 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn empirical study of pretrained representations for few-shot classification
Oct 03, 2019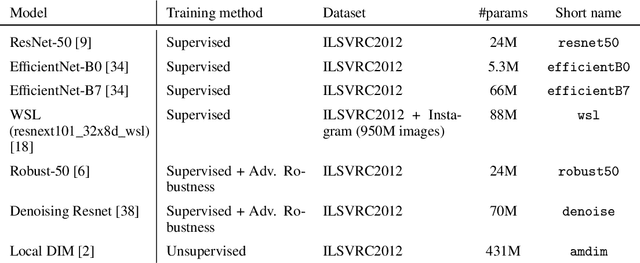
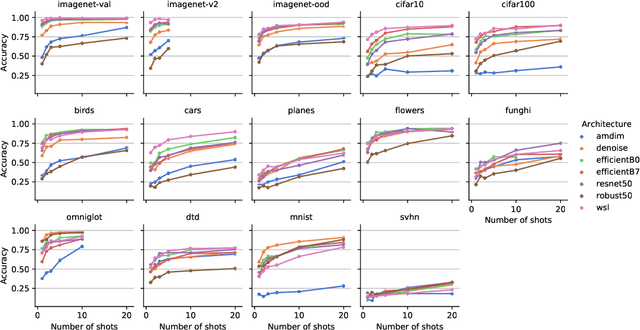
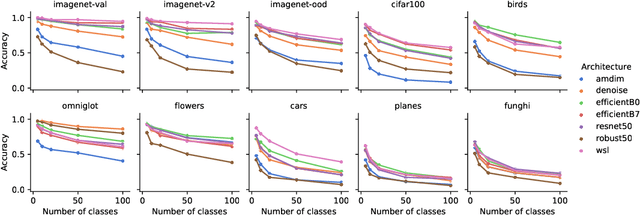
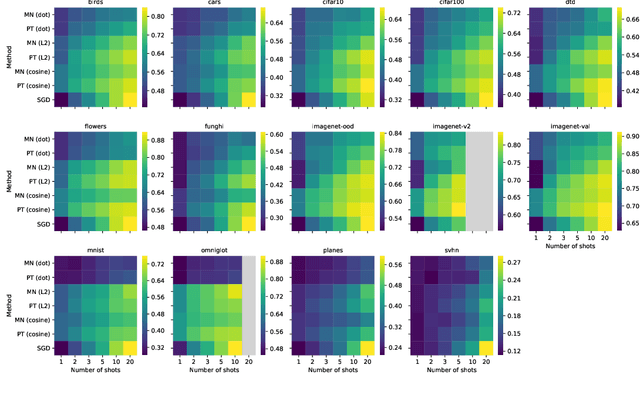
Recent algorithms with state-of-the-art few-shot classification results start their procedure by computing data features output by a large pretrained model. In this paper we systematically investigate which models provide the best representations for a few-shot image classification task when pretrained on the Imagenet dataset. We test their representations when used as the starting point for different few-shot classification algorithms. We observe that models trained on a supervised classification task have higher performance than models trained in an unsupervised manner even when transferred to out-of-distribution datasets. Models trained with adversarial robustness transfer better, while having slightly lower accuracy than supervised models.
Density estimation in representation space to predict model uncertainty
Oct 03, 2019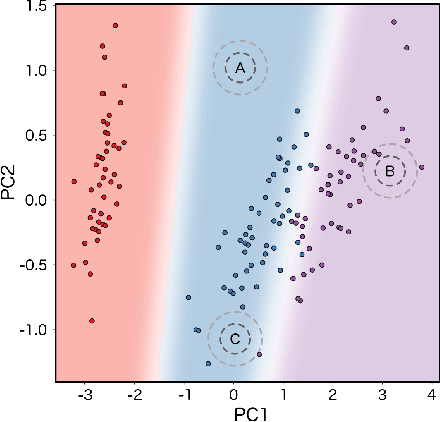
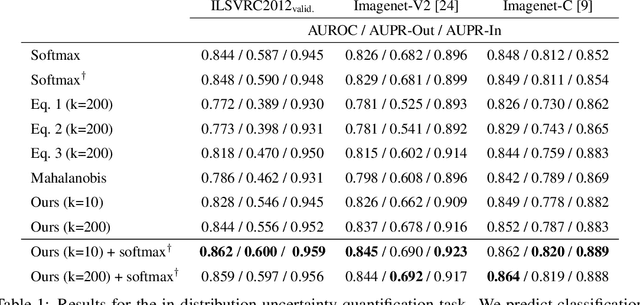
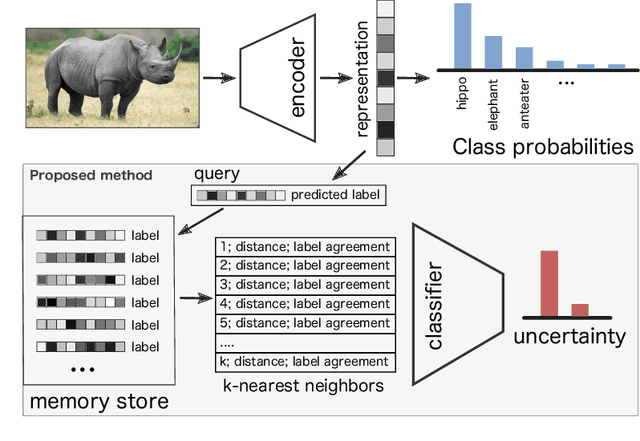
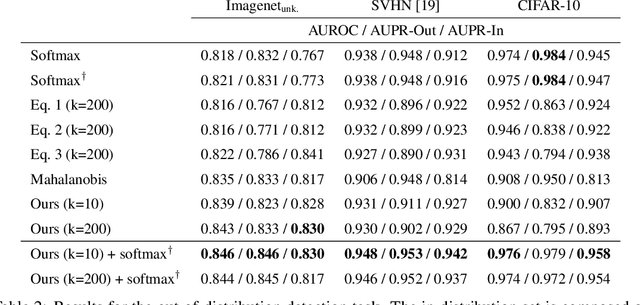
Deep learning models frequently make incorrect predictions with high confidence when presented with test examples that are not well represented in their training dataset. We propose a novel and straightforward approach to estimate prediction uncertainty in a pre-trained neural network model. Our method estimates the training data density