 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Organizing Intelligent Matter: A blueprint for an AI generating algorithm
Jan 19, 2021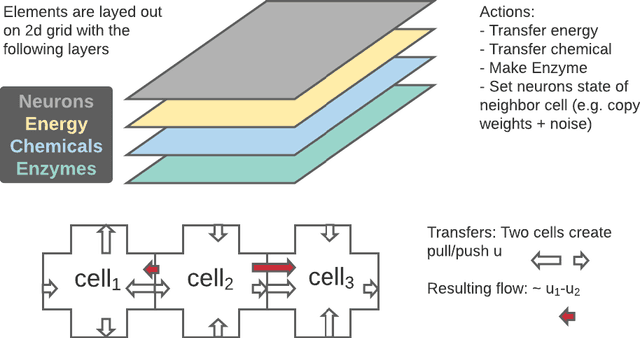

We propose an artificial life framework aimed at facilitating the emergence of intelligent organisms. In this framework there is no explicit notion of an agent: instead there is an environment made of atomic elements. These elements contain neural operations and interact through exchanges of information and through physics-like rules contained in the environment. We discuss how an evolutionary process can lead to the emergence of different organisms made of many such atomic elements which can coexist and thrive in the environment. We discuss how this forms the basis of a general AI generating algorithm. We provide a simplified implementation of such system and discuss what advances need to be made to scale it up further.
Causally Correct Partial Models for Reinforcement Learning
Feb 07, 2020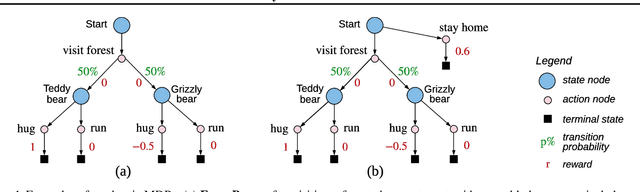


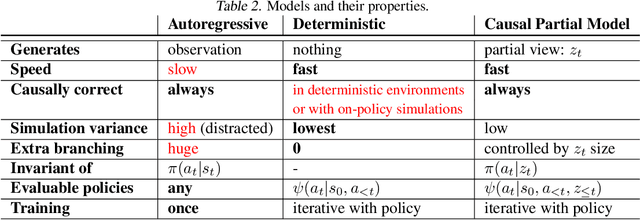
In reinforcement learning, we can learn a model of future observations and rewards, and use it to plan the agent's next actions. However, jointly modeling future observations can be computationally expensive or even intractable if the observations are high-dimensional (e.g. images). For this reason, previous works have considered partial models, which model only part of the observation. In this paper, we show that partial models can be causally incorrect: they are confounded by the observations they don't model, and can therefore lead to incorrect planning. To address this, we introduce a general family of partial models that are provably causally correct, yet remain fast because they do not need to fully model future observations.
Shaping Belief States with Generative Environment Models for RL
Jun 24, 2019


When agents interact with a complex environment, they must form and maintain beliefs about the relevant aspects of that environment. We propose a way to efficiently train expressive generative models in complex environments. We show that a predictive algorithm with an expressive generative model can form stable belief-states in visually rich and dynamic 3D environments. More precisely, we show that the learned representation captures the layout of the environment as well as the position and orientation of the agent. Our experiments show that the model substantially improves data-efficiency on a number of reinforcement learning (RL) tasks compared with strong model-free baseline agents. We find that predicting multiple steps into the future (overshooting), in combination with an expressive generative model, is critical for stable representations to emerge. In practice, using expressive generative models in RL is computationally expensive and we propose a scheme to reduce this computational burden, allowing us to build agents that are competitive with model-free baselines.
TF-Replicator: Distributed Machine Learning for Researchers
Feb 01, 2019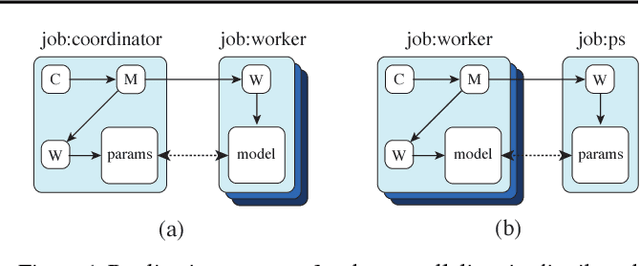

