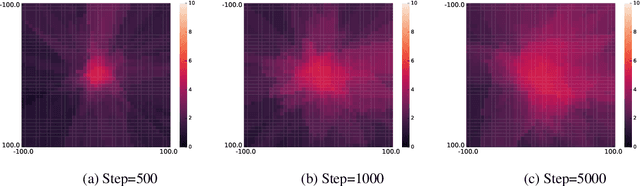
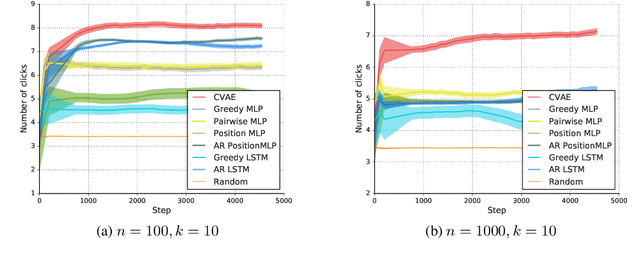
The conventional approach to solving the recommendation problem is through greedy ranking by prediction scores for individual document candidates. However these methods fail to optimize the slate as a whole, and often struggle at capturing biases caused by the page layout and interdependencies between documents. The slate recommendation problem aims to find the optimal, ordered subset of documents, a.k.a. slate, given the page layout to serve users recommendations. Solving this problem is hard due to combinatorial explosion of document candidates and their display positions on the page. In this paper, we introduce List Conditional Variational Auto-Encoders (List-CVAE) to learn the joint distribution of documents on the slate conditional on user responses, and directly generate slates. Experiments on simulated and real-world data show that List-CVAE outperforms greedy ranking methods consistently on various scales of documents corpora.
Learning Robust Options
Feb 09, 2018
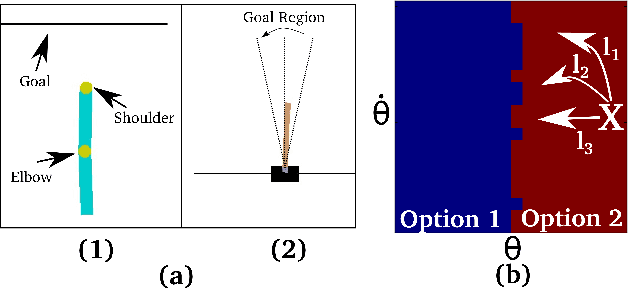
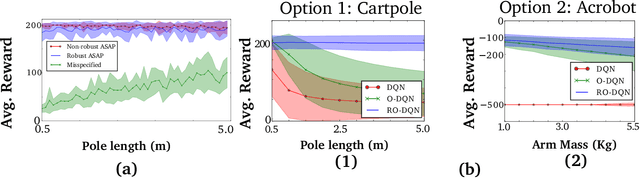
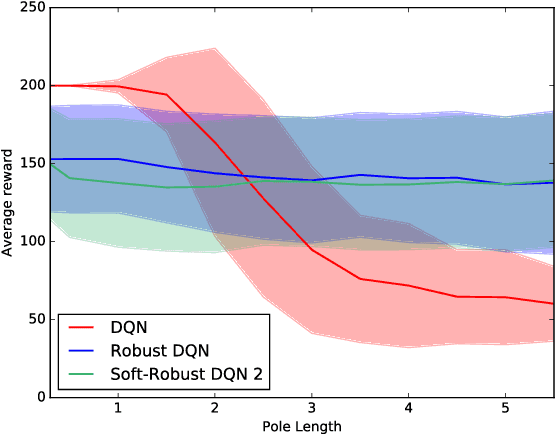
Robust reinforcement learning aims to produce policies that have strong guarantees even in the face of environments/transition models whose parameters have strong uncertainty. Existing work uses value-based methods and the usual primitive action setting. In this paper, we propose robust methods for learning temporally abstract actions, in the framework of options. We present a Robust Options Policy Iteration (ROPI) algorithm with convergence guarantees, which learns options that are robust to model uncertainty. We utilize ROPI to learn robust options with the Robust Options Deep Q Network (RO-DQN) that solves multiple tasks and mitigates model misspecification due to model uncertainty. We present experimental results which suggest that policy iteration with linear features may have an inherent form of robustness when using coarse feature representations. In addition, we present experimental results which demonstrate that robustness helps policy iteration implemented on top of deep neural networks to generalize over a much broader range of dynamics than non-robust policy iteration.
