 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCircling Back to Recurrent Models of Language
Nov 03, 2022Just because some purely recurrent models suffer from being hard to optimize and inefficient on today's hardware, they are not necessarily bad models of language. We demonstrate this by the extent to which these models can still be improved by a combination of a slightly better recurrent cell, architecture, objective, as well as optimization. In the process, we establish a new state of the art for language modelling on small datasets and on enwik8 with dynamic evaluation.
Two-Tailed Averaging: Anytime Adaptive Once-in-a-while Optimal Iterate Averaging for Stochastic Optimization
Sep 26, 2022

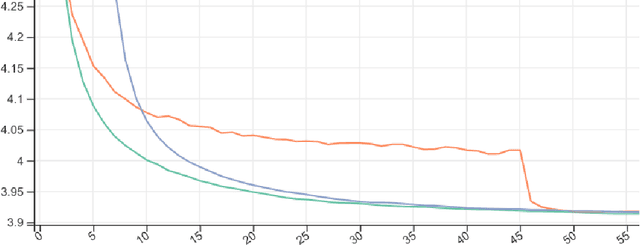

Tail averaging improves on Polyak averaging's non-asymptotic behaviour by excluding a number of leading iterates of stochastic optimization from its calculations. In practice, with a finite number of optimization steps and a learning rate that cannot be annealed to zero, tail averaging can get much closer to a local minimum point of the training loss than either the individual iterates or the Polyak average. However, the number of leading iterates to ignore is an important hyperparameter, and starting averaging too early or too late leads to inefficient use of resources or suboptimal solutions. Setting this hyperparameter to improve generalization is even more difficult, especially in the presence of other hyperparameters and overfitting. Furthermore, before averaging starts, the loss is only weakly informative of the final performance, which makes early stopping unreliable. To alleviate these problems, we propose an anytime variant of tail averaging, that has no hyperparameters and approximates the optimal tail at all optimization steps. Our algorithm is based on two running averages with adaptive lengths bounded in terms of the optimal tail length, one of which achieves approximate optimality with some regularity. Requiring only the additional storage for two sets of weights and periodic evaluation of the loss, the proposed two-tailed averaging algorithm is a practical and widely applicable method for improving stochastic optimization.
Mutual Information Constraints for Monte-Carlo Objectives
Dec 01, 2020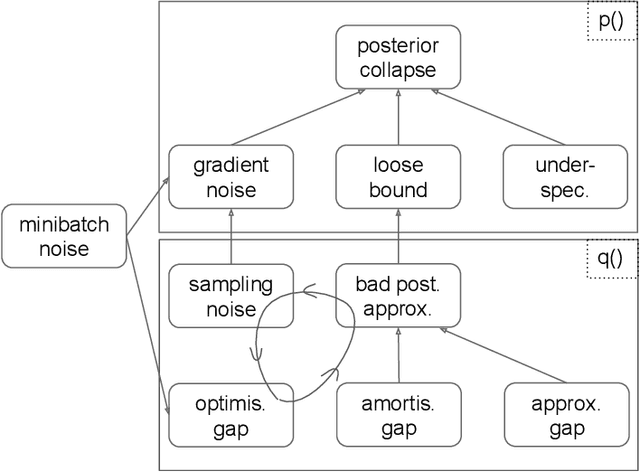