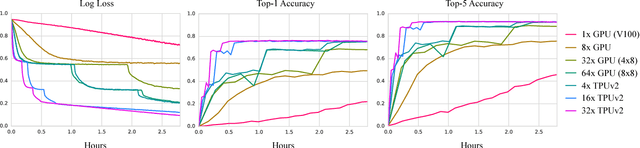
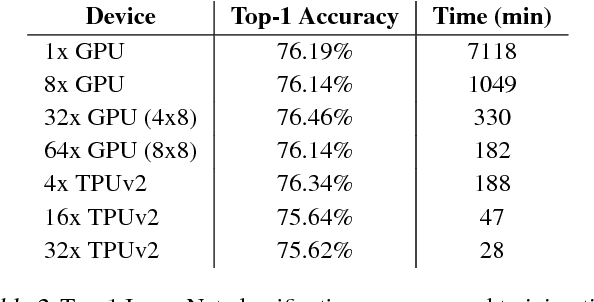
We describe TF-Replicator, a framework for distributed machine learning designed for DeepMind researchers and implemented as an abstraction over TensorFlow. TF-Replicator simplifies writing data-parallel and model-parallel research code. The same models can be effortlessly deployed to different cluster architectures (i.e. one or many machines containing CPUs, GPUs or TPU accelerators) using synchronous or asynchronous training regimes. To demonstrate the generality and scalability of TF-Replicator, we implement and benchmark three very different models: (1) A ResNet-50 for ImageNet classification, (2) a SN-GAN for class-conditional ImageNet image generation, and (3) a D4PG reinforcement learning agent for continuous control. Our results show strong scalability performance without demanding any distributed systems expertise of the user. The TF-Replicator programming model will be open-sourced as part of TensorFlow 2.0 (see https://github.com/tensorflow/community/pull/25).
Encoding Spatial Relations from Natural Language
Jul 05, 2018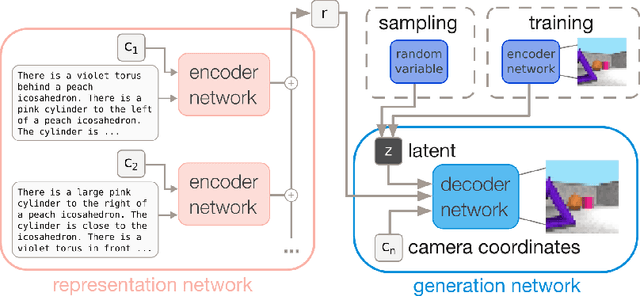