in representation space for a novel input. A neural network model then uses this information to determine whether we expect the pre-trained model to make a correct prediction. This uncertainty model is trained by predicting in-distribution errors, but can detect out-of-distribution data without having seen any such example. We test our method for a state-of-the art image classification model in the settings of both in-distribution uncertainty estimation as well as out-of-distribution detection.
Adaptive Posterior Learning: few-shot learning with a surprise-based memory module
Feb 07, 2019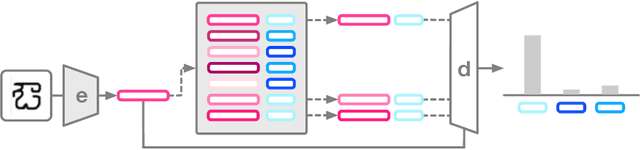
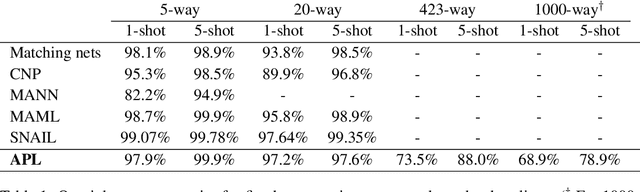

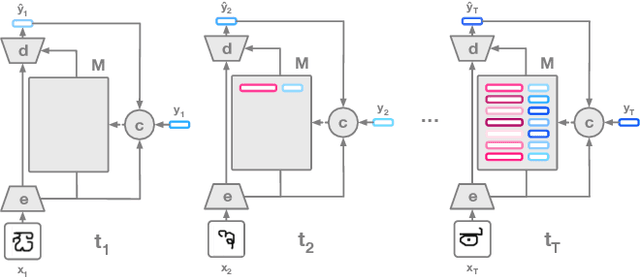
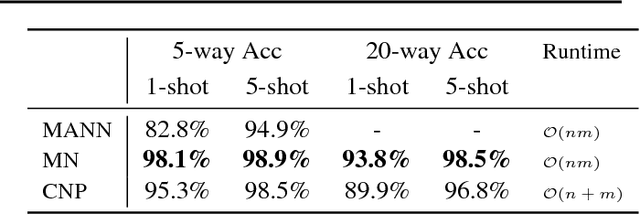
The ability to generalize quickly from few observations is crucial for intelligent systems. In this paper we introduce APL, an algorithm that approximates probability distributions by remembering the most surprising observations it has encountered. These past observations are recalled from an external memory module and processed by a decoder network that can combine information from different memory slots to generalize beyond direct recall. We show this algorithm can perform as well as state of the art baselines on few-shot classification benchmarks with a smaller memory footprint. In addition, its memory compression allows it to scale to thousands of unknown labels. Finally, we introduce a meta-learning reasoning task which is more challenging than direct classification. In this setting, APL is able to generalize with fewer than one example per class via deductive reasoning.