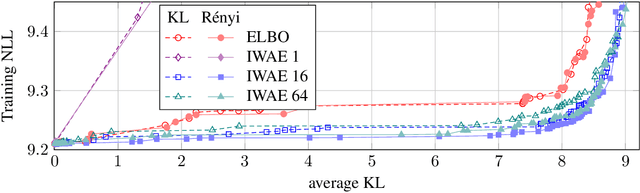
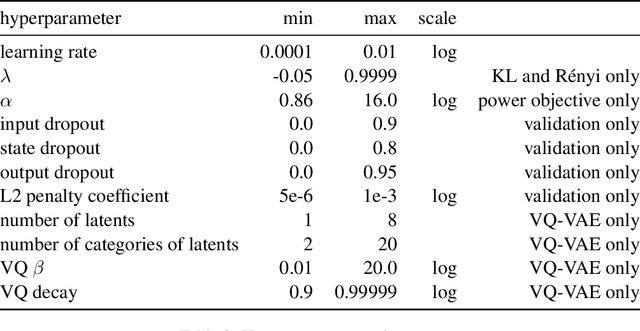
A common failure mode of density models trained as variational autoencoders is to model the data without relying on their latent variables, rendering these variables useless. Two contributing factors, the underspecification of the model and the looseness of the variational lower bound, have been studied separately in the literature. We weave these two strands of research together, specifically the tighter bounds of Monte-Carlo objectives and constraints on the mutual information between the observable and the latent variables. Estimating the mutual information as the average Kullback-Leibler divergence between the easily available variational posterior $q(z|x)$ and the prior does not work with Monte-Carlo objectives because $q(z|x)$ is no longer a direct approximation to the model's true posterior $p(z|x)$. Hence, we construct estimators of the Kullback-Leibler divergence of the true posterior from the prior by recycling samples used in the objective, with which we train models of continuous and discrete latents at much improved rate-distortion and no posterior collapse. While alleviated, the tradeoff between modelling the data and using the latents still remains, and we urge for evaluating inference methods across a range of mutual information values.
Capturing document context inside sentence-level neural machine translation models with self-training
Mar 11, 2020
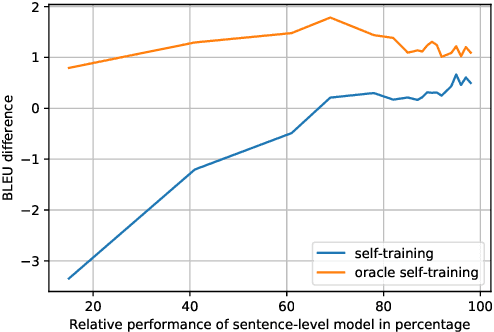


Neural machine translation (NMT) has arguably achieved human level parity when trained and evaluated at the sentence-level. Document-level neural machine translation has received less attention and lags behind its sentence-level counterpart. The majority of the proposed document-level approaches investigate ways of conditioning the model on several source or target sentences to capture document context. These approaches require training a specialized NMT model from scratch on parallel document-level corpora. We propose an approach that doesn't require training a specialized model on parallel document-level corpora and is applied to a trained sentence-level NMT model at decoding time. We process the document from left to right multiple times and self-train the sentence-level model on pairs of source sentences and generated translations. Our approach reinforces the choices made by the model, thus making it more likely that the same choices will be made in other sentences in the document. We evaluate our approach on three document-level datasets: NIST Chinese-English, WMT'19 Chinese-English and OpenSubtitles English-Russian. We demonstrate that our approach has higher BLEU score and higher human preference than the baseline. Qualitative analysis of our approach shows that choices made by model are consistent across the document.
A Critical Analysis of Biased Parsers in Unsupervised Parsing
Sep 20, 2019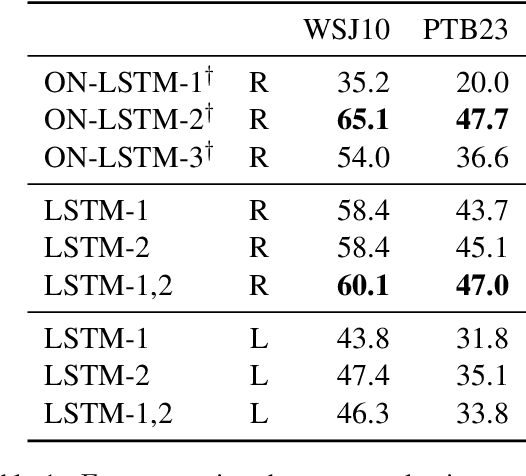

