 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Lambda Least-Squares Temporal Difference Learning
Paper and Code
Dec 30, 2016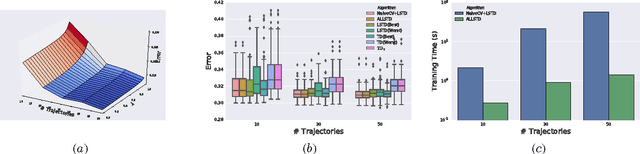
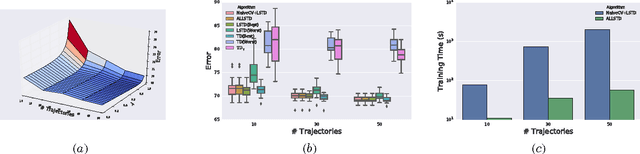
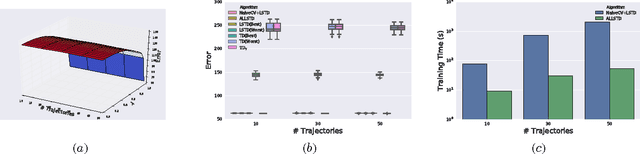
Temporal Difference learning or TD($\lambda$) is a fundamental algorithm in the field of reinforcement learning. However, setting TD's $\lambda$ parameter, which controls the timescale of TD updates, is generally left up to the practitioner. We formalize the $\lambda$ selection problem as a bias-variance trade-off where the solution is the value of $\lambda$ that leads to the smallest Mean Squared Value Error (MSVE). To solve this trade-off we suggest applying Leave-One-Trajectory-Out Cross-Validation (LOTO-CV) to search the space of $\lambda$ values. Unfortunately, this approach is too computationally expensive for most practical applications. For Least Squares TD (LSTD) we show that LOTO-CV can be implemented efficiently to automatically tune $\lambda$ and apply function optimization methods to efficiently search the space of $\lambda$ values. The resulting algorithm, ALLSTD, is parameter free and our experiments demonstrate that ALLSTD is significantly computationally faster than the na\"{i}ve LOTO-CV implementation while achieving similar performance.