 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunctional Acceleration for Policy Mirror Descent
Jul 23, 2024



We apply functional acceleration to the Policy Mirror Descent (PMD) general family of algorithms, which cover a wide range of novel and fundamental methods in Reinforcement Learning (RL). Leveraging duality, we propose a momentum-based PMD update. By taking the functional route, our approach is independent of the policy parametrization and applicable to large-scale optimization, covering previous applications of momentum at the level of policy parameters as a special case. We theoretically analyze several properties of this approach and complement with a numerical ablation study, which serves to illustrate the policy optimization dynamics on the value polytope, relative to different algorithmic design choices in this space. We further characterize numerically several features of the problem setting relevant for functional acceleration, and lastly, we investigate the impact of approximation on their learning mechanics.
Optimism and Adaptivity in Policy Optimization
Jun 18, 2023We work towards a unifying paradigm for accelerating policy optimization methods in reinforcement learning (RL) through \emph{optimism} \& \emph{adaptivity}. Leveraging the deep connection between policy iteration and policy gradient methods, we recast seemingly unrelated policy optimization algorithms as the repeated application of two interleaving steps (i) an \emph{optimistic policy improvement operator} maps a prior policy $\pi_t$ to a hypothesis $\pi_{t+1}$ using a \emph{gradient ascent prediction}, followed by (ii) a \emph{hindsight adaptation} of the optimistic prediction based on a partial evaluation of the performance of $\pi_{t+1}$. We use this shared lens to jointly express other well-known algorithms, including soft and optimistic policy iteration, natural actor-critic methods, model-based policy improvement based on forward search, and meta-learning algorithms. By doing so, we shed light on collective theoretical properties related to acceleration via optimism \& adaptivity. Building on these insights, we design an \emph{adaptive \& optimistic policy gradient} algorithm via meta-gradient learning, and empirically highlight several design choices pertaining to optimism, in an illustrative task.
Selective Credit Assignment
Feb 20, 2022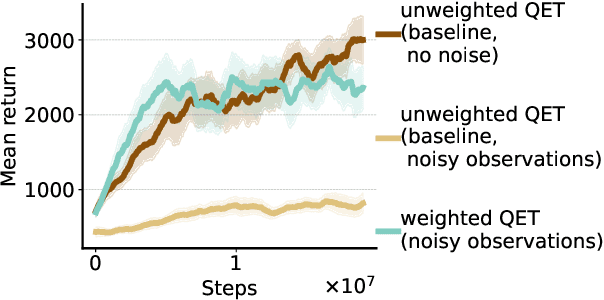
