 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversality of first-order methods on random and deterministic matrices
Apr 13, 2026General first-order methods (GFOM) are a flexible class of iterative algorithms which update a state vector by matrix-vector multiplications and entrywise nonlinearities. A long line of work has sought to understand the large-n dynamics of GFOM, mostly focusing on "very random" input matrices and the approximate message passing (AMP) special case of GFOM whose state is asymptotically Gaussian. Yet, it has long remained unknown how to construct iterative algorithms that retain this Gaussianity for more structured inputs, or why existing AMP algorithms can be as effective for some deterministic matrices as they are for random matrices. We analyze diagrammatic expansions of GFOM via the limiting traffic distribution of the input matrix, the collection of all limiting values of permutation-invariant polynomials in the matrix entries, to obtain the following results: 1. We calculate the traffic distribution for the first non-trivial deterministic matrices, including (minor variants of) the Walsh-Hadamard and discrete sine and cosine transform matrices. This determines the limiting dynamics of GFOM on these inputs, resolving parts of longstanding conjectures of Marinari, Parisi, and Ritort (1994). 2. We design a new AMP iteration which unifies several previous AMP variants and generalizes to new input types, whose limiting dynamics are Gaussian conditional on some latent random variables. The asymptotic dynamics hold for a large and natural class of traffic distributions (encompassing both random and deterministic input matrices) and the algorithm's analysis gives a simple combinatorial interpretation of the Onsager correction, answering questions posed recently by Wang, Zhong, and Fan (2022).
Benchmarking Offline Reinforcement Learning Algorithms for E-Commerce Order Fraud Evaluation
Dec 05, 2022
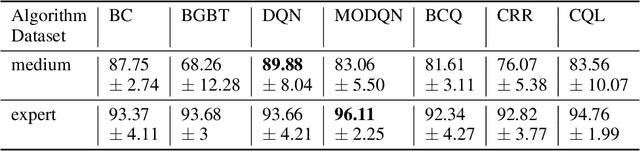

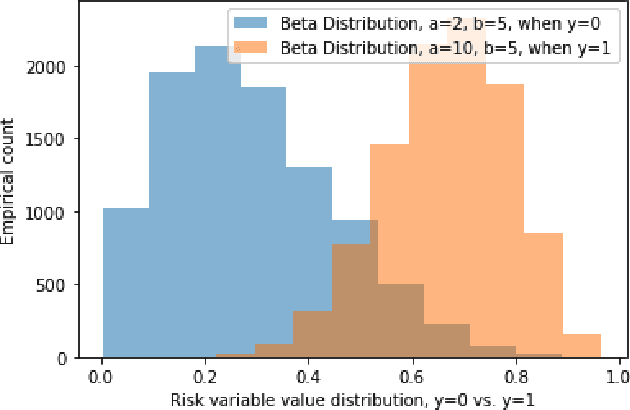
Amazon and other e-commerce sites must employ mechanisms to protect their millions of customers from fraud, such as unauthorized use of credit cards. One such mechanism is order fraud evaluation, where systems evaluate orders for fraud risk, and either "pass" the order, or take an action to mitigate high risk. Order fraud evaluation systems typically use binary classification models that distinguish fraudulent and legitimate orders, to assess risk and take action. We seek to devise a system that considers both financial losses of fraud and long-term customer satisfaction, which may be impaired when incorrect actions are applied to legitimate customers. We propose that taking actions to optimize long-term impact can be formulated as a Reinforcement Learning (RL) problem. Standard RL methods require online interaction with an environment to learn, but this is not desirable in high-stakes applications like order fraud evaluation. Offline RL algorithms learn from logged data collected from the environment, without the need for online interaction, making them suitable for our use case. We show that offline RL methods outperform traditional binary classification solutions in SimStore, a simplified e-commerce simulation that incorporates order fraud risk. We also propose a novel approach to training offline RL policies that adds a new loss term during training, to better align policy exploration with taking correct actions.
Unified Scaling Laws for Routed Language Models
Feb 09, 2022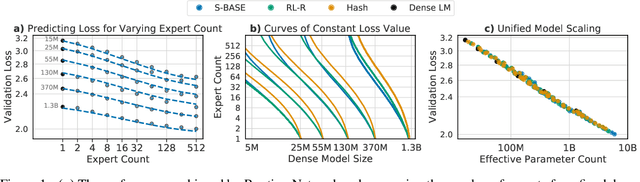

