 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Turn Puzzles: Evaluating Interactive Reasoning and Strategic Dialogue in LLMs
Aug 13, 2025Large language models (LLMs) excel at solving problems with clear and complete statements, but often struggle with nuanced environments or interactive tasks which are common in most real-world scenarios. This highlights the critical need for developing LLMs that can effectively engage in logically consistent multi-turn dialogue, seek information and reason with incomplete data. To this end, we introduce a novel benchmark comprising a suite of multi-turn tasks each designed to test specific reasoning, interactive dialogue, and information-seeking abilities. These tasks have deterministic scoring mechanisms, thus eliminating the need for human intervention. Evaluating frontier models on our benchmark reveals significant headroom. Our analysis shows that most errors emerge from poor instruction following, reasoning failures, and poor planning. This benchmark provides valuable insights into the strengths and weaknesses of current LLMs in handling complex, interactive scenarios and offers a robust platform for future research aimed at improving these critical capabilities.
StreamingQA: A Benchmark for Adaptation to New Knowledge over Time in Question Answering Models
May 23, 2022
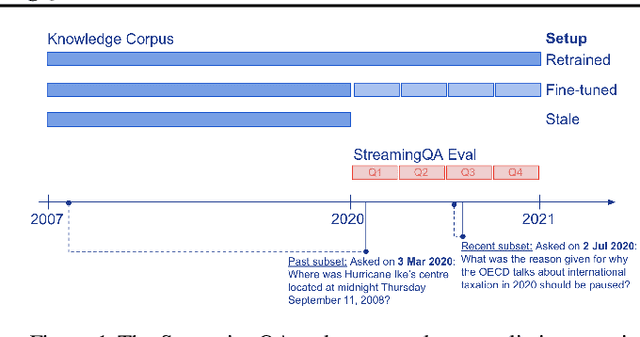

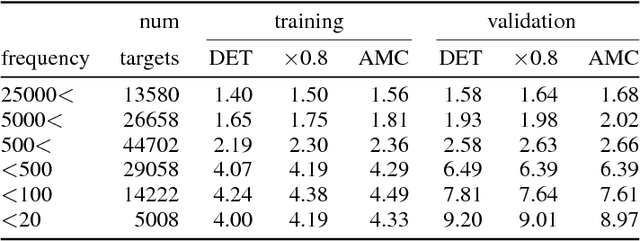
Knowledge and language understanding of models evaluated through question answering (QA) has been usually studied on static snapshots of knowledge, like Wikipedia. However, our world is dynamic, evolves over time, and our models' knowledge becomes outdated. To study how semi-parametric QA models and their underlying parametric language models (LMs) adapt to evolving knowledge, we construct a new large-scale dataset, StreamingQA, with human written and generated questions asked on a given date, to be answered from 14 years of time-stamped news articles. We evaluate our models quarterly as they read new articles not seen in pre-training. We show that parametric models can be updated without full retraining, while avoiding catastrophic forgetting. For semi-parametric models, adding new articles into the search space allows for rapid adaptation, however, models with an outdated underlying LM under-perform those with a retrained LM. For questions about higher-frequency named entities, parametric updates are particularly beneficial. In our dynamic world, the StreamingQA dataset enables a more realistic evaluation of QA models, and our experiments highlight several promising directions for future research.