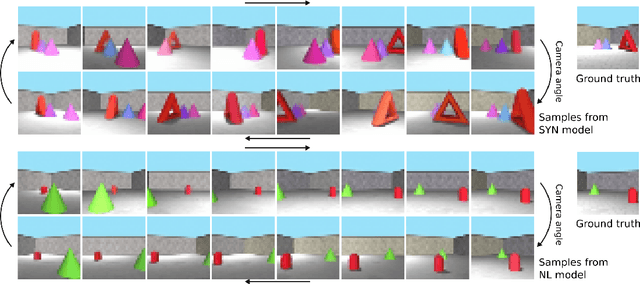
Natural language processing has made significant inroads into learning the semantics of words through distributional approaches, however representations learnt via these methods fail to capture certain kinds of information implicit in the real world. In particular, spatial relations are encoded in a way that is inconsistent with human spatial reasoning and lacking invariance to viewpoint changes. We present a system capable of capturing the semantics of spatial relations such as behind, left of, etc from natural language. Our key contributions are a novel multi-modal objective based on generating images of scenes from their textual descriptions, and a new dataset on which to train it. We demonstrate that internal representations are robust to meaning preserving transformations of descriptions (paraphrase invariance), while viewpoint invariance is an emergent property of the system.
Learning models for visual 3D localization with implicit mapping
Jul 04, 2018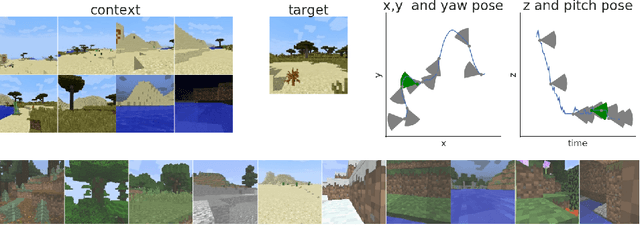
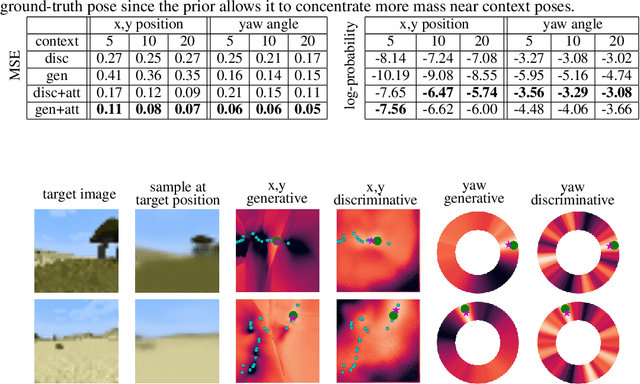
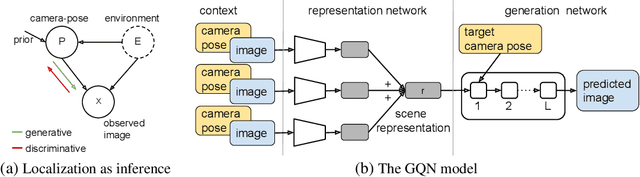
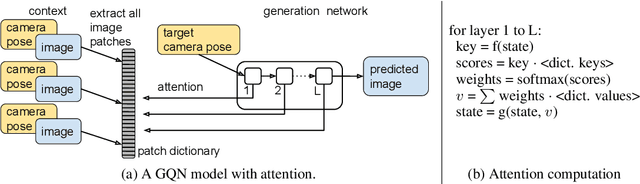
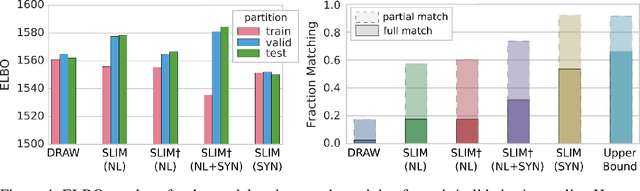
We propose a formulation of visual localization that does not require construction of explicit maps in the form of point clouds or voxels. The goal is to learn an implicit representation of the environment at a higher, more abstract level, for instance that of objects. To study this approach we consider procedurally generated Minecraft worlds, for which we can generate visually rich images along with camera pose coordinates. We first show that Generative Query Networks (GQNs) enhanced with a novel attention mechanism can capture the visual structure of 3D scenes in Minecraft, as evidenced by their samples. We then apply the models to the localization problem, investigating both generative and discriminative approaches, and compare the different ways in which they each capture task uncertainty. Our results show that models with implicit mapping are able to capture the underlying 3D structure of visually complex scenes, and use this to accurately localize new observations, paving the way towards future applications in sequential localization. Supplementary video available at https://youtu.be/iHEXX5wXbCI.
Temporal Difference Variational Auto-Encoder
Jun 11, 2018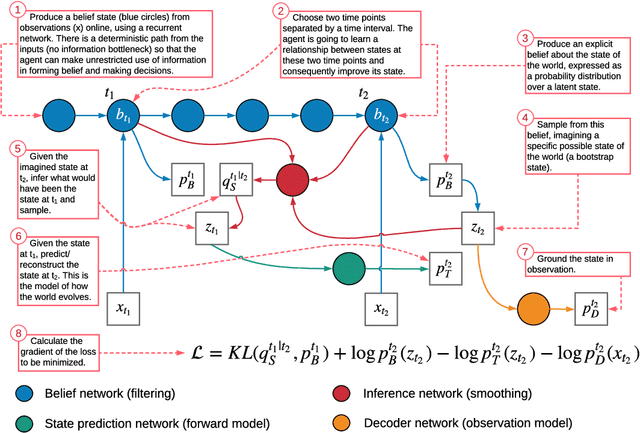


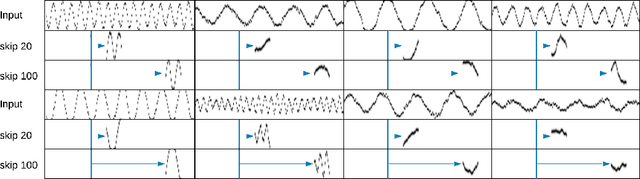
One motivation for learning generative models of environments is to use them as simulators for model-based reinforcement learning. Yet, it is intuitively clear that when time horizons are long, rolling out single step transitions is inefficient and often prohibitive. In this paper, we propose a generative model that learns state representations containing explicit beliefs about states several time steps in the future and that can be rolled out directly in these states without executing single step transitions. The model is trained on pairs of temporally separated time points, using an analogue of temporal difference learning used in reinforcement learning, taking the belief about possible futures at one time point as a bootstrap for training the belief at an earlier time. While we focus purely on the study of the model rather than its use in reinforcement learning, the model architecture we design respects agents' constraints as it builds the representation online.
Learning and Querying Fast Generative Models for Reinforcement Learning
Feb 08, 2018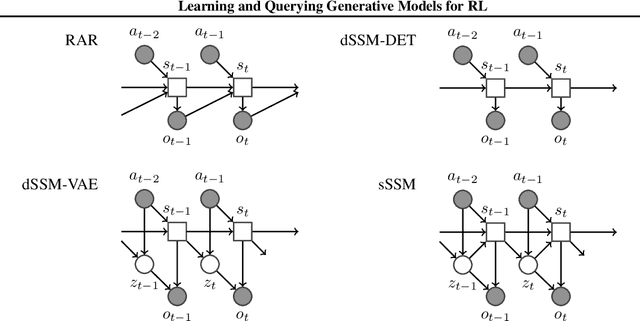

