 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Human-level Atari 200x faster
Sep 15, 2022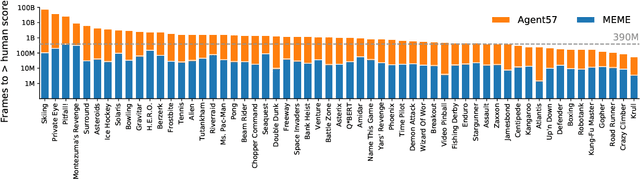
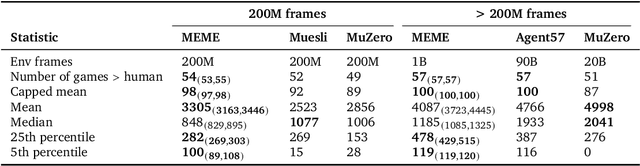
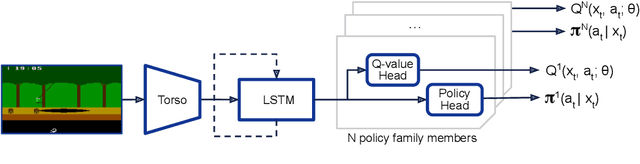

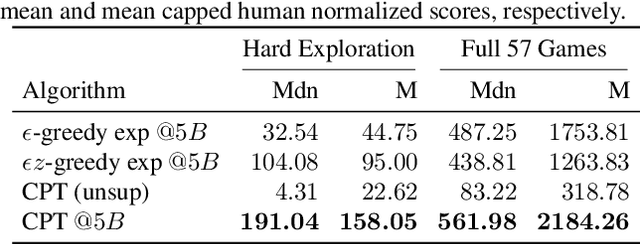
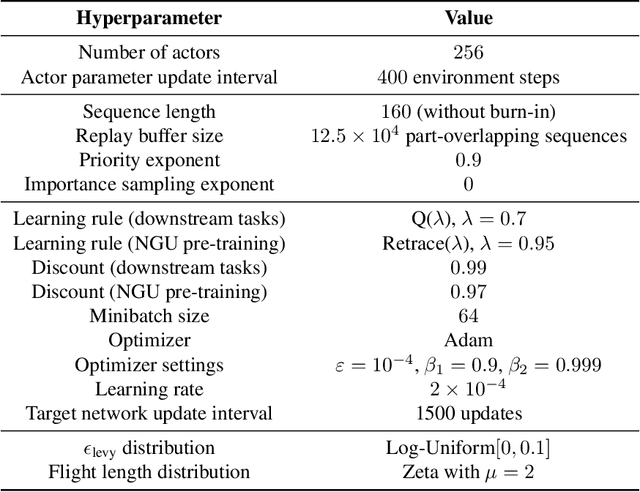
The task of building general agents that perform well over a wide range of tasks has been an important goal in reinforcement learning since its inception. The problem has been subject of research of a large body of work, with performance frequently measured by observing scores over the wide range of environments contained in the Atari 57 benchmark. Agent57 was the first agent to surpass the human benchmark on all 57 games, but this came at the cost of poor data-efficiency, requiring nearly 80 billion frames of experience to achieve. Taking Agent57 as a starting point, we employ a diverse set of strategies to achieve a 200-fold reduction of experience needed to out perform the human baseline. We investigate a range of instabilities and bottlenecks we encountered while reducing the data regime, and propose effective solutions to build a more robust and efficient agent. We also demonstrate competitive performance with high-performing methods such as Muesli and MuZero. The four key components to our approach are (1) an approximate trust region method which enables stable bootstrapping from the online network, (2) a normalisation scheme for the loss and priorities which improves robustness when learning a set of value functions with a wide range of scales, (3) an improved architecture employing techniques from NFNets in order to leverage deeper networks without the need for normalization layers, and (4) a policy distillation method which serves to smooth out the instantaneous greedy policy overtime.