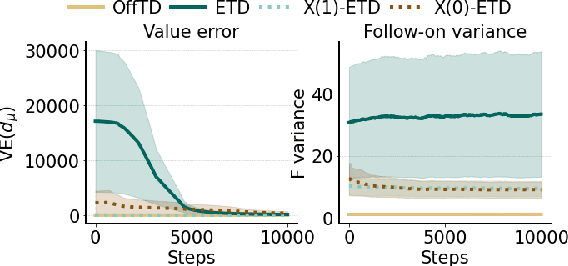
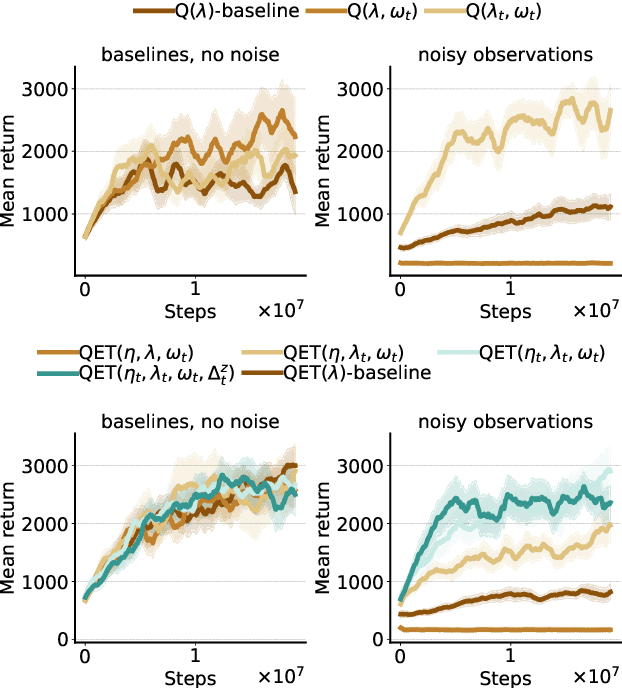
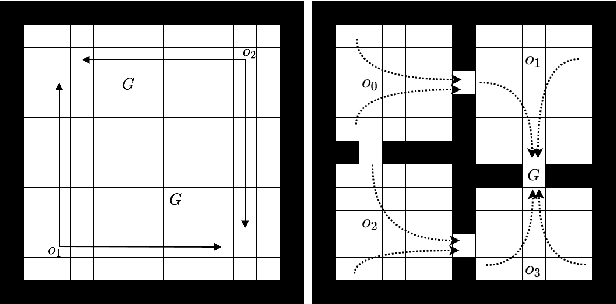
Efficient credit assignment is essential for reinforcement learning algorithms in both prediction and control settings. We describe a unified view on temporal-difference algorithms for selective credit assignment. These selective algorithms apply weightings to quantify the contribution of learning updates. We present insights into applying weightings to value-based learning and planning algorithms, and describe their role in mediating the backward credit distribution in prediction and control. Within this space, we identify some existing online learning algorithms that can assign credit selectively as special cases, as well as add new algorithms that assign credit backward in time counterfactually, allowing credit to be assigned off-trajectory and off-policy.
A Generalized Bootstrap Target for Value-Learning, Efficiently Combining Value and Feature Predictions
Jan 05, 2022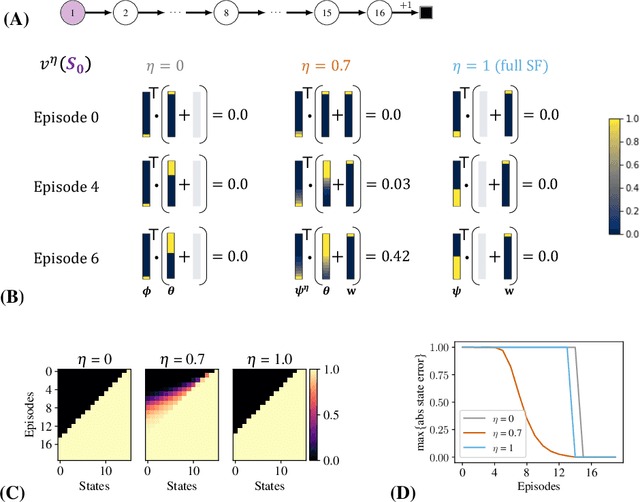



Estimating value functions is a core component of reinforcement learning algorithms. Temporal difference (TD) learning algorithms use bootstrapping, i.e. they update the value function toward a learning target using value estimates at subsequent time-steps. Alternatively, the value function can be updated toward a learning target constructed by separately predicting successor features (SF)--a policy-dependent model--and linearly combining them with instantaneous rewards. We focus on bootstrapping targets used when estimating value functions, and propose a new backup target, the $\eta$-return mixture, which implicitly combines value-predictive knowledge (used by TD methods) with (successor) feature-predictive knowledge--with a parameter $\eta$ capturing how much to rely on each. We illustrate that incorporating predictive knowledge through an $\eta\gamma$-discounted SF model makes more efficient use of sampled experience, compared to either extreme, i.e. bootstrapping entirely on the value function estimate, or bootstrapping on the product of separately estimated successor features and instantaneous reward models. We empirically show this approach leads to faster policy evaluation and better control performance, for tabular and nonlinear function approximations, indicating scalability and generality.
