 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Timescale Adaptation in an Open-Ended Task Space
Jan 18, 2023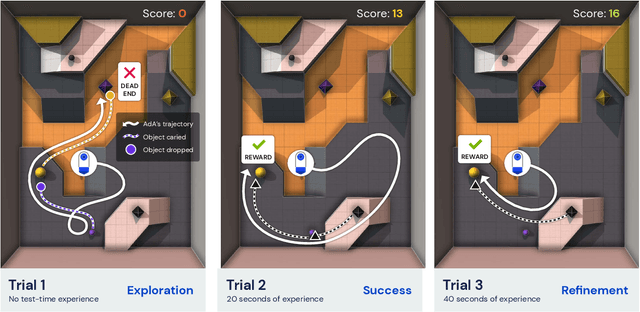
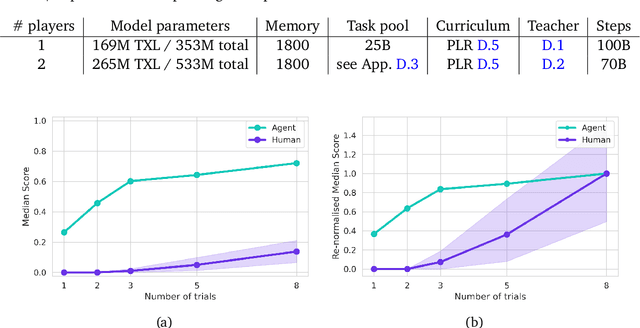
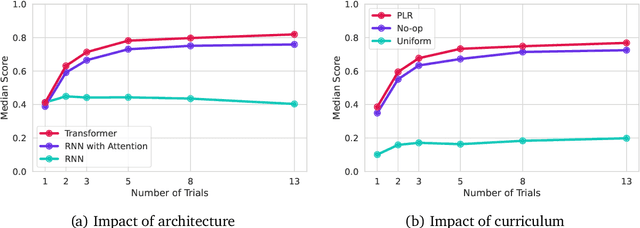
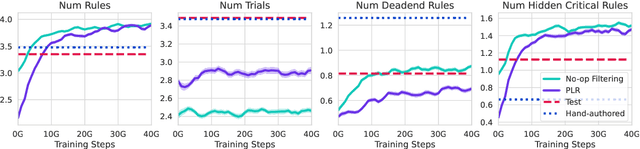
Foundation models have shown impressive adaptation and scalability in supervised and self-supervised learning problems, but so far these successes have not fully translated to reinforcement learning (RL). In this work, we demonstrate that training an RL agent at scale leads to a general in-context learning algorithm that can adapt to open-ended novel embodied 3D problems as quickly as humans. In a vast space of held-out environment dynamics, our adaptive agent (AdA) displays on-the-fly hypothesis-driven exploration, efficient exploitation of acquired knowledge, and can successfully be prompted with first-person demonstrations. Adaptation emerges from three ingredients: (1) meta-reinforcement learning across a vast, smooth and diverse task distribution, (2) a policy parameterised as a large-scale attention-based memory architecture, and (3) an effective automated curriculum that prioritises tasks at the frontier of an agent's capabilities. We demonstrate characteristic scaling laws with respect to network size, memory length, and richness of the training task distribution. We believe our results lay the foundation for increasingly general and adaptive RL agents that perform well across ever-larger open-ended domains.
Self-Organizing Intelligent Matter: A blueprint for an AI generating algorithm
Jan 19, 2021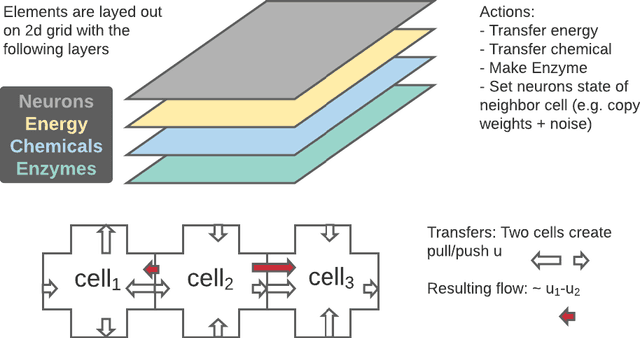

