 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Models to Teach Themselves: Reasoning at the Edge of Learnability
Jan 26, 2026Can a model learn to escape its own learning plateau? Reinforcement learning methods for finetuning large reasoning models stall on datasets with low initial success rates, and thus little training signal. We investigate a fundamental question: Can a pretrained LLM leverage latent knowledge to generate an automated curriculum for problems it cannot solve? To explore this, we design SOAR: A self-improvement framework designed to surface these pedagogical signals through meta-RL. A teacher copy of the model proposes synthetic problems for a student copy, and is rewarded with its improvement on a small subset of hard problems. Critically, SOAR grounds the curriculum in measured student progress rather than intrinsic proxy rewards. Our study on the hardest subsets of mathematical benchmarks (0/128 success) reveals three core findings. First, we show that it is possible to realize bi-level meta-RL that unlocks learning under sparse, binary rewards by sharpening a latent capacity of pretrained models to generate useful stepping stones. Second, grounded rewards outperform intrinsic reward schemes used in prior LLM self-play, reliably avoiding the instability and diversity collapse modes they typically exhibit. Third, analyzing the generated questions reveals that structural quality and well-posedness are more critical for learning progress than solution correctness. Our results suggest that the ability to generate useful stepping stones does not require the preexisting ability to actually solve the hard problems, paving a principled path to escape reasoning plateaus without additional curated data.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Vision-Language Models as a Source of Rewards
Dec 14, 2023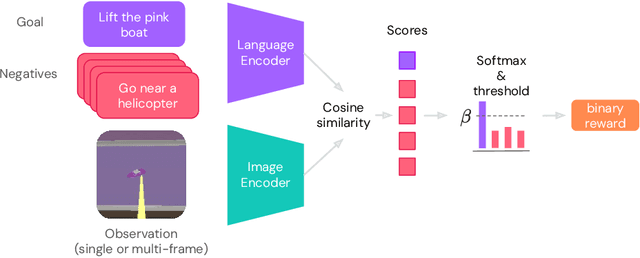
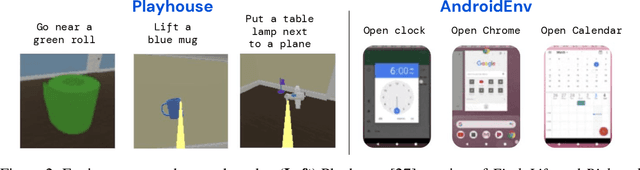
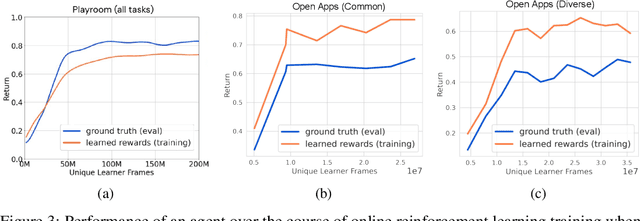
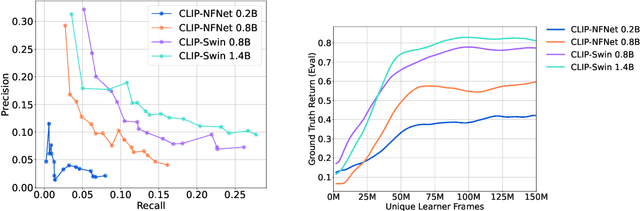
Building generalist agents that can accomplish many goals in rich open-ended environments is one of the research frontiers for reinforcement learning. A key limiting factor for building generalist agents with RL has been the need for a large number of reward functions for achieving different goals. We investigate the feasibility of using off-the-shelf vision-language models, or VLMs, as sources of rewards for reinforcement learning agents. We show how rewards for visual achievement of a variety of language goals can be derived from the CLIP family of models, and used to train RL agents that can achieve a variety of language goals. We showcase this approach in two distinct visual domains and present a scaling trend showing how larger VLMs lead to more accurate rewards for visual goal achievement, which in turn produces more capable RL agents.
The Phenomenon of Policy Churn
Jun 09, 2022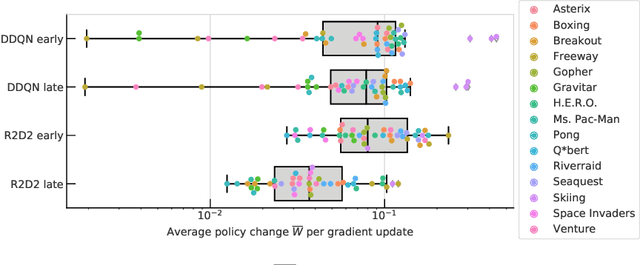

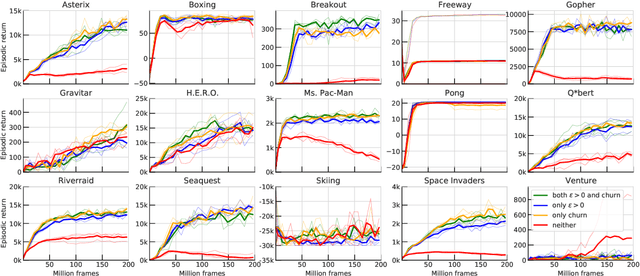
We identify and study the phenomenon of policy churn, that is, the rapid change of the greedy policy in value-based reinforcement learning. Policy churn operates at a surprisingly rapid pace, changing the greedy action in a large fraction of states within a handful of learning updates (in a typical deep RL set-up such as DQN on Atari). We characterise the phenomenon empirically, verifying that it is not limited to specific algorithm or environment properties. A number of ablations help whittle down the plausible explanations on why churn occurs to just a handful, all related to deep learning. Finally, we hypothesise that policy churn is a beneficial but overlooked form of implicit exploration that casts $\epsilon$-greedy exploration in a fresh light, namely that $\epsilon$-noise plays a much smaller role than expected.
Podracer architectures for scalable Reinforcement Learning
Apr 13, 2021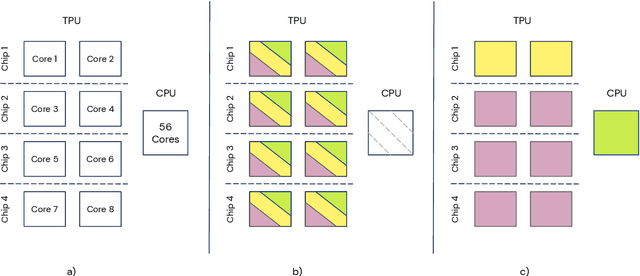
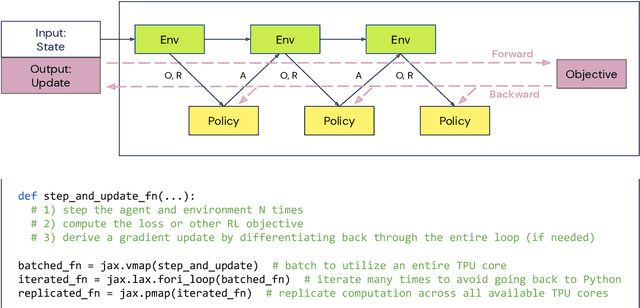
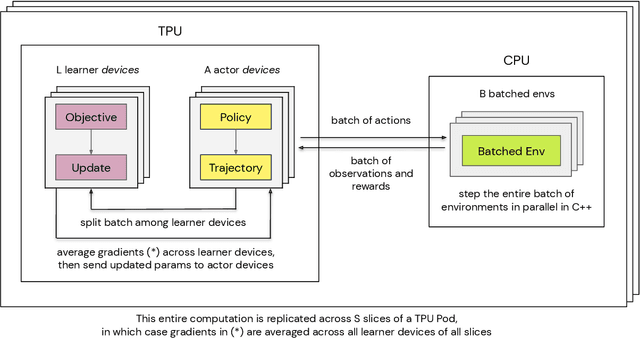
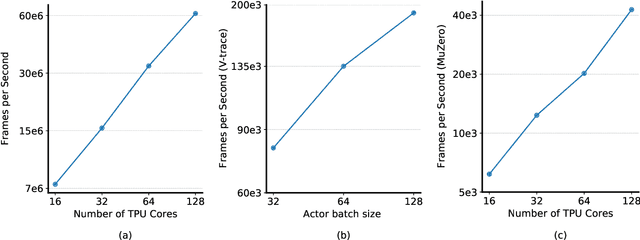
Supporting state-of-the-art AI research requires balancing rapid prototyping, ease of use, and quick iteration, with the ability to deploy experiments at a scale traditionally associated with production systems.Deep learning frameworks such as TensorFlow, PyTorch and JAX allow users to transparently make use of accelerators, such as TPUs and GPUs, to offload the more computationally intensive parts of training and inference in modern deep learning systems. Popular training pipelines that use these frameworks for deep learning typically focus on (un-)supervised learning. How to best train reinforcement learning (RL) agents at scale is still an active research area. In this report we argue that TPUs are particularly well suited for training RL agents in a scalable, efficient and reproducible way. Specifically we describe two architectures designed to make the best use of the resources available on a TPU Pod (a special configuration in a Google data center that features multiple TPU devices connected to each other by extremely low latency communication channels).
The Value-Improvement Path: Towards Better Representations for Reinforcement Learning
Jun 03, 2020