 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing document context inside sentence-level neural machine translation models with self-training
Paper and Code

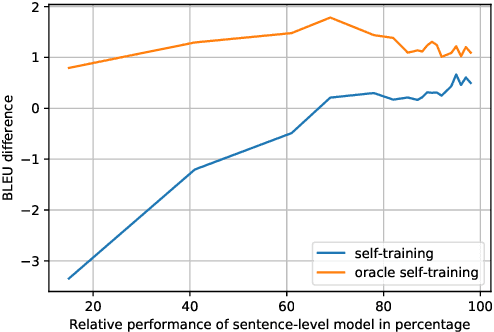


Neural machine translation (NMT) has arguably achieved human level parity when trained and evaluated at the sentence-level. Document-level neural machine translation has received less attention and lags behind its sentence-level counterpart. The majority of the proposed document-level approaches investigate ways of conditioning the model on several source or target sentences to capture document context. These approaches require training a specialized NMT model from scratch on parallel document-level corpora. We propose an approach that doesn't require training a specialized model on parallel document-level corpora and is applied to a trained sentence-level NMT model at decoding time. We process the document from left to right multiple times and self-train the sentence-level model on pairs of source sentences and generated translations. Our approach reinforces the choices made by the model, thus making it more likely that the same choices will be made in other sentences in the document. We evaluate our approach on three document-level datasets: NIST Chinese-English, WMT'19 Chinese-English and OpenSubtitles English-Russian. We demonstrate that our approach has higher BLEU score and higher human preference than the baseline. Qualitative analysis of our approach shows that choices made by model are consistent across the document.