Encoding Spatial Relations from Natural Language
Jul 05, 2018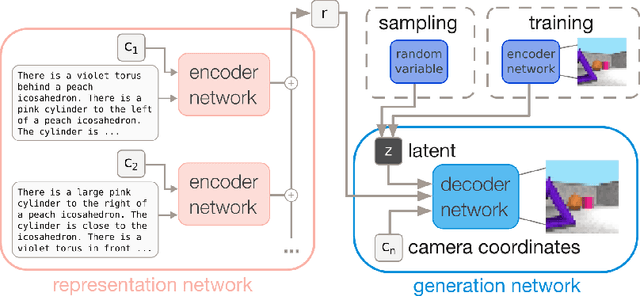

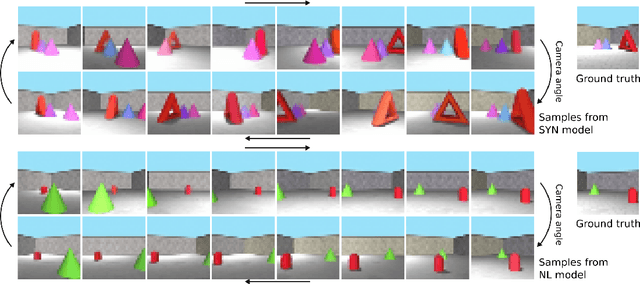
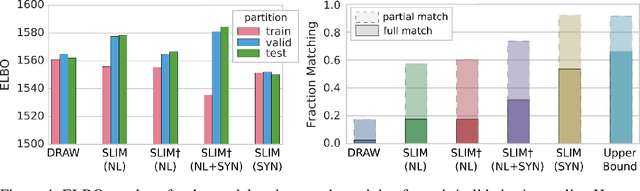
Natural language processing has made significant inroads into learning the semantics of words through distributional approaches, however representations learnt via these methods fail to capture certain kinds of information implicit in the real world. In particular, spatial relations are encoded in a way that is inconsistent with human spatial reasoning and lacking invariance to viewpoint changes. We present a system capable of capturing the semantics of spatial relations such as behind, left of, etc from natural language. Our key contributions are a novel multi-modal objective based on generating images of scenes from their textual descriptions, and a new dataset on which to train it. We demonstrate that internal representations are robust to meaning preserving transformations of descriptions (paraphrase invariance), while viewpoint invariance is an emergent property of the system.
Conditional Neural Processes
Jul 04, 2018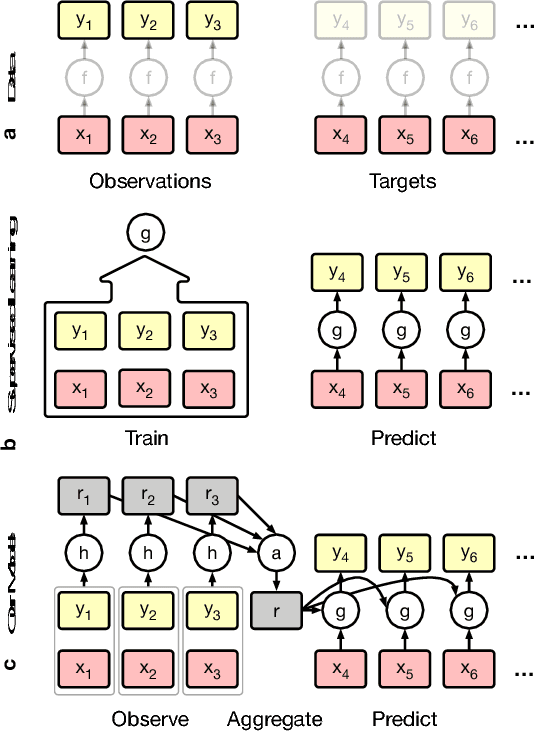
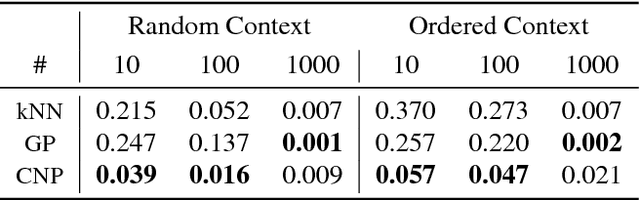
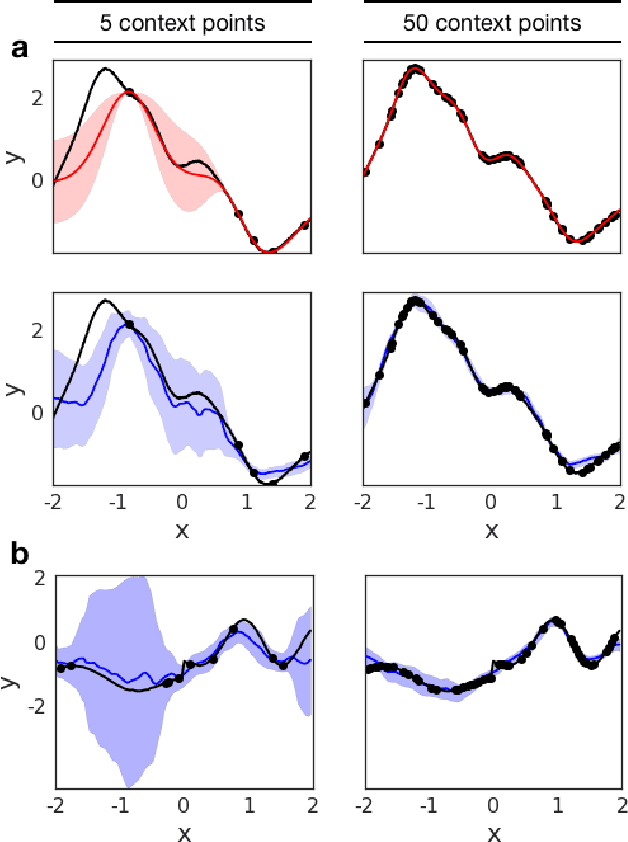
Deep neural networks excel at function approximation, yet they are typically trained from scratch for each new function. On the other hand, Bayesian methods, such as Gaussian Processes (GPs), exploit prior knowledge to quickly infer the shape of a new function at test time. Yet GPs are computationally expensive, and it can be hard