Mogrifier LSTM
Sep 04, 2019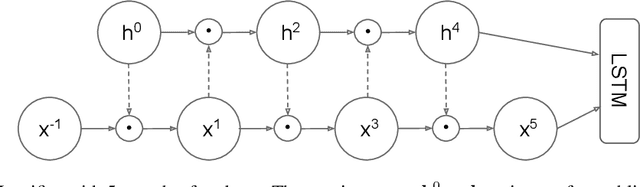
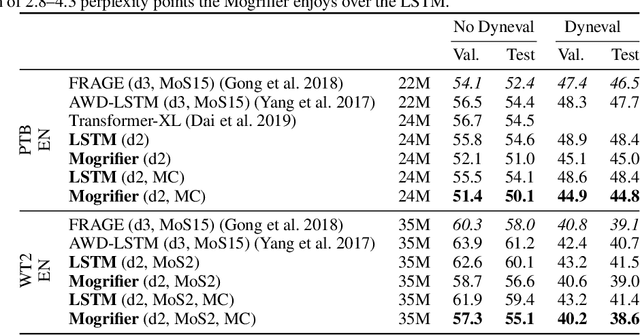
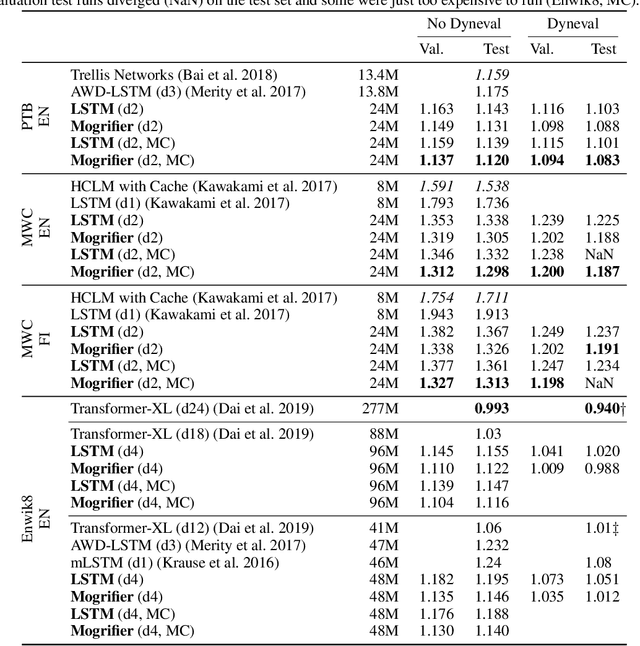
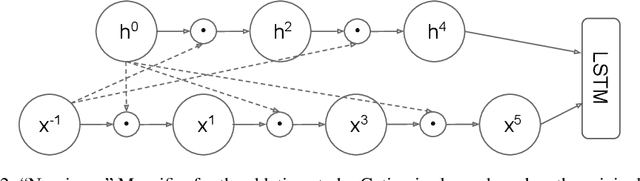
Many advances in Natural Language Processing have been based upon more expressive models for how inputs interact with the context in which they occur. Recurrent networks, which have enjoyed a modicum of success, still lack the generalization and systematicity ultimately required for modelling language. In this work, we propose an extension to the venerable Long Short-Term Memory in the form of mutual gating of the current input and the previous output. This mechanism affords the modelling of a richer space of interactions between inputs and their context. Equivalently, our model can be viewed as making the transition function given by the LSTM context-dependent. Experiments demonstrate markedly improved generalization on language modelling in the range of 3-4 perplexity points on Penn Treebank and Wikitext-2, and 0.01-0.05 bpc on four character-based datasets. We establish a new state of the art on all datasets with the exception of Enwik8, where we close a large gap between the LSTM and Transformer models.
Pushing the bounds of dropout
Sep 27, 2018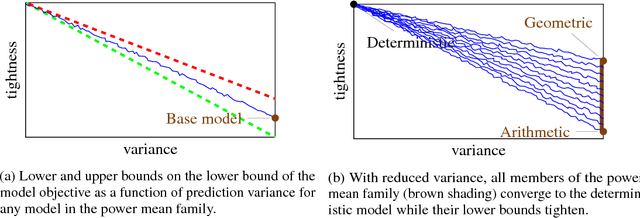

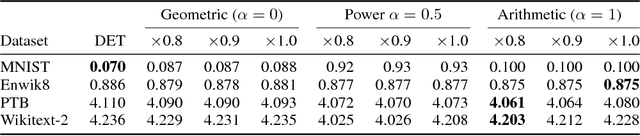
We show that dropout training is best understood as performing MAP estimation concurrently for a family of conditional models whose objectives are themselves lower bounded by the original dropout objective. This discovery allows us to pick any model from this family after training, which leads to a substantial improvement on regularisation-heavy language modelling. The family includes models that compute a power mean over the sampled dropout masks, and their less stochastic subvariants with tighter and higher lower bounds than the fully stochastic dropout objective. We argue that since the deterministic subvariant's bound is equal to its objective, and the highest amongst these models, the predominant view of it as a good approximation to MC averaging is misleading. Rather, deterministic dropout is the best available approximation to the true objective.
