 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated curricula through setter-solver interactions
Sep 27, 2019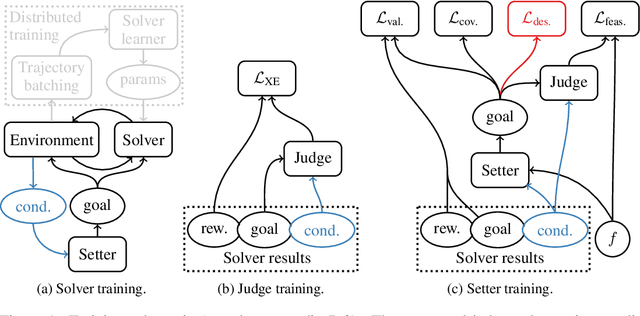

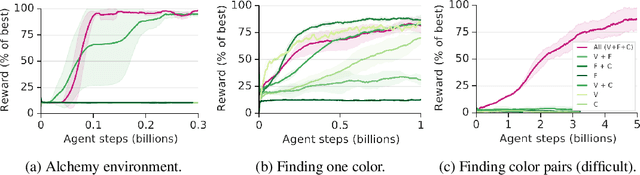
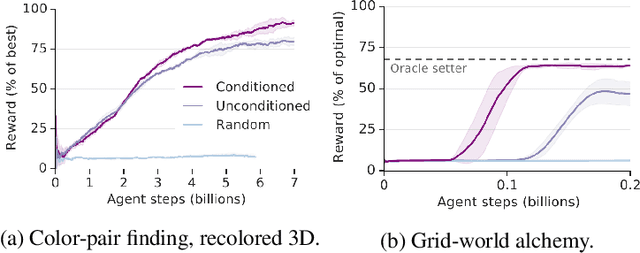
Reinforcement learning algorithms use correlations between policies and rewards to improve agent performance. But in dynamic or sparsely rewarding environments these correlations are often too small, or rewarding events are too infrequent to make learning feasible. Human education instead relies on curricula--the breakdown of tasks into simpler, static challenges with dense rewards--to build up to complex behaviors. While curricula are also useful for artificial agents, hand-crafting them is time consuming. This has lead researchers to explore automatic curriculum generation. Here we explore automatic curriculum generation in rich, dynamic environments. Using a setter-solver paradigm we show the importance of considering goal validity, goal feasibility, and goal coverage to construct useful curricula. We demonstrate the success of our approach in rich but sparsely rewarding 2D and 3D environments, where an agent is tasked to achieve a single goal selected from a set of possible goals that varies between episodes, and identify challenges for future work. Finally, we demonstrate the value of a novel technique that guides agents towards a desired goal distribution. Altogether, these results represent a substantial step towards applying automatic task curricula to learn complex, otherwise unlearnable goals, and to our knowledge are the first to demonstrate automated curriculum generation for goal-conditioned agents in environments where the possible goals vary between episodes.
Differentiable Game Mechanics
May 13, 2019
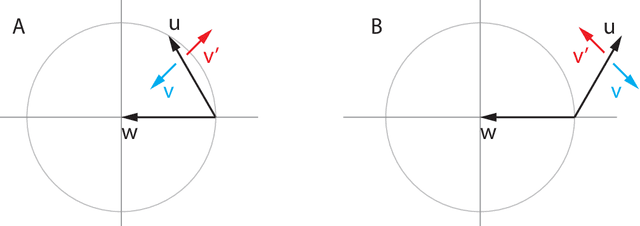
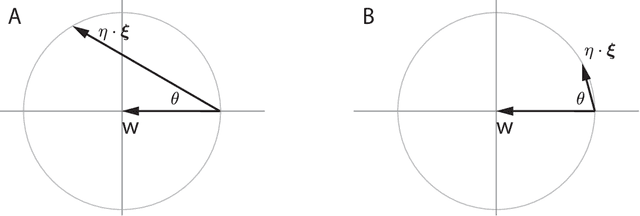
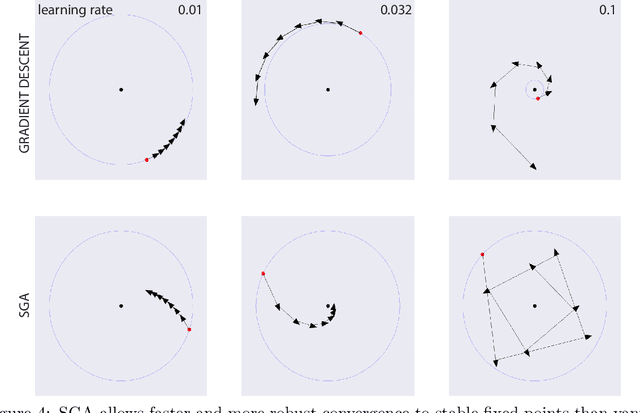
Deep learning is built on the foundational guarantee that gradient descent on an objective function converges to local minima. Unfortunately, this guarantee fails in settings, such as generative adversarial nets, that exhibit multiple interacting losses. The behavior of gradient-based methods in games is not well understood -- and is becoming increasingly important as adversarial and multi-objective architectures proliferate. In this paper, we develop new tools to understand and control the dynamics in n-player differentiable games. The key result is to decompose the game Jacobian into two components. The first, symmetric component, is related to potential games, which reduce to gradient descent on an implicit function. The second, antisymmetric component, relates to Hamiltonian games, a new class of games that obey a conservation law akin to conservation laws in classical mechanical systems. The decomposition motivates Symplectic Gradient Adjustment (SGA), a new algorithm for finding stable fixed points in differentiable games. Basic experiments show SGA is competitive with recently proposed algorithms for finding stable fixed points in GANs -- while at the same time being applicable to, and having guarantees in, much more general cases.