We propose an artificial life framework aimed at facilitating the emergence of intelligent organisms. In this framework there is no explicit notion of an agent: instead there is an environment made of atomic elements. These elements contain neural operations and interact through exchanges of information and through physics-like rules contained in the environment. We discuss how an evolutionary process can lead to the emergence of different organisms made of many such atomic elements which can coexist and thrive in the environment. We discuss how this forms the basis of a general AI generating algorithm. We provide a simplified implementation of such system and discuss what advances need to be made to scale it up further.
Finding online neural update rules by learning to remember
Mar 06, 2020
We investigate learning of the online local update rules for neural activations (bodies) and weights (synapses) from scratch. We represent the states of each weight and activation by small vectors, and parameterize their updates using (meta-) neural networks. Different neuron types are represented by different embedding vectors which allows the same two functions to be used for all neurons. Instead of training directly for the objective using evolution or long term back-propagation, as is commonly done in similar systems, we motivate and study a different objective: That of remembering past snippets of experience. We explain how this objective relates to standard back-propagation training and other forms of learning. We train for this objective using short term back-propagation and analyze the performance as a function of both the different network types and the difficulty of the problem. We find that this analysis gives interesting insights onto what constitutes a learning rule. We also discuss how such system could form a natural substrate for addressing topics such as episodic memories, meta-learning and auxiliary objectives.
Causally Correct Partial Models for Reinforcement Learning
Feb 07, 2020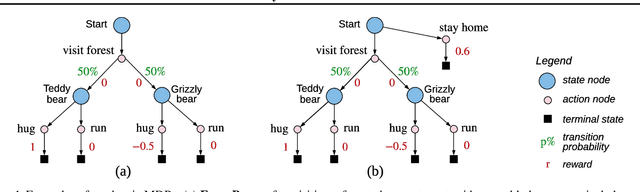


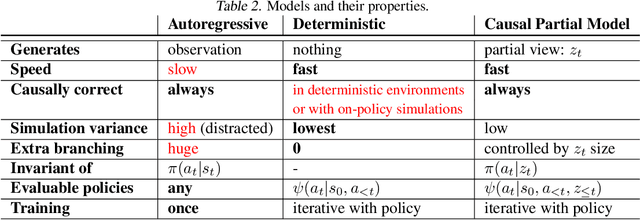
In reinforcement learning, we can learn a model of future observations and rewards, and use it to plan the agent's next actions. However, jointly modeling future observations can be computationally expensive or even intractable if the observations are high-dimensional (e.g. images). For this reason, previous works have considered partial models, which model only part of the observation. In this paper, we show that partial models can be causally incorrect: they are confounded by the observations they don't model, and can therefore lead to incorrect planning. To address this, we introduce a general family of partial models that are provably causally correct, yet remain fast because they do not need to fully model future observations.
Shaping Belief States with Generative Environment Models for RL
Jun 24, 2019