Dynamic Integration of Background Knowledge in Neural NLU Systems
Aug 21, 2018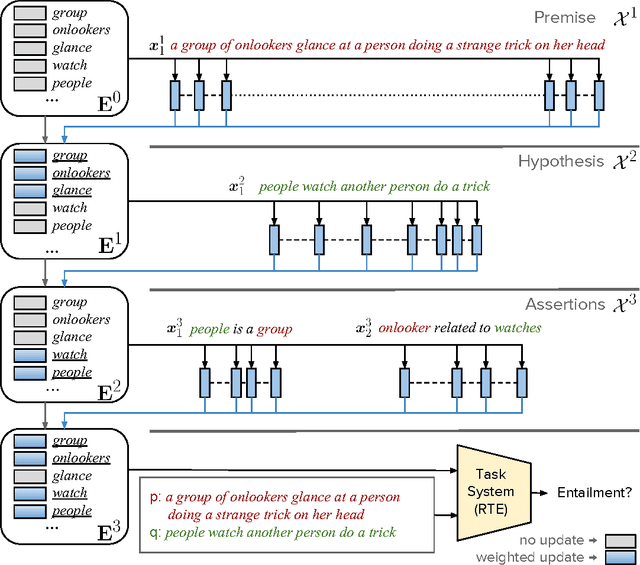
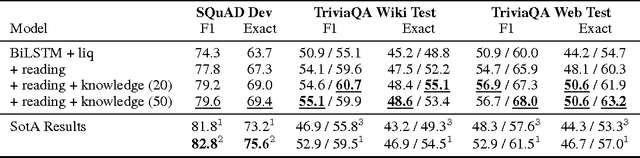
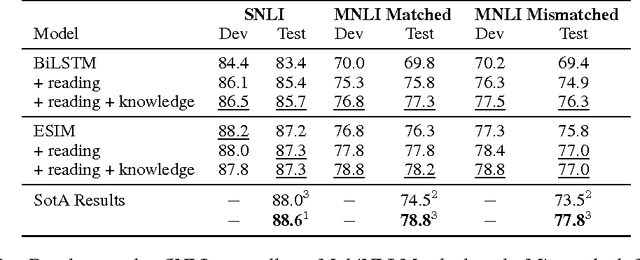
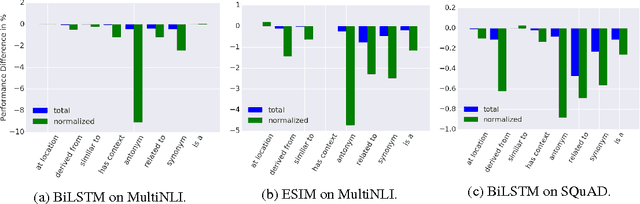
Common-sense and background knowledge is required to understand natural language, but in most neural natural language understanding (NLU) systems, this knowledge must be acquired from training corpora during learning, and then it is static at test time. We introduce a new architecture for the dynamic integration of explicit background knowledge in NLU models. A general-purpose reading module reads background knowledge in the form of free-text statements (together with task-specific text inputs) and yields refined word representations to a task-specific NLU architecture that reprocesses the task inputs with these representations. Experiments on document question answering (DQA) and recognizing textual entailment (RTE) demonstrate the effectiveness and flexibility of the approach. Analysis shows that our model learns to exploit knowledge in a semantically appropriate way.