* JMLR 2019, journal version of arXiv:1802.05642
Towards a Definition of Disentangled Representations
Dec 05, 2018
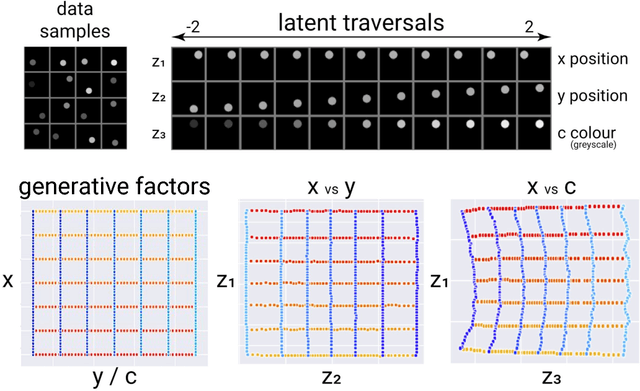
How can intelligent agents solve a diverse set of tasks in a data-efficient manner? The disentangled representation learning approach posits that such an agent would benefit from separating out (disentangling) the underlying structure of the world into disjoint parts of its representation. However, there is no generally agreed-upon definition of disentangling, not least because it is unclear how to formalise the notion of world structure beyond toy datasets with a known ground truth generative process. Here we propose that a principled solution to characterising disentangled representations can be found by focusing on the transformation properties of the world. In particular, we suggest that those transformations that change only some properties of the underlying world state, while leaving all other properties invariant, are what gives exploitable structure to any kind of data. Similar ideas have already been successfully applied in physics, where the study of symmetry transformations has revolutionised the understanding of the world structure. By connecting symmetry transformations to vector representations using the formalism of group and representation theory we arrive at the first formal definition of disentangled representations. Our new definition is in agreement with many of the current intuitions about disentangling, while also providing principled resolutions to a number of previous points of contention. While this work focuses on formally defining disentangling - as opposed to solving the learning problem - we believe that the shift in perspective to studying data transformations can stimulate the development of better representation learning algorithms.
Woulda, Coulda, Shoulda: Counterfactually-Guided Policy Search
Nov 15, 2018



Learning policies on data synthesized by models can in principle quench the thirst of reinforcement learning algorithms for large amounts of real experience, which is often costly to acquire. However, simulating plausible experience de novo is a hard problem for many complex environments, often resulting in biases for model-based policy evaluation and search. Instead of de novo synthesis of data, here we assume logged, real experience and model alternative outcomes of this experience under counterfactual actions, actions that were not actually taken. Based on this, we propose the Counterfactually-Guided Policy Search (CF-GPS) algorithm for learning policies in POMDPs from off-policy experience. It leverages structural causal models for counterfactual evaluation of arbitrary policies on individual off-policy episodes. CF-GPS can improve on vanilla model-based RL algorithms by making use of available logged data to de-bias model predictions. In contrast to off-policy algorithms based on Importance Sampling which re-weight data, CF-GPS leverages a model to explicitly consider alternative outcomes, allowing the algorithm to make better use of experience data. We find empirically that these advantages translate into improved policy evaluation and search results on a non-trivial grid-world task. Finally, we show that CF-GPS generalizes the previously proposed Guided Policy Search and that reparameterization-based algorithms such Stochastic Value Gradient can be interpreted as counterfactual methods.