When agents interact with a complex environment, they must form and maintain beliefs about the relevant aspects of that environment. We propose a way to efficiently train expressive generative models in complex environments. We show that a predictive algorithm with an expressive generative model can form stable belief-states in visually rich and dynamic 3D environments. More precisely, we show that the learned representation captures the layout of the environment as well as the position and orientation of the agent. Our experiments show that the model substantially improves data-efficiency on a number of reinforcement learning (RL) tasks compared with strong model-free baseline agents. We find that predicting multiple steps into the future (overshooting), in combination with an expressive generative model, is critical for stable representations to emerge. In practice, using expressive generative models in RL is computationally expensive and we propose a scheme to reduce this computational burden, allowing us to build agents that are competitive with model-free baselines.
An investigation of model-free planning
Jan 11, 2019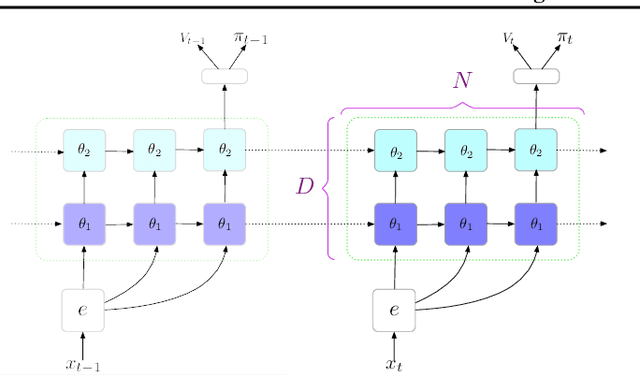
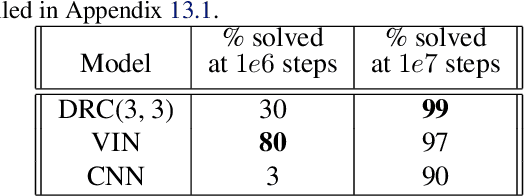
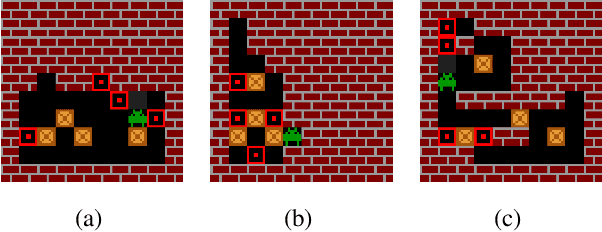
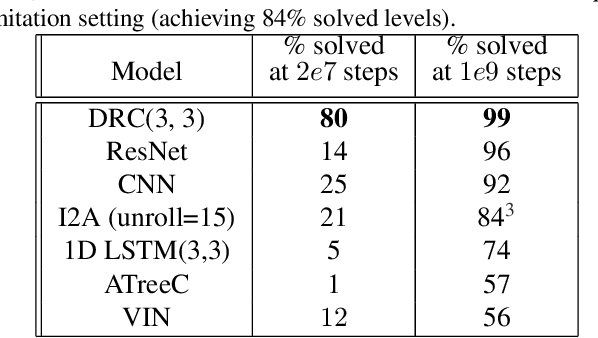
The field of reinforcement learning (RL) is facing increasingly challenging domains with combinatorial complexity. For an RL agent to address these challenges, it is essential that it can plan effectively. Prior work has typically utilized an explicit model of the environment, combined with a specific planning algorithm (such as tree search). More recently, a new family of methods have been proposed that learn how to plan, by providing the structure for planning via an inductive bias in the function approximator (such as a tree structured neural network), trained end-to-end by a model-free RL algorithm. In this paper, we go even further, and demonstrate empirically that an entirely model-free approach, without special structure beyond standard neural network components such as convolutional networks and LSTMs, can learn to exhibit many of the characteristics typically associated with a model-based planner. We measure our agent's effectiveness at planning in terms of its ability to generalize across a combinatorial and irreversible state space, its data efficiency, and its ability to utilize additional thinking time. We find that our agent has many of the characteristics that one might expect to find in a planning algorithm. Furthermore, it exceeds the state-of-the-art in challenging combinatorial domains such as Sokoban and outperforms other model-free approaches that utilize strong inductive biases toward planning.
Learning Attractor Dynamics for Generative Memory
Nov 23, 2018



A central challenge faced by memory systems is the robust retrieval of a stored pattern in the presence of interference due to other stored patterns and noise. A theoretically well-founded solution to robust retrieval is given by attractor dynamics, which iteratively clean up patterns during recall. However, incorporating attractor dynamics into modern deep learning systems poses difficulties: attractor basins are characterised by vanishing gradients, which are known to make training neural networks difficult. In this work, we avoid the vanishing gradient problem by training a generative distributed memory without simulating the attractor dynamics. Based on the idea of memory writing as inference, as proposed in the Kanerva Machine, we show that a likelihood-based Lyapunov function emerges from maximising the variational lower-bound of a generative memory. Experiments shows it converges to correct patterns upon iterative retrieval and achieves competitive performance as both a memory model and a generative model.
Temporal Difference Variational Auto-Encoder
Jun 11, 2018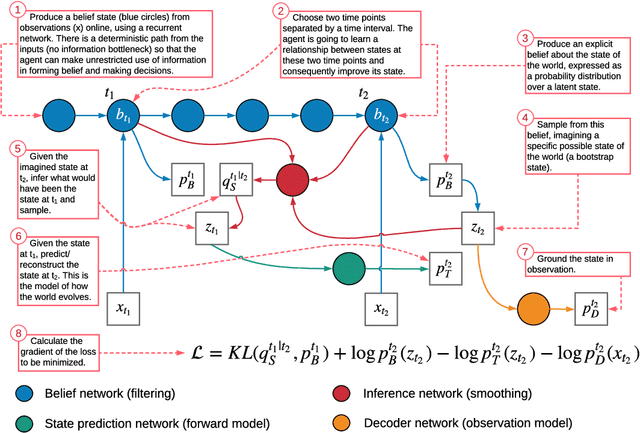