Encoding Spatial Relations from Natural Language
Jul 05, 2018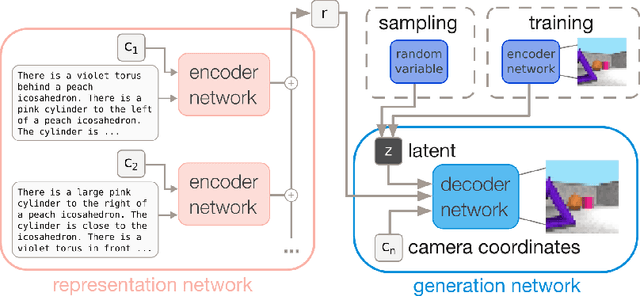

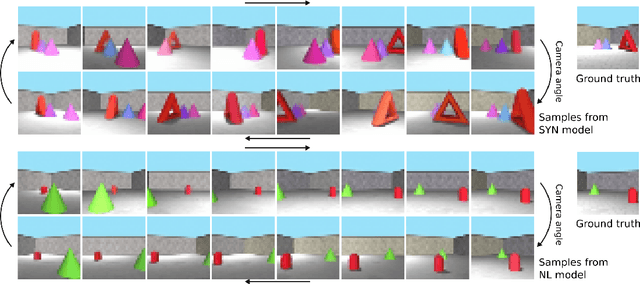
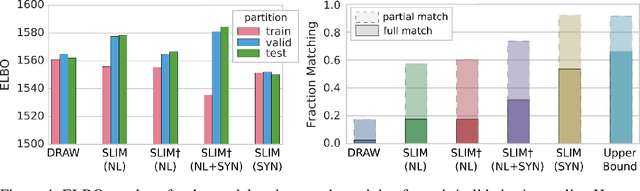
Natural language processing has made significant inroads into learning the semantics of words through distributional approaches, however representations learnt via these methods fail to capture certain kinds of information implicit in the real world. In particular, spatial relations are encoded in a way that is inconsistent with human spatial reasoning and lacking invariance to viewpoint changes. We present a system capable of capturing the semantics of spatial relations such as behind, left of, etc from natural language. Our key contributions are a novel multi-modal objective based on generating images of scenes from their textual descriptions, and a new dataset on which to train it. We demonstrate that internal representations are robust to meaning preserving transformations of descriptions (paraphrase invariance), while viewpoint invariance is an emergent property of the system.
The NarrativeQA Reading Comprehension Challenge
Dec 19, 2017Reading comprehension (RC)---in contrast to information retrieval---requires integrating information and reasoning about events, entities, and their relations across a full document. Question answering is conventionally used to assess RC ability, in both artificial agents and children learning to read. However, existing RC datasets and tasks are dominated by questions that can be solved by selecting answers using superficial information (e.g., local context similarity or global term frequency); they thus fail to test for the essential integrative aspect of RC. To encourage progress on deeper comprehension of language, we present a new dataset and set of tasks in which the reader must answer questions about stories by reading entire books or movie scripts. These tasks are designed so that successfully answering their questions requires understanding the underlying narrative rather than relying on shallow pattern matching or salience. We show that although humans solve the tasks easily, standard RC models struggle on the tasks presented here. We provide an analysis of the dataset and the challenges it presents.