The Mechanics of n-Player Differentiable Games
Jun 06, 2018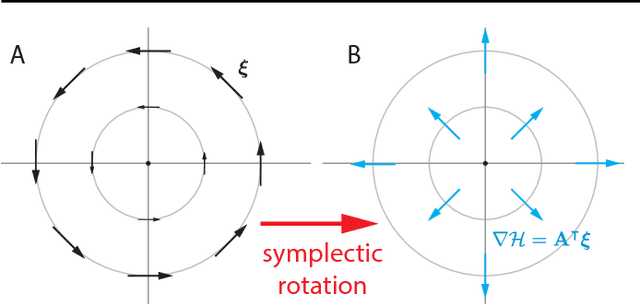
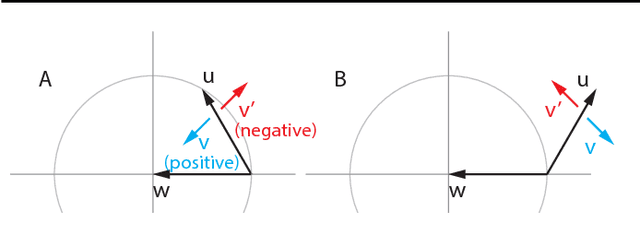
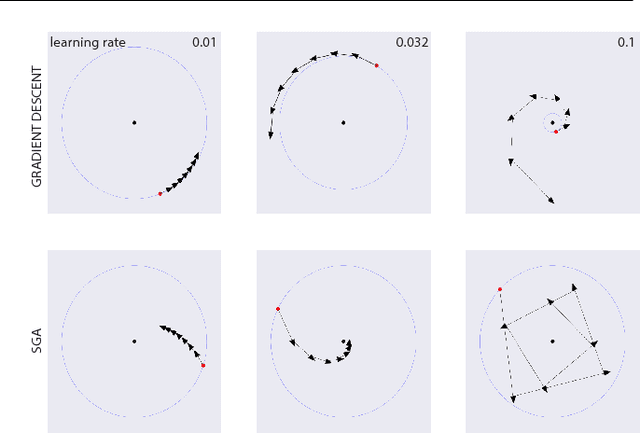
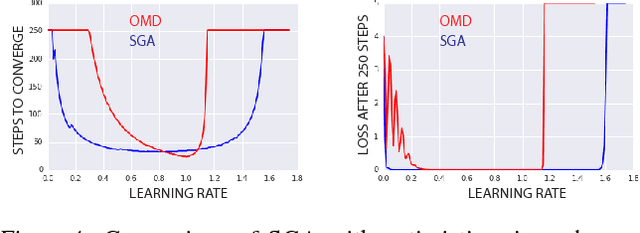
The cornerstone underpinning deep learning is the guarantee that gradient descent on an objective converges to local minima. Unfortunately, this guarantee fails in settings, such as generative adversarial nets, where there are multiple interacting losses. The behavior of gradient-based methods in games is not well understood -- and is becoming increasingly important as adversarial and multi-objective architectures proliferate. In this paper, we develop new techniques to understand and control the dynamics in general games. The key result is to decompose the second-order dynamics into two components. The first is related to potential games, which reduce to gradient descent on an implicit function; the second relates to Hamiltonian games, a new class of games that obey a conservation law, akin to conservation laws in classical mechanical systems. The decomposition motivates Symplectic Gradient Adjustment (SGA), a new algorithm for finding stable fixed points in general games. Basic experiments show SGA is competitive with recently proposed algorithms for finding stable fixed points in GANs -- whilst at the same time being applicable to -- and having guarantees in -- much more general games.
* ICML 2018, final version
Learning and Querying Fast Generative Models for Reinforcement Learning
Feb 08, 2018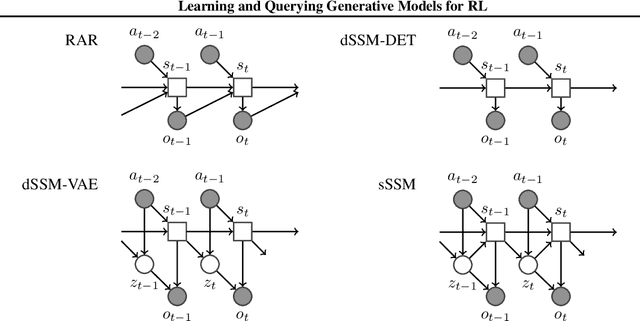

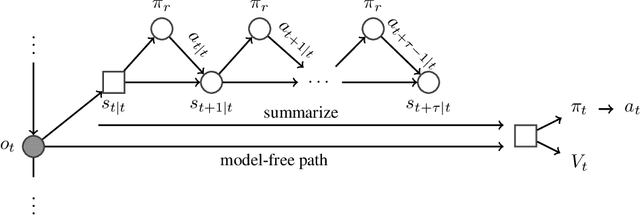
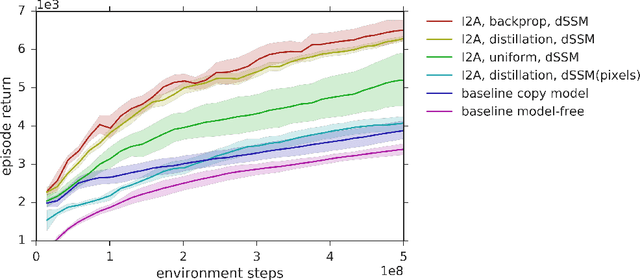
A key challenge in model-based reinforcement learning (RL) is to synthesize computationally efficient and accurate environment models. We show that carefully designed generative models that learn and operate on compact state representations, so-called state-space models, substantially reduce the computational costs for predicting outcomes of sequences of actions. Extensive experiments establish that state-space models accurately capture the dynamics of Atari games from the Arcade Learning Environment from raw pixels. The computational speed-up of state-space models while maintaining high accuracy makes their application in RL feasible: We demonstrate that agents which query these models for decision making outperform strong model-free baselines on the game MSPACMAN, demonstrating the potential of using learned environment models for planning.