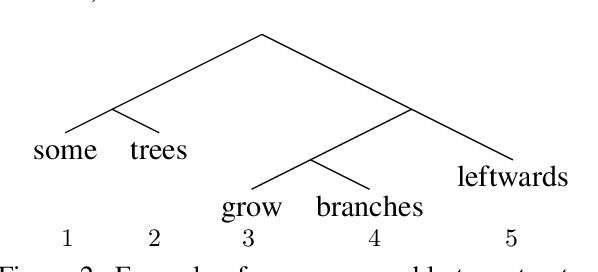

A series of recent papers has used a parsing algorithm due to Shen et al. (2018) to recover phrase-structure trees based on proxies for "syntactic depth." These proxy depths are obtained from the representations learned by recurrent language models augmented with mechanisms that encourage the (unsupervised) discovery of hierarchical structure latent in natural language sentences. Using the same parser, we show that proxies derived from a conventional LSTM language model produce trees comparably well to the specialized architectures used in previous work. However, we also provide a detailed analysis of the parsing algorithm, showing (1) that it is incomplete---that is, it can recover only a fraction of possible trees---and (2) that it has a marked bias for right-branching structures which results in inflated performance in right-branching languages like English. Our analysis shows that evaluating with biased parsing algorithms can inflate the apparent structural competence of language models.
Mogrifier LSTM
Sep 04, 2019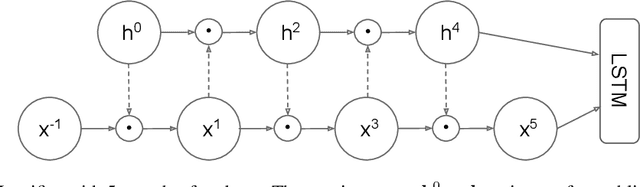
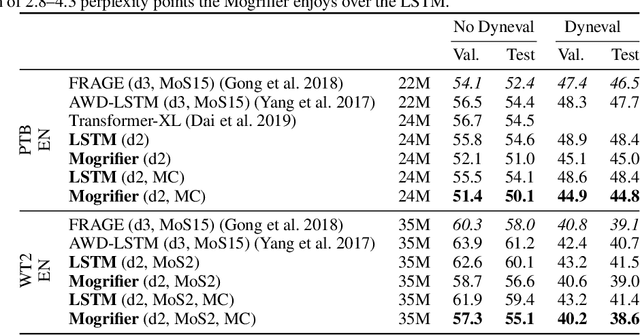
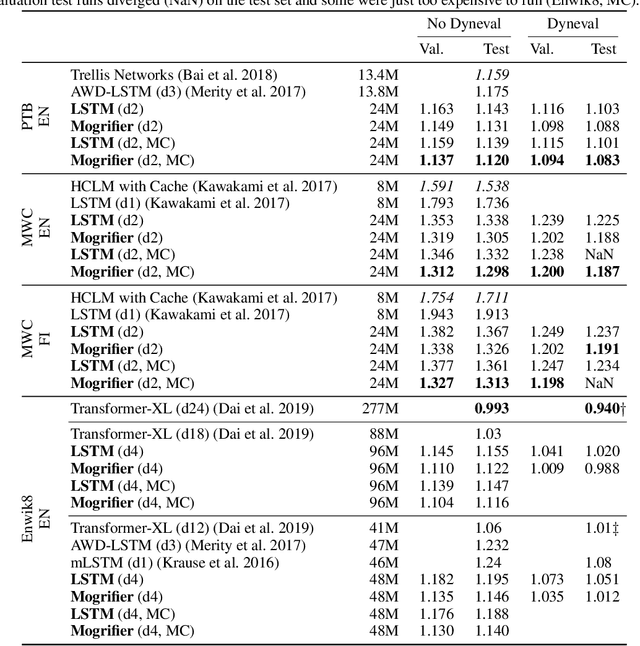
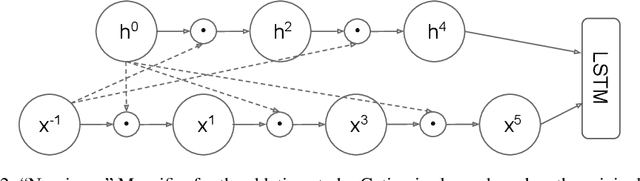
Many advances in Natural Language Processing have been based upon more expressive models for how inputs interact with the context in which they occur. Recurrent networks, which have enjoyed a modicum of success, still lack the generalization and systematicity ultimately required for modelling language. In this work, we propose an extension to the venerable Long Short-Term Memory in the form of mutual gating of the current input and the previous output. This mechanism affords the modelling of a richer space of interactions between inputs and their context. Equivalently, our model can be viewed as making the transition function given by the LSTM context-dependent. Experiments demonstrate markedly improved generalization on language modelling in the range of 3-4 perplexity points on Penn Treebank and Wikitext-2, and 0.01-0.05 bpc on four character-based datasets. We establish a new state of the art on all datasets with the exception of Enwik8, where we close a large gap between the LSTM and Transformer models.
Unsupervised Recurrent Neural Network Grammars
Apr 15, 2019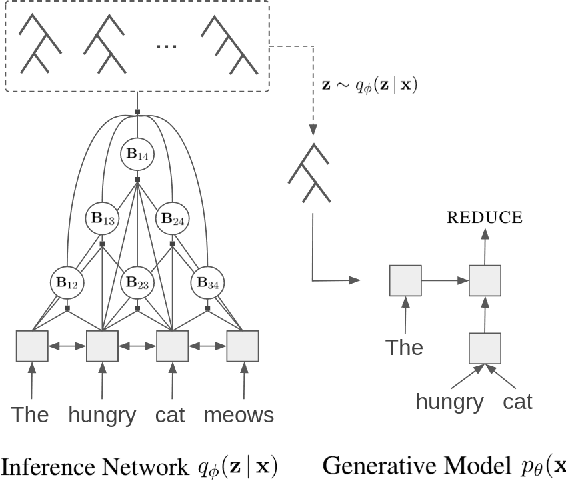