Semantic Parsing with Semi-Supervised Sequential Autoencoders
Sep 29, 2016
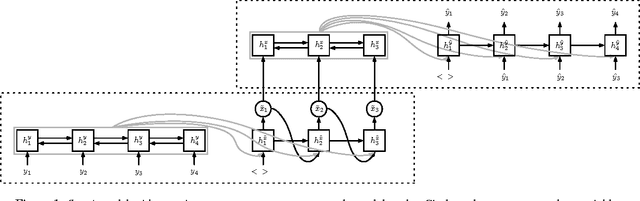
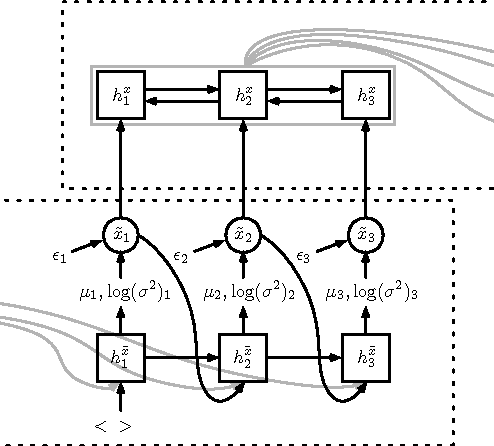
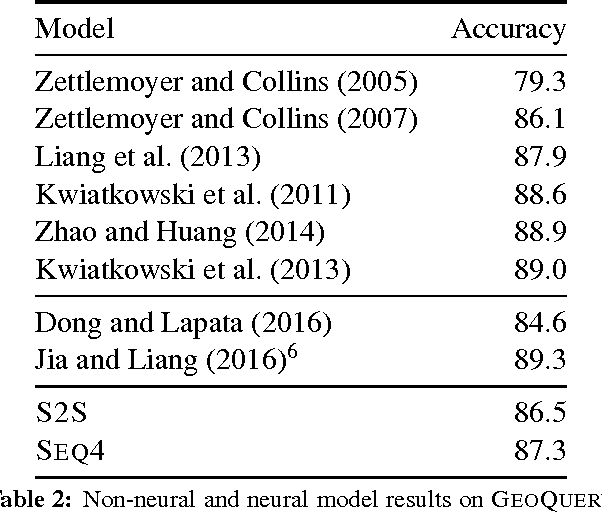
We present a novel semi-supervised approach for sequence transduction and apply it to semantic parsing. The unsupervised component is based on a generative model in which latent sentences generate the unpaired logical forms. We apply this method to a number of semantic parsing tasks focusing on domains with limited access to labelled training data and extend those datasets with synthetically generated logical forms.
Latent Predictor Networks for Code Generation
Jun 08, 2016
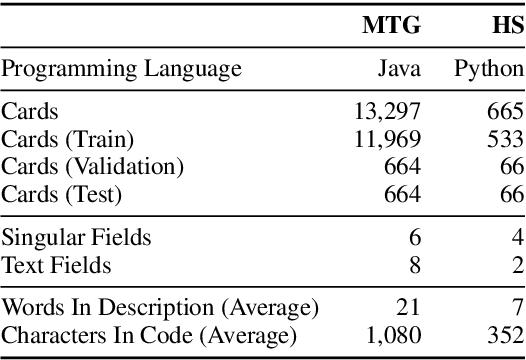


Many language generation tasks require the production of text conditioned on both structured and unstructured inputs. We present a novel neural network architecture which generates an output sequence conditioned on an arbitrary number of input functions. Crucially, our approach allows both the choice of conditioning context and the granularity of generation, for example characters or tokens, to be marginalised, thus permitting scalable and effective training. Using this framework, we address the problem of generating programming code from a mixed natural language and structured specification. We create two new data sets for this paradigm derived from the collectible trading card games Magic the Gathering and Hearthstone. On these, and a third preexisting corpus, we demonstrate that marginalising multiple predictors allows our model to outperform strong benchmarks.
