 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImportance Weighted Evolution Strategies
Paper and Code
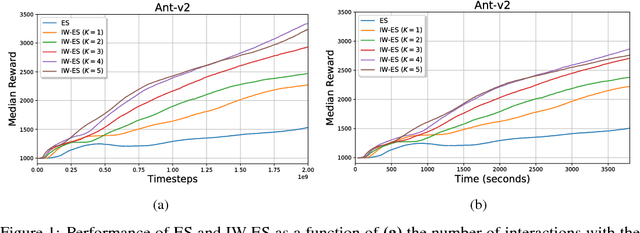
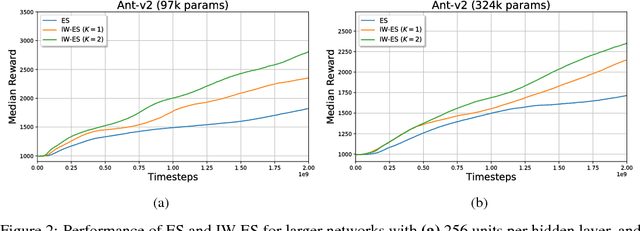
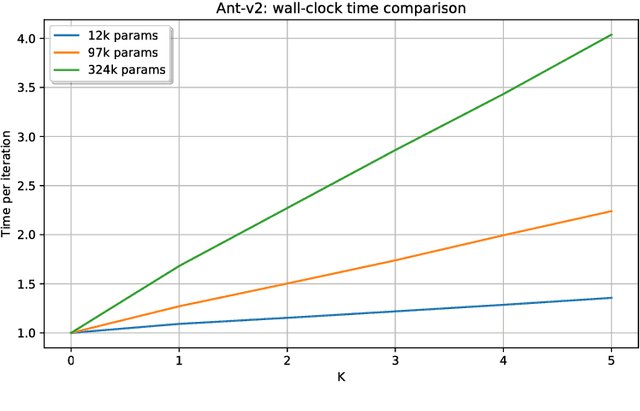
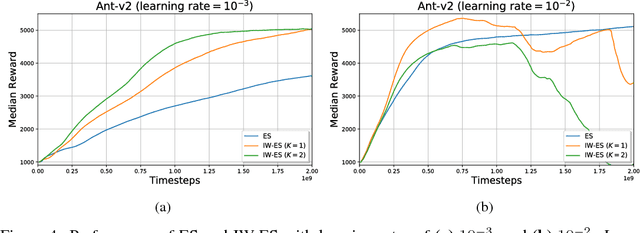
Evolution Strategies (ES) emerged as a scalable alternative to popular Reinforcement Learning (RL) techniques, providing an almost perfect speedup when distributed across hundreds of CPU cores thanks to a reduced communication overhead. Despite providing large improvements in wall-clock time, ES is data inefficient when compared to competing RL methods. One of the main causes of such inefficiency is the collection of large batches of experience, which are discarded after each policy update. In this work, we study how to perform more than one update per batch of experience by means of Importance Sampling while preserving the scalability of the original method. The proposed method, Importance Weighted Evolution Strategies (IW-ES), shows promising results and is a first step towards designing efficient ES algorithms.