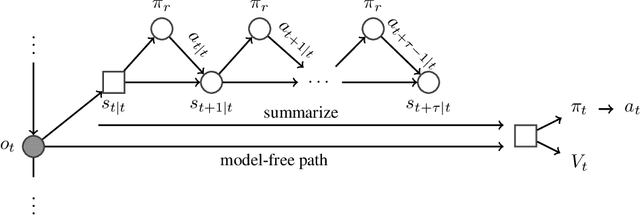
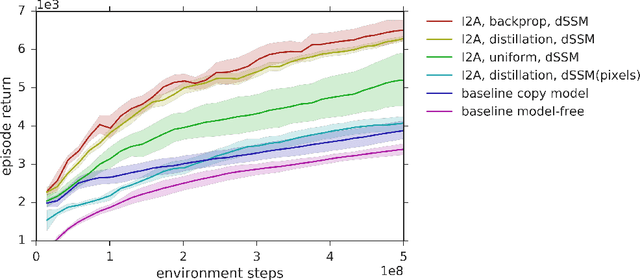
A key challenge in model-based reinforcement learning (RL) is to synthesize computationally efficient and accurate environment models. We show that carefully designed generative models that learn and operate on compact state representations, so-called state-space models, substantially reduce the computational costs for predicting outcomes of sequences of actions. Extensive experiments establish that state-space models accurately capture the dynamics of Atari games from the Arcade Learning Environment from raw pixels. The computational speed-up of state-space models while maintaining high accuracy makes their application in RL feasible: We demonstrate that agents which query these models for decision making outperform strong model-free baselines on the game MSPACMAN, demonstrating the potential of using learned environment models for planning.
Convolution by Evolution: Differentiable Pattern Producing Networks
Jun 08, 2016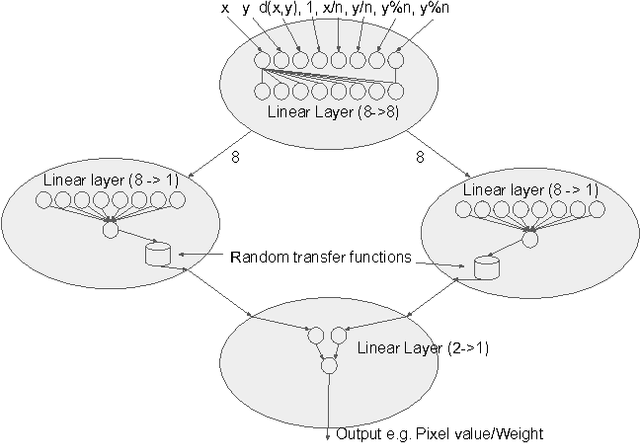



In this work we introduce a differentiable version of the Compositional Pattern Producing Network, called the DPPN. Unlike a standard CPPN, the topology of a DPPN is evolved but the weights are learned. A Lamarckian algorithm, that combines evolution and learning, produces DPPNs to reconstruct an image. Our main result is that DPPNs can be evolved/trained to compress the weights of a denoising autoencoder from 157684 to roughly 200 parameters, while achieving a reconstruction accuracy comparable to a fully connected network with more than two orders of magnitude more parameters. The regularization ability of the DPPN allows it to rediscover (approximate) convolutional network architectures embedded within a fully connected architecture. Such convolutional architectures are the current state of the art for many computer vision applications, so it is satisfying that DPPNs are capable of discovering this structure rather than having to build it in by design. DPPNs exhibit better generalization when tested on the Omniglot dataset after being trained on MNIST, than directly encoded fully connected autoencoders. DPPNs are therefore a new framework for integrating learning and evolution.
Towards Conceptual Compression
Apr 29, 2016



We introduce a simple recurrent variational auto-encoder architecture that significantly improves image modeling. The system represents the state-of-the-art in latent variable models for both the ImageNet and Omniglot datasets. We show that it naturally separates global conceptual information from lower level details, thus addressing one of the fundamentally desired properties of unsupervised learning. Furthermore, the possibility of restricting ourselves to storing only global information about an image allows us to achieve high quality 'conceptual compression'.