Coverage as a Principle for Discovering Transferable Behavior in Reinforcement Learning
Feb 24, 2021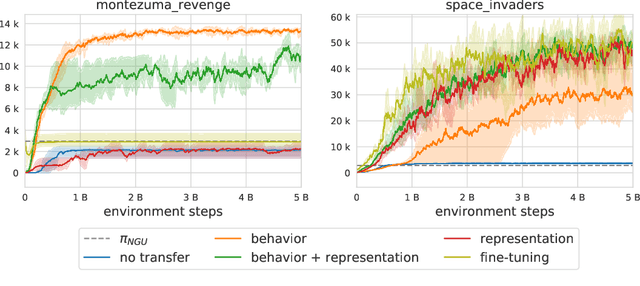
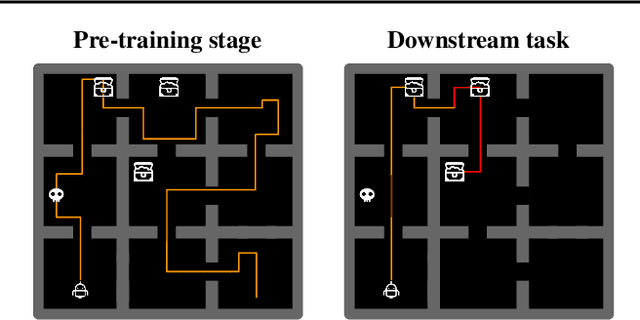
Designing agents that acquire knowledge autonomously and use it to solve new tasks efficiently is an important challenge in reinforcement learning, and unsupervised learning provides a useful paradigm for autonomous acquisition of task-agnostic knowledge. In supervised settings, representations discovered through unsupervised pre-training offer important benefits when transferred to downstream tasks. Given the nature of the reinforcement learning problem, we argue that representation alone is not enough for efficient transfer in challenging domains and explore how to transfer knowledge through behavior. The behavior of pre-trained policies may be used for solving the task at hand (exploitation), as well as for collecting useful data to solve the problem (exploration). We argue that policies pre-trained to maximize coverage will produce behavior that is useful for both strategies. When using these policies for both exploitation and exploration, our agents discover better solutions. The largest gains are generally observed in domains requiring structured exploration, including settings where the behavior of the pre-trained policies is misaligned with the downstream task.
Explore, Discover and Learn: Unsupervised Discovery of State-Covering Skills
Feb 14, 2020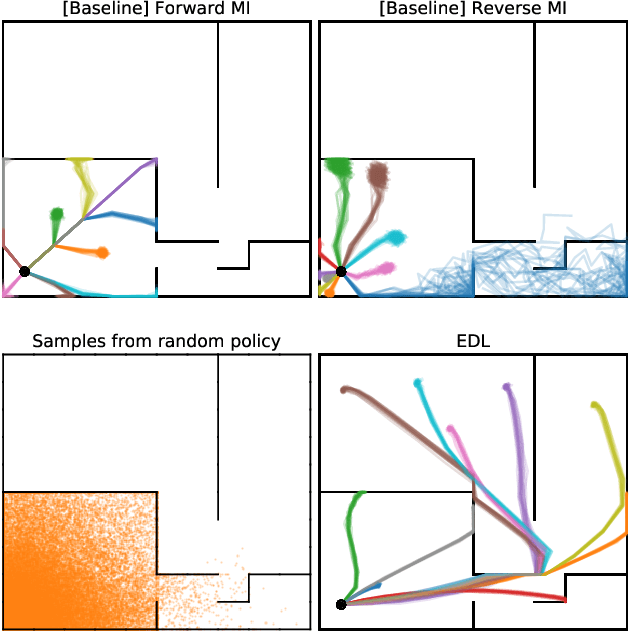



Acquiring abilities in the absence of a task-oriented reward function is at the frontier of reinforcement learning research. This problem has been studied through the lens of empowerment, which draws a connection between option discovery and information theory. Information-theoretic skill discovery methods have garnered much interest from the community, but little research has been conducted in understanding their limitations. Through theoretical analysis and empirical evidence, we show that existing algorithms suffer from a common limitation -- they discover options that provide a poor coverage of the state space. In light of this, we propose 'Explore, Discover and Learn' (EDL), an alternative approach to information-theoretic skill discovery. Crucially, EDL optimizes the same information-theoretic objective derived from the empowerment literature, but addresses the optimization problem using different machinery. We perform an extensive evaluation of skill discovery methods on controlled environments and show that EDL offers significant advantages, such as overcoming the coverage problem, reducing the dependence of learned skills on the initial state, and allowing the user to define a prior over which behaviors should be learned.