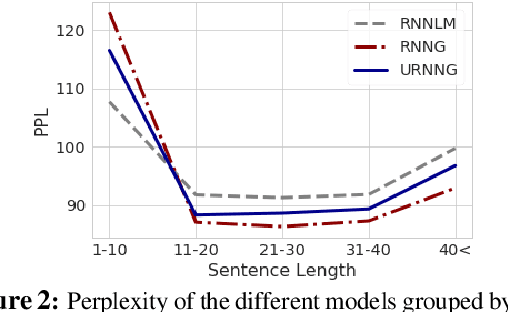
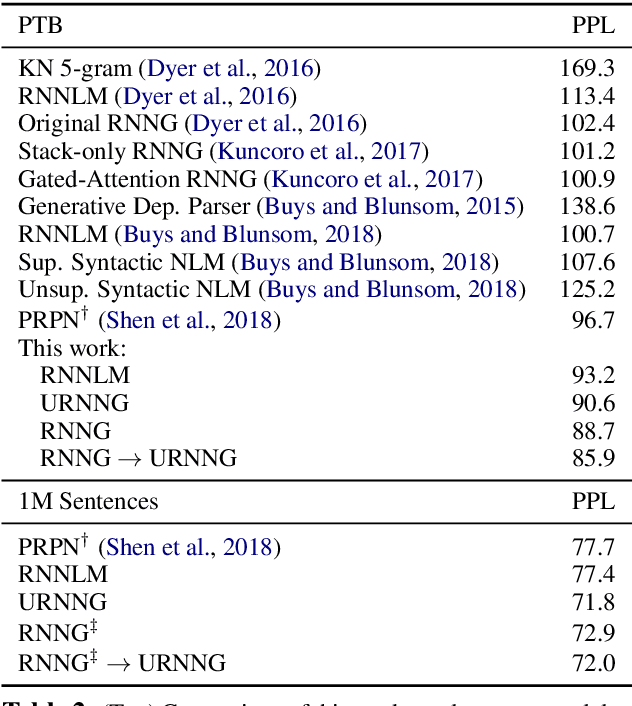
Recurrent neural network grammars (RNNG) are generative models of language which jointly model syntax and surface structure by incrementally generating a syntax tree and sentence in a top-down, left-to-right order. Supervised RNNGs achieve strong language modeling and parsing performance, but require an annotated corpus of parse trees. In this work, we experiment with unsupervised learning of RNNGs. Since directly marginalizing over the space of latent trees is intractable, we instead apply amortized variational inference. To maximize the evidence lower bound, we develop an inference network parameterized as a neural CRF constituency parser. On language modeling, unsupervised RNNGs perform as well their supervised counterparts on benchmarks in English and Chinese. On constituency grammar induction, they are competitive with recent neural language models that induce tree structures from words through attention mechanisms.
Pushing the bounds of dropout
Sep 27, 2018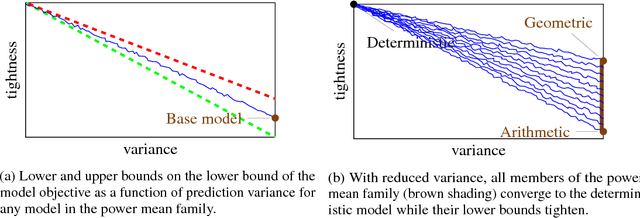

