 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning in complex action spaces without policy gradients
Oct 08, 2024
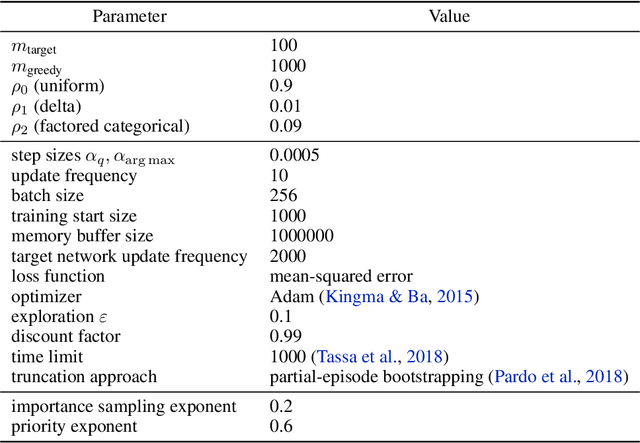
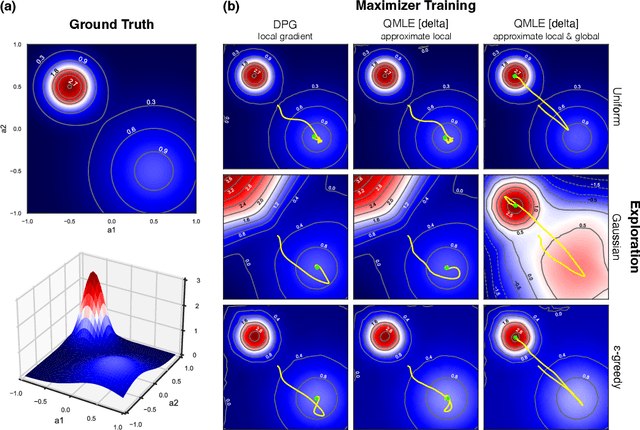
Conventional wisdom suggests that policy gradient methods are better suited to complex action spaces than action-value methods. However, foundational studies have shown equivalences between these paradigms in small and finite action spaces (O'Donoghue et al., 2017; Schulman et al., 2017a). This raises the question of why their computational applicability and performance diverge as the complexity of the action space increases. We hypothesize that the apparent superiority of policy gradients in such settings stems not from intrinsic qualities of the paradigm, but from universal principles that can also be applied to action-value methods to serve similar functionality. We identify three such principles and provide a framework for incorporating them into action-value methods. To support our hypothesis, we instantiate this framework in what we term QMLE, for Q-learning with maximum likelihood estimation. Our results show that QMLE can be applied to complex action spaces with a controllable computational cost that is comparable to that of policy gradient methods, all without using policy gradients. Furthermore, QMLE demonstrates strong performance on the DeepMind Control Suite, even when compared to the state-of-the-art methods such as DMPO and D4PG.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Human-level Atari 200x faster
Sep 15, 2022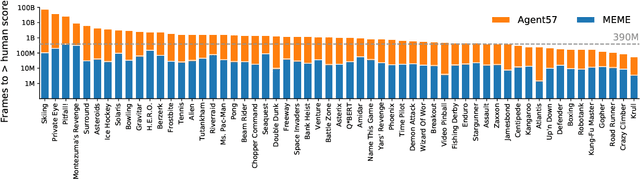
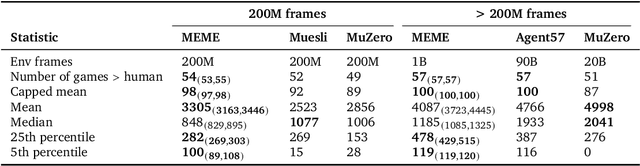
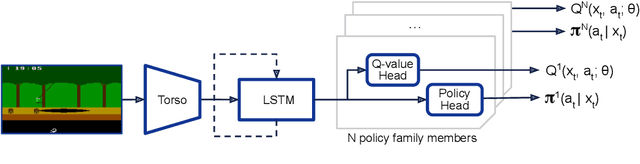

The task of building general agents that perform well over a wide range of tasks has been an important goal in reinforcement learning since its inception. The problem has been subject of research of a large body of work, with performance frequently measured by observing scores over the wide range of environments contained in the Atari 57 benchmark. Agent57 was the first agent to surpass the human benchmark on all 57 games, but this came at the cost of poor data-efficiency, requiring nearly 80 billion frames of experience to achieve. Taking Agent57 as a starting point, we employ a diverse set of strategies to achieve a 200-fold reduction of experience needed to out perform the human baseline. We investigate a range of instabilities and bottlenecks we encountered while reducing the data regime, and propose effective solutions to build a more robust and efficient agent. We also demonstrate competitive performance with high-performing methods such as Muesli and MuZero. The four key components to our approach are (1) an approximate trust region method which enables stable bootstrapping from the online network, (2) a normalisation scheme for the loss and priorities which improves robustness when learning a set of value functions with a wide range of scales, (3) an improved architecture employing techniques from NFNets in order to leverage deeper networks without the need for normalization layers, and (4) a policy distillation method which serves to smooth out the instantaneous greedy policy overtime.