Importance Weighted Evolution Strategies
Nov 12, 2018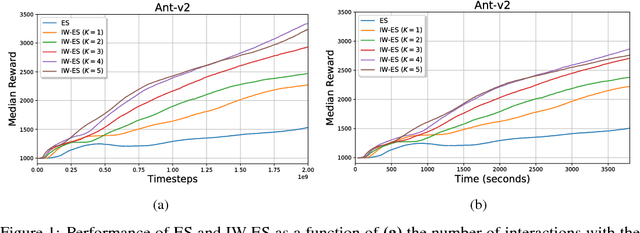
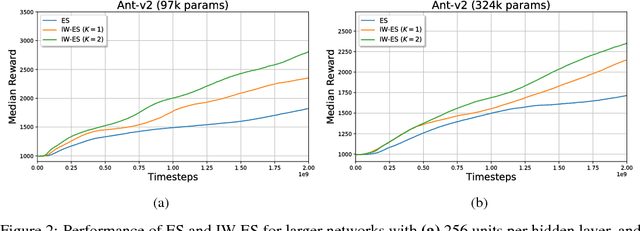
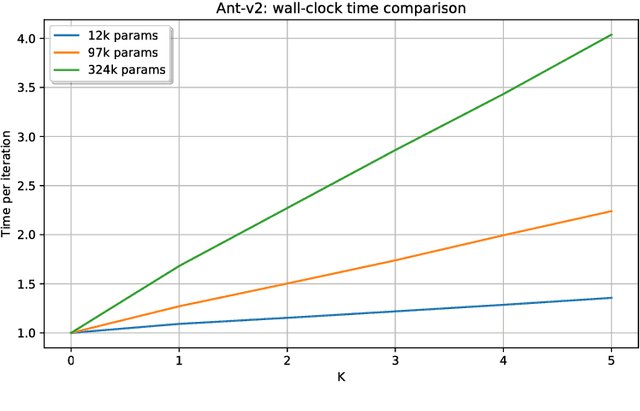
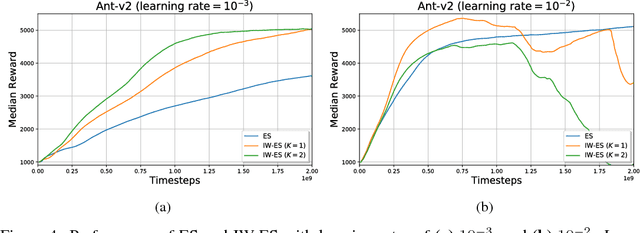
Evolution Strategies (ES) emerged as a scalable alternative to popular Reinforcement Learning (RL) techniques, providing an almost perfect speedup when distributed across hundreds of CPU cores thanks to a reduced communication overhead. Despite providing large improvements in wall-clock time, ES is data inefficient when compared to competing RL methods. One of the main causes of such inefficiency is the collection of large batches of experience, which are discarded after each policy update. In this work, we study how to perform more than one update per batch of experience by means of Importance Sampling while preserving the scalability of the original method. The proposed method, Importance Weighted Evolution Strategies (IW-ES), shows promising results and is a first step towards designing efficient ES algorithms.
Comparing Fixed and Adaptive Computation Time for Recurrent Neural Networks
Mar 21, 2018
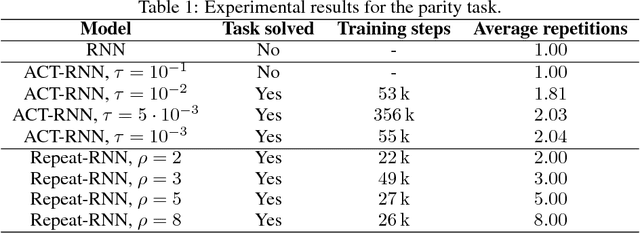
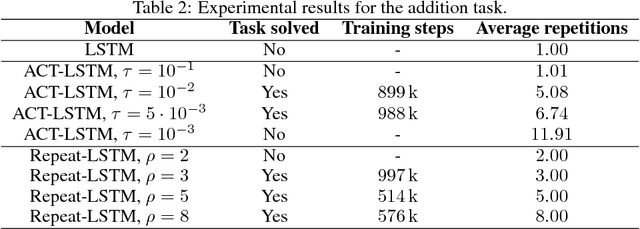
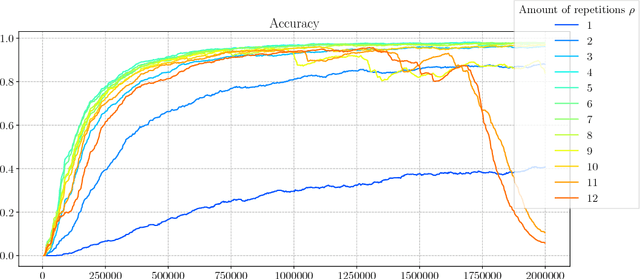
Adaptive Computation Time for Recurrent Neural Networks (ACT) is one of the most promising architectures for variable computation. ACT adapts to the input sequence by being able to look at each sample more than once, and learn how many times it should do it. In this paper, we compare ACT to Repeat-RNN, a novel architecture based on repeating each sample a fixed number of times. We found surprising results, where Repeat-RNN performs as good as ACT in the selected tasks. Source code in TensorFlow and PyTorch is publicly available at https://imatge-upc.github.io/danifojo-2018-repeatrnn/