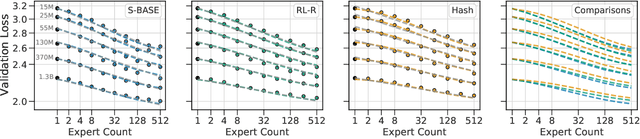
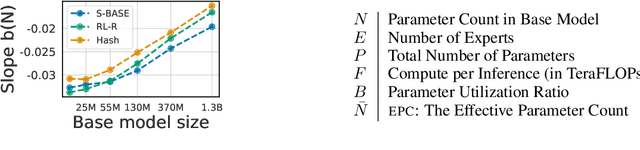
The performance of a language model has been shown to be effectively modeled as a power-law in its parameter count. Here we study the scaling behaviors of Routing Networks: architectures that conditionally use only a subset of their parameters while processing an input. For these models, parameter count and computational requirement form two independent axes along which an increase leads to better performance. In this work we derive and justify scaling laws defined on these two variables which generalize those known for standard language models and describe the performance of a wide range of routing architectures trained via three different techniques. Afterwards we provide two applications of these laws: first deriving an Effective Parameter Count along which all models scale at the same rate, and then using the scaling coefficients to give a quantitative comparison of the three routing techniques considered. Our analysis derives from an extensive evaluation of Routing Networks across five orders of magnitude of size, including models with hundreds of experts and hundreds of billions of parameters.
Improving language models by retrieving from trillions of tokens
Jan 11, 2022



We enhance auto-regressive language models by conditioning on document chunks retrieved from a large corpus, based on local similarity with preceding tokens. With a $2$ trillion token database, our Retrieval-Enhanced Transformer (RETRO) obtains comparable performance to GPT-3 and Jurassic-1 on the Pile, despite using 25$\times$ fewer parameters. After fine-tuning, RETRO performance translates to downstream knowledge-intensive tasks such as question answering. RETRO combines a frozen Bert retriever, a differentiable encoder and a chunked cross-attention mechanism to predict tokens based on an order of magnitude more data than what is typically consumed during training. We typically train RETRO from scratch, yet can also rapidly RETROfit pre-trained transformers with retrieval and still achieve good performance. Our work opens up new avenues for improving language models through explicit memory at unprecedented scale.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Dec 08, 2021



Language modelling provides a step towards intelligent communication systems by harnessing large repositories of written human knowledge to better predict and understand the world. In this paper, we present an analysis of Transformer-based language model performance across a wide range of model scales -- from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit. We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity. Finally we discuss the application of language models to AI safety and the mitigation of downstream harms.
TF-Replicator: Distributed Machine Learning for Researchers
Feb 01, 2019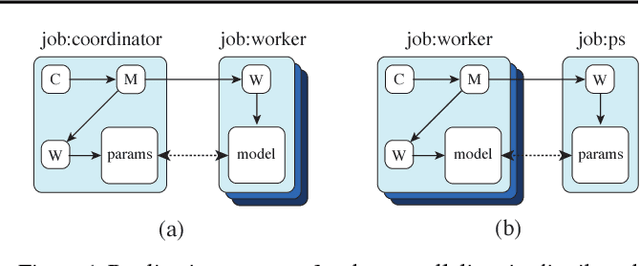