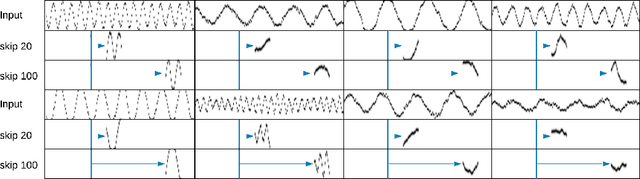
One motivation for learning generative models of environments is to use them as simulators for model-based reinforcement learning. Yet, it is intuitively clear that when time horizons are long, rolling out single step transitions is inefficient and often prohibitive. In this paper, we propose a generative model that learns state representations containing explicit beliefs about states several time steps in the future and that can be rolled out directly in these states without executing single step transitions. The model is trained on pairs of temporally separated time points, using an analogue of temporal difference learning used in reinforcement learning, taking the belief about possible futures at one time point as a bootstrap for training the belief at an earlier time. While we focus purely on the study of the model rather than its use in reinforcement learning, the model architecture we design respects agents' constraints as it builds the representation online.
Learning and Querying Fast Generative Models for Reinforcement Learning
Feb 08, 2018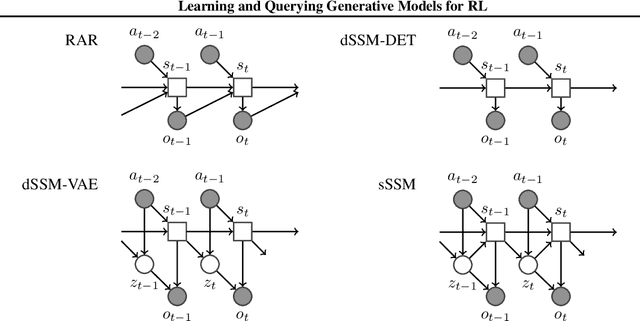

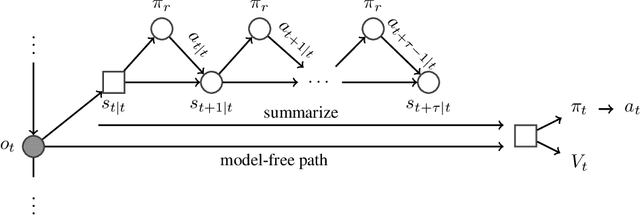
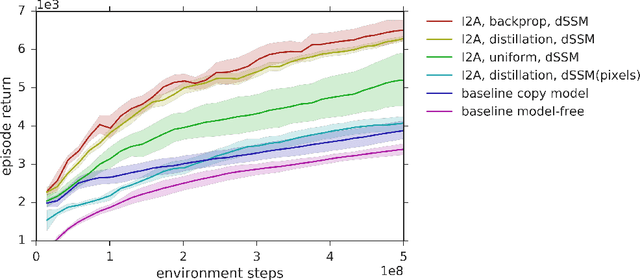
A key challenge in model-based reinforcement learning (RL) is to synthesize computationally efficient and accurate environment models. We show that carefully designed generative models that learn and operate on compact state representations, so-called state-space models, substantially reduce the computational costs for predicting outcomes of sequences of actions. Extensive experiments establish that state-space models accurately capture the dynamics of Atari games from the Arcade Learning Environment from raw pixels. The computational speed-up of state-space models while maintaining high accuracy makes their application in RL feasible: We demonstrate that agents which query these models for decision making outperform strong model-free baselines on the game MSPACMAN, demonstrating the potential of using learned environment models for planning.
Variational Intrinsic Control
Nov 22, 2016
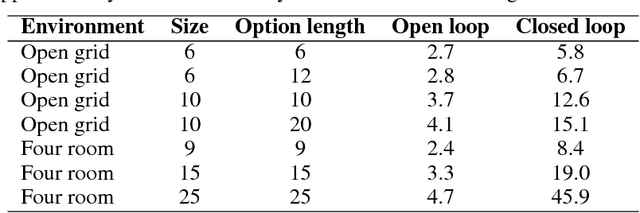

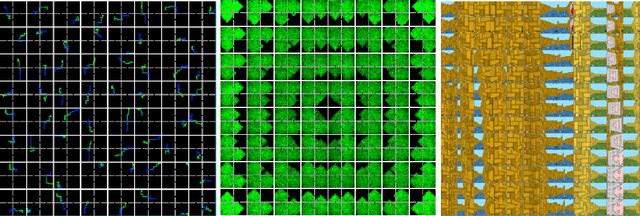
In this paper we introduce a new unsupervised reinforcement learning method for discovering the set of intrinsic options available to an agent. This set is learned by maximizing the number of different states an agent can reliably reach, as measured by the mutual information between the set of options and option termination states. To this end, we instantiate two policy gradient based algorithms, one that creates an explicit embedding space of options and one that represents options implicitly. The algorithms also provide an explicit measure of empowerment in a given state that can be used by an empowerment maximizing agent. The algorithm scales well with function approximation and we demonstrate the applicability of the algorithm on a range of tasks.