Reasoning about Entailment with Neural Attention
Mar 01, 2016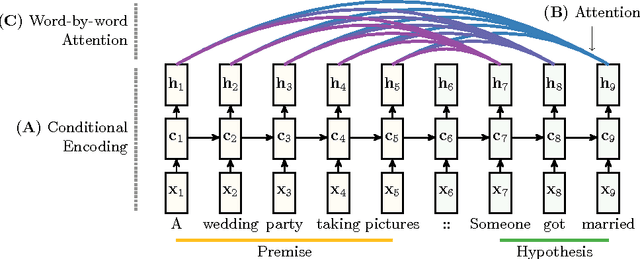
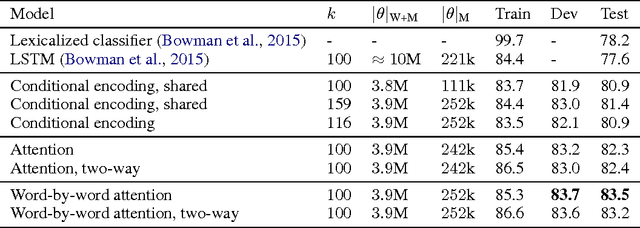
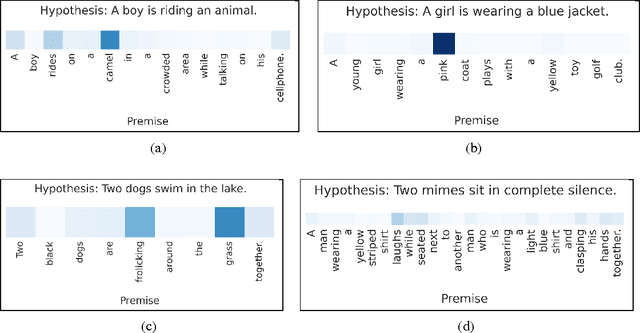
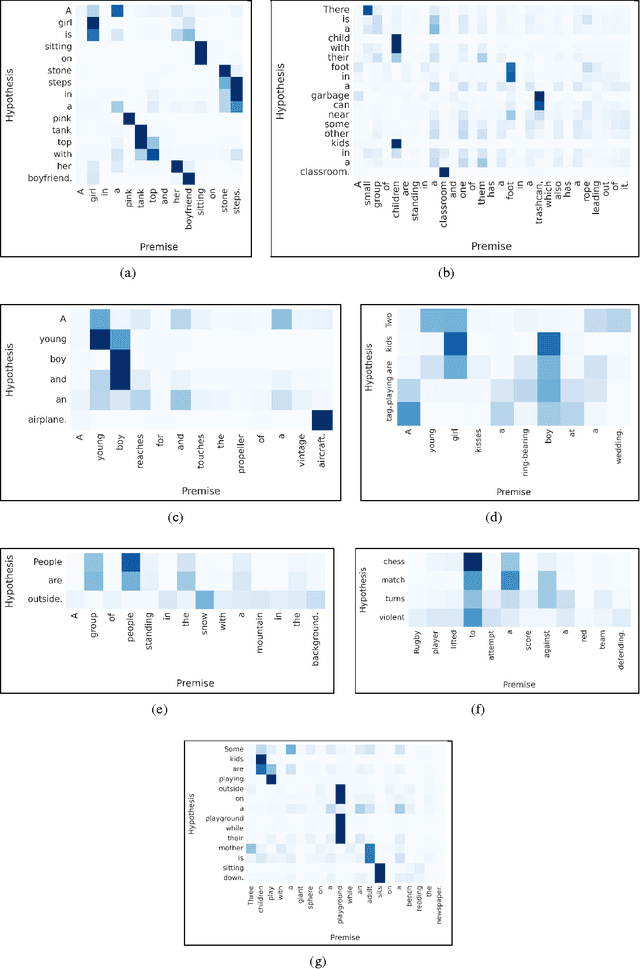
While most approaches to automatically recognizing entailment relations have used classifiers employing hand engineered features derived from complex natural language processing pipelines, in practice their performance has been only slightly better than bag-of-word pair classifiers using only lexical similarity. The only attempt so far to build an end-to-end differentiable neural network for entailment failed to outperform such a simple similarity classifier. In this paper, we propose a neural model that reads two sentences to determine entailment using long short-term memory units. We extend this model with a word-by-word neural attention mechanism that encourages reasoning over entailments of pairs of words and phrases. Furthermore, we present a qualitative analysis of attention weights produced by this model, demonstrating such reasoning capabilities. On a large entailment dataset this model outperforms the previous best neural model and a classifier with engineered features by a substantial margin. It is the first generic end-to-end differentiable system that achieves state-of-the-art accuracy on a textual entailment dataset.