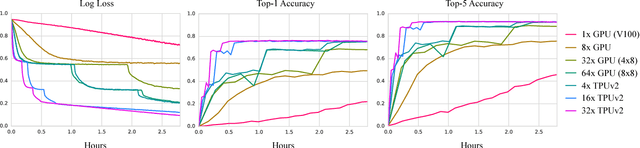
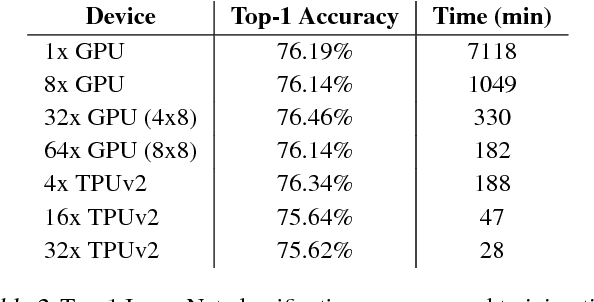
We describe TF-Replicator, a framework for distributed machine learning designed for DeepMind researchers and implemented as an abstraction over TensorFlow. TF-Replicator simplifies writing data-parallel and model-parallel research code. The same models can be effortlessly deployed to different cluster architectures (i.e. one or many machines containing CPUs, GPUs or TPU accelerators) using synchronous or asynchronous training regimes. To demonstrate the generality and scalability of TF-Replicator, we implement and benchmark three very different models: (1) A ResNet-50 for ImageNet classification, (2) a SN-GAN for class-conditional ImageNet image generation, and (3) a D4PG reinforcement learning agent for continuous control. Our results show strong scalability performance without demanding any distributed systems expertise of the user. The TF-Replicator programming model will be open-sourced as part of TensorFlow 2.0 (see https://github.com/tensorflow/community/pull/25).
Analysis of Dynamic Task Allocation in Multi-Robot Systems
Apr 27, 2006

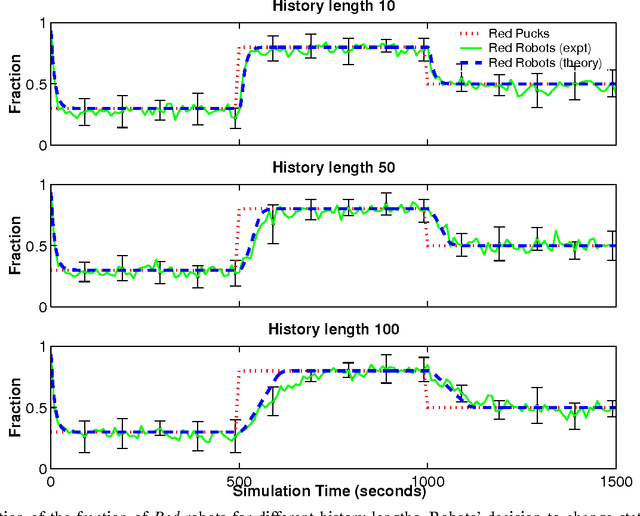
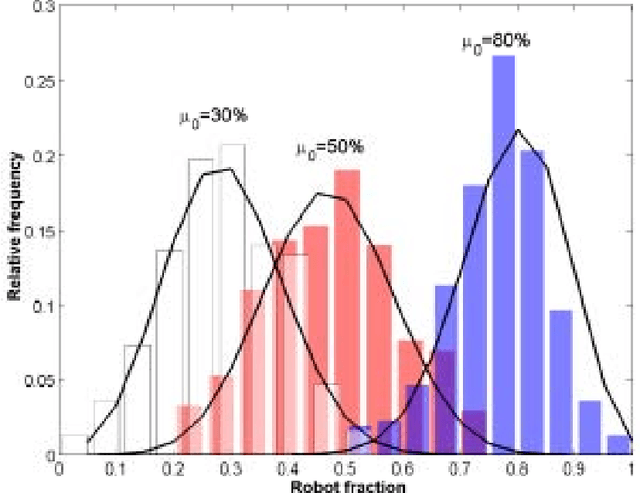
Dynamic task allocation is an essential requirement for multi-robot systems operating in unknown dynamic environments. It allows robots to change their behavior in response to environmental changes or actions of other robots in order to improve overall system performance. Emergent coordination algorithms for task allocation that use only local sensing and no direct communication between robots are attractive because they are robust and scalable. However, a lack of formal analysis tools makes emergent coordination algorithms difficult to design. In this paper we present a mathematical model of a general dynamic task allocation mechanism. Robots using this mechanism have to choose between two types of task, and the goal is to achieve a desired task division in the absence of explicit communication and global knowledge. Robots estimate the state of the environment from repeated local observations and decide which task to choose based on these observations. We model the robots and observations as stochastic processes and study the dynamics of the collective behavior. Specifically, we analyze the effect that the number of observations and the choice of the decision function have on the performance of the system. The mathematical models are validated in a multi-robot multi-foraging scenario. The model's predictions agree very closely with experimental results from sensor-based simulations.