Adaptive Lambda Least-Squares Temporal Difference Learning
Dec 30, 2016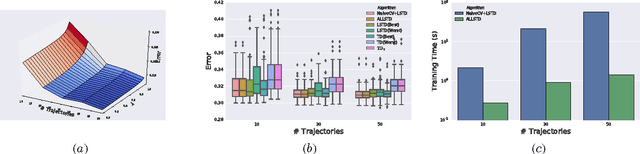
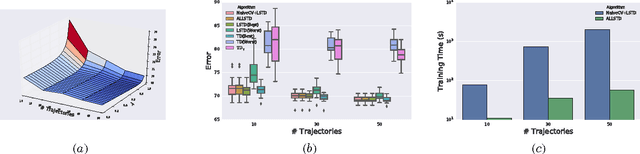
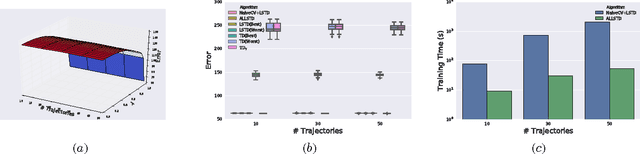
Temporal Difference learning or TD($\lambda$) is a fundamental algorithm in the field of reinforcement learning. However, setting TD's $\lambda$ parameter, which controls the timescale of TD updates, is generally left up to the practitioner. We formalize the $\lambda$ selection problem as a bias-variance trade-off where the solution is the value of $\lambda$ that leads to the smallest Mean Squared Value Error (MSVE). To solve this trade-off we suggest applying Leave-One-Trajectory-Out Cross-Validation (LOTO-CV) to search the space of $\lambda$ values. Unfortunately, this approach is too computationally expensive for most practical applications. For Least Squares TD (LSTD) we show that LOTO-CV can be implemented efficiently to automatically tune $\lambda$ and apply function optimization methods to efficiently search the space of $\lambda$ values. The resulting algorithm, ALLSTD, is parameter free and our experiments demonstrate that ALLSTD is significantly computationally faster than the na\"{i}ve LOTO-CV implementation while achieving similar performance.
Iterative Hierarchical Optimization for Misspecified Problems (IHOMP)
Jun 07, 2016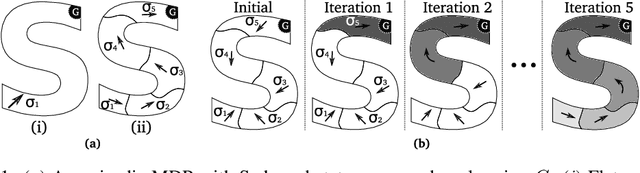
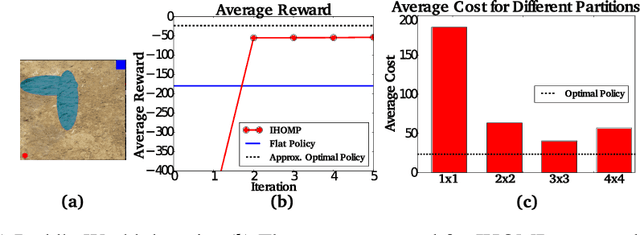
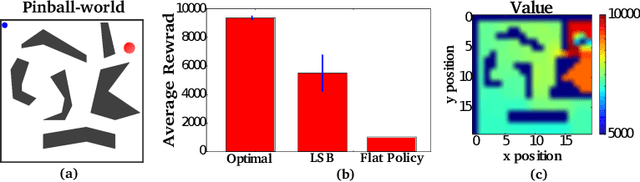
For complex, high-dimensional Markov Decision Processes (MDPs), it may be necessary to represent the policy with function approximation. A problem is misspecified whenever, the representation cannot express any policy with acceptable performance. We introduce IHOMP : an approach for solving misspecified problems. IHOMP iteratively learns a set of context specialized options and combines these options to solve an otherwise misspecified problem. Our main contribution is proving that IHOMP enjoys theoretical convergence guarantees. In addition, we extend IHOMP to exploit Option Interruption (OI) enabling it to decide where the learned options can be reused. Our experiments demonstrate that IHOMP can find near-optimal solutions to otherwise misspecified problems and that OI can further improve the solutions.