to design appropriate priors. In this paper we propose a family of neural models, Conditional Neural Processes (CNPs), that combine the benefits of both. CNPs are inspired by the flexibility of stochastic processes such as GPs, but are structured as neural networks and trained via gradient descent. CNPs make accurate predictions after observing only a handful of training data points, yet scale to complex functions and large datasets. We demonstrate the performance and versatility of the approach on a range of canonical machine learning tasks, including regression, classification and image completion.
Overcoming catastrophic forgetting in neural networks
Jan 25, 2017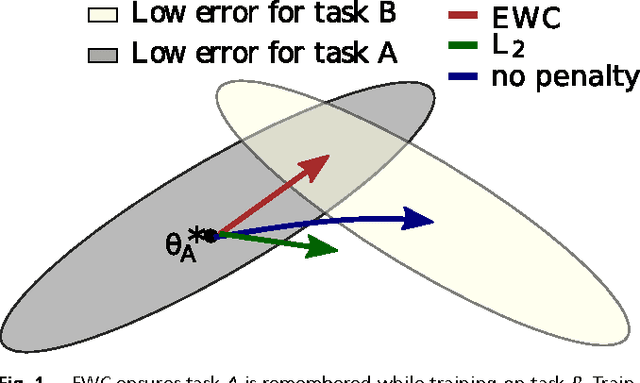
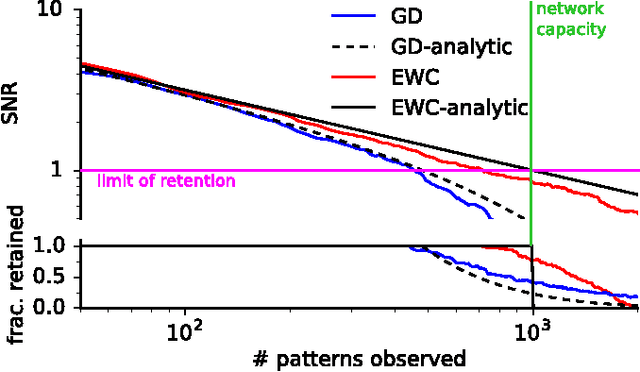
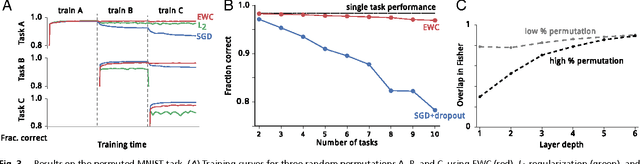
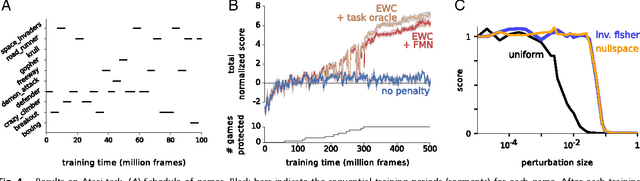
The ability to learn tasks in a sequential fashion is crucial to the development of artificial intelligence. Neural networks are not, in general, capable of this and it has been widely thought that catastrophic forgetting is an inevitable feature of connectionist models. We show that it is possible to overcome this limitation and train networks that can maintain expertise on tasks which they have not experienced for a long time. Our approach remembers old tasks by selectively slowing down learning on the weights important for those tasks. We demonstrate our approach is scalable and effective by solving a set of classification tasks based on the MNIST hand written digit dataset and by learning several Atari 2600 games sequentially.