 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Critical Analysis of Biased Parsers in Unsupervised Parsing
Paper and Code
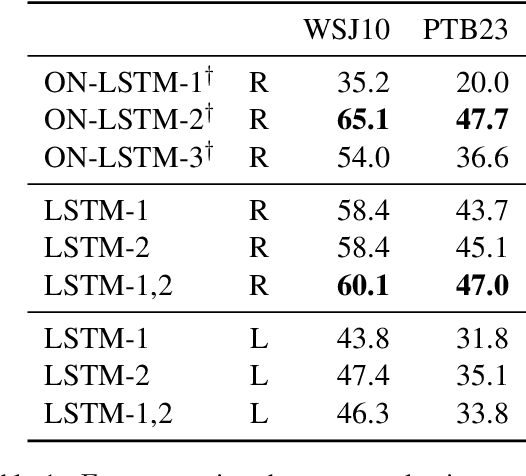

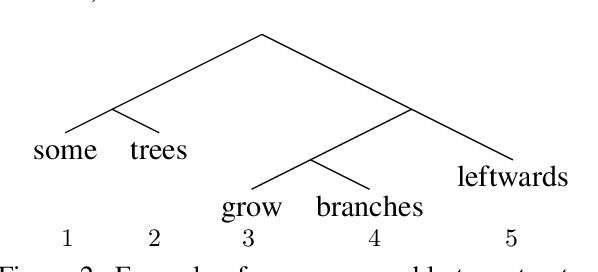

A series of recent papers has used a parsing algorithm due to Shen et al. (2018) to recover phrase-structure trees based on proxies for "syntactic depth." These proxy depths are obtained from the representations learned by recurrent language models augmented with mechanisms that encourage the (unsupervised) discovery of hierarchical structure latent in natural language sentences. Using the same parser, we show that proxies derived from a conventional LSTM language model produce trees comparably well to the specialized architectures used in previous work. However, we also provide a detailed analysis of the parsing algorithm, showing (1) that it is incomplete---that is, it can recover only a fraction of possible trees---and (2) that it has a marked bias for right-branching structures which results in inflated performance in right-branching languages like English. Our analysis shows that evaluating with biased parsing algorithms can inflate the apparent structural competence of language models.