Adaptive Skills, Adaptive Partitions (ASAP)
Jun 07, 2016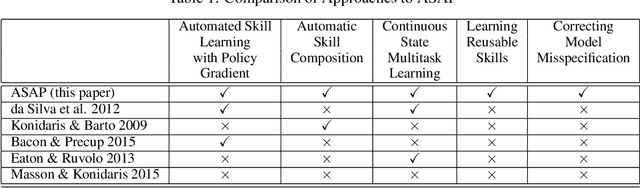
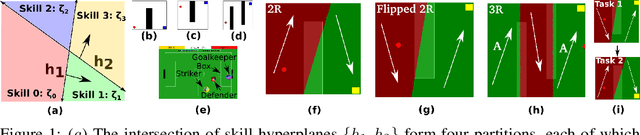
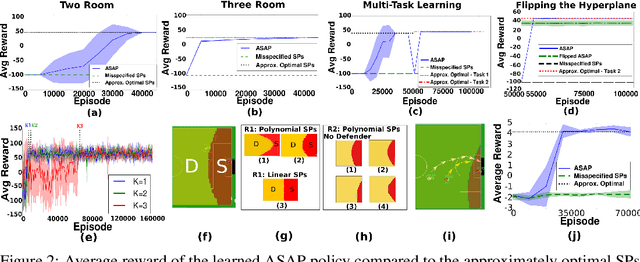
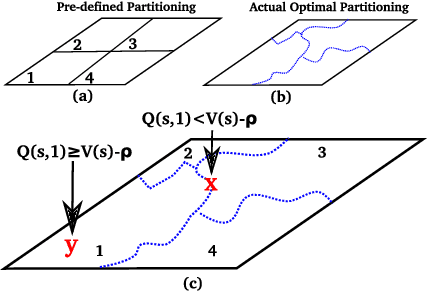
We introduce the Adaptive Skills, Adaptive Partitions (ASAP) framework that (1) learns skills (i.e., temporally extended actions or options) as well as (2) where to apply them. We believe that both (1) and (2) are necessary for a truly general skill learning framework, which is a key building block needed to scale up to lifelong learning agents. The ASAP framework can also solve related new tasks simply by adapting where it applies its existing learned skills. We prove that ASAP converges to a local optimum under natural conditions. Finally, our experimental results, which include a RoboCup domain, demonstrate the ability of ASAP to learn where to reuse skills as well as solve multiple tasks with considerably less experience than solving each task from scratch.
Bootstrapping Skills
Jun 11, 2015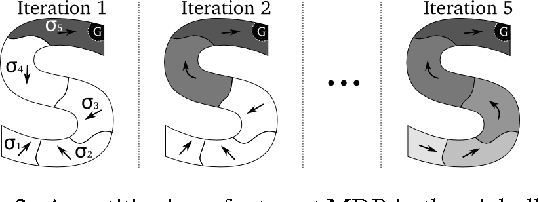
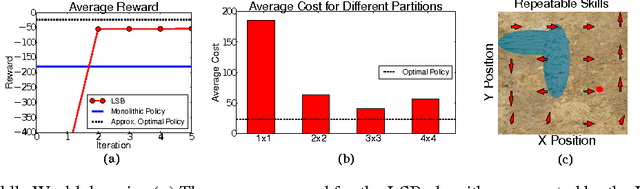

The monolithic approach to policy representation in Markov Decision Processes (MDPs) looks for a single policy that can be represented as a function from states to actions. For the monolithic approach to succeed (and this is not always possible), a complex feature representation is often necessary since the policy is a complex object that has to prescribe what actions to take all over the state space. This is especially true in large domains with complicated dynamics. It is also computationally inefficient to both learn and plan in MDPs using a complex monolithic approach. We present a different approach where we restrict the policy space to policies that can be represented as combinations of simpler, parameterized skills---a type of temporally extended action, with a simple policy representation. We introduce Learning Skills via Bootstrapping (LSB) that can use a broad family of Reinforcement Learning (RL) algorithms as a "black box" to iteratively learn parametrized skills. Initially, the learned skills are short-sighted but each iteration of the algorithm allows the skills to bootstrap off one another, improving each skill in the process. We prove that this bootstrapping process returns a near-optimal policy. Furthermore, our experiments demonstrate that LSB can solve MDPs that, given the same representational power, could not be solved by a monolithic approach. Thus, planning with learned skills results in better policies without requiring complex policy representations.
Actively Learning to Attract Followers on Twitter
Apr 16, 2015
Twitter, a popular social network, presents great opportunities for on-line machine learning research. However, previous research has focused almost entirely on learning from passively collected data. We study the problem of learning to acquire followers through normative user behavior, as opposed to the mass following policies applied by many bots. We formalize the problem as a contextual bandit problem, in which we consider retweeting content to be the action chosen and each tweet (content) is accompanied by context. We design reward signals based on the change in followers. The result of our month long experiment with 60 agents suggests that (1) aggregating experience across agents can adversely impact prediction accuracy and (2) the Twitter community's response to different actions is non-stationary. Our findings suggest that actively learning on-line can provide deeper insights about how to attract followers than machine learning over passively collected data alone.