Learning Expected Emphatic Traces for Deep RL
Jul 12, 2021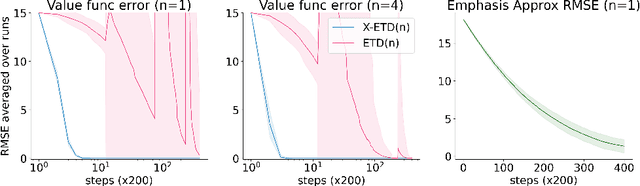

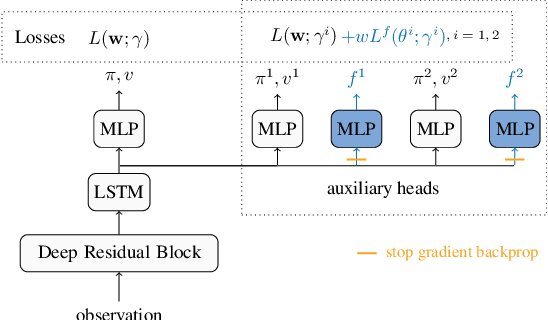
Off-policy sampling and experience replay are key for improving sample efficiency and scaling model-free temporal difference learning methods. When combined with function approximation, such as neural networks, this combination is known as the deadly triad and is potentially unstable. Recently, it has been shown that stability and good performance at scale can be achieved by combining emphatic weightings and multi-step updates. This approach, however, is generally limited to sampling complete trajectories in order, to compute the required emphatic weighting. In this paper we investigate how to combine emphatic weightings with non-sequential, off-line data sampled from a replay buffer. We develop a multi-step emphatic weighting that can be combined with replay, and a time-reversed $n$-step TD learning algorithm to learn the required emphatic weighting. We show that these state weightings reduce variance compared with prior approaches, while providing convergence guarantees. We tested the approach at scale on Atari 2600 video games, and observed that the new X-ETD($n$) agent improved over baseline agents, highlighting both the scalability and broad applicability of our approach.
Forethought and Hindsight in Credit Assignment
Oct 26, 2020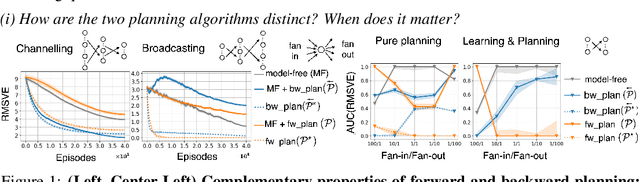
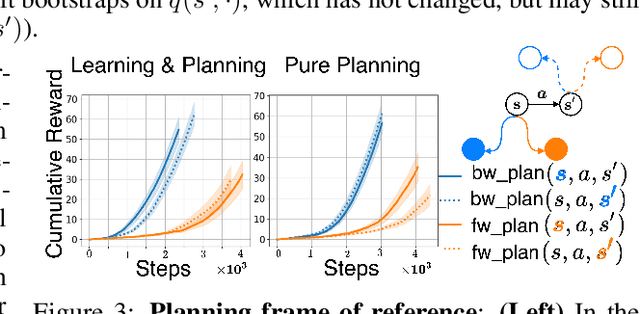
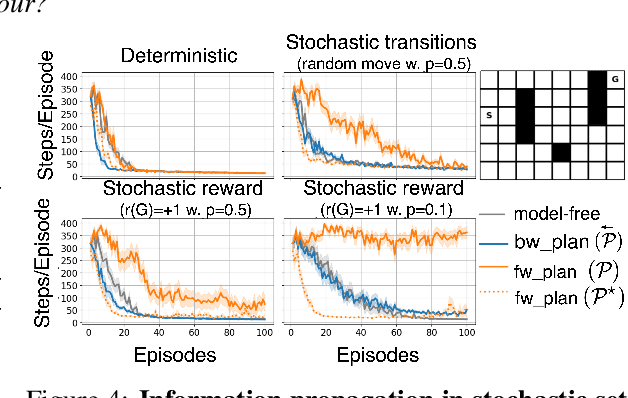

We address the problem of credit assignment in reinforcement learning and explore fundamental questions regarding the way in which an agent can best use additional computation to propagate new information, by planning with internal models of the world to improve its predictions. Particularly, we work to understand the gains and peculiarities of planning employed as forethought via forward models or as hindsight operating with backward models. We establish the relative merits, limitations and complementary properties of both planning mechanisms in carefully constructed scenarios. Further, we investigate the best use of models in planning, primarily focusing on the selection of states in which predictions should be (re)-evaluated. Lastly, we discuss the issue of model estimation and highlight a spectrum of methods that stretch from explicit environment-dynamics predictors to more abstract planner-aware models.