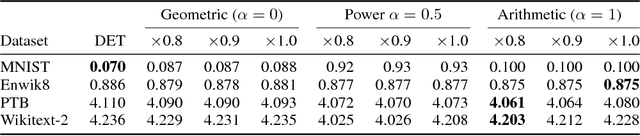
We show that dropout training is best understood as performing MAP estimation concurrently for a family of conditional models whose objectives are themselves lower bounded by the original dropout objective. This discovery allows us to pick any model from this family after training, which leads to a substantial improvement on regularisation-heavy language modelling. The family includes models that compute a power mean over the sampled dropout masks, and their less stochastic subvariants with tighter and higher lower bounds than the fully stochastic dropout objective. We argue that since the deterministic subvariant's bound is equal to its objective, and the highest amongst these models, the predominant view of it as a good approximation to MC averaging is misleading. Rather, deterministic dropout is the best available approximation to the true objective.
Encoding Spatial Relations from Natural Language
Jul 05, 2018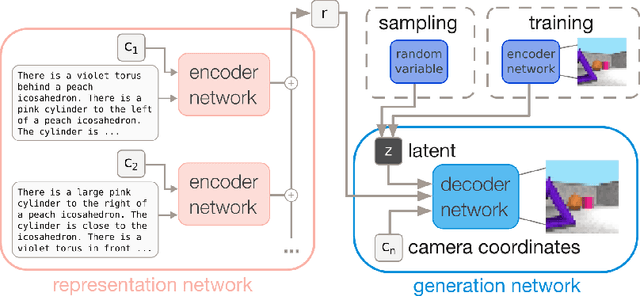

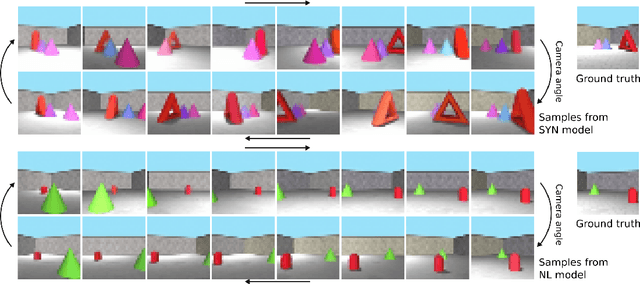
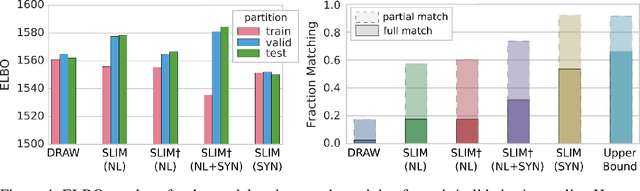
Natural language processing has made significant inroads into learning the semantics of words through distributional approaches, however representations learnt via these methods fail to capture certain kinds of information implicit in the real world. In particular, spatial relations are encoded in a way that is inconsistent with human spatial reasoning and lacking invariance to viewpoint changes. We present a system capable of capturing the semantics of spatial relations such as behind, left of, etc from natural language. Our key contributions are a novel multi-modal objective based on generating images of scenes from their textual descriptions, and a new dataset on which to train it. We demonstrate that internal representations are robust to meaning preserving transformations of descriptions (paraphrase invariance), while viewpoint invariance is an emergent property of the system.
The NarrativeQA Reading Comprehension Challenge
Dec 19, 2017Reading comprehension (RC)---in contrast to information retrieval---requires integrating information and reasoning about events, entities, and their relations across a full document. Question answering is conventionally used to assess RC ability, in both artificial agents and children learning to read. However, existing RC datasets and tasks are dominated by questions that can be solved by selecting answers using superficial information (e.g., local context similarity or global term frequency); they thus fail to test for the essential integrative aspect of RC. To encourage progress on deeper comprehension of language, we present a new dataset and set of tasks in which the reader must answer questions about stories by reading entire books or movie scripts. These tasks are designed so that successfully answering their questions requires understanding the underlying narrative rather than relying on shallow pattern matching or salience. We show that although humans solve the tasks easily, standard RC models struggle on the tasks presented here. We provide an analysis of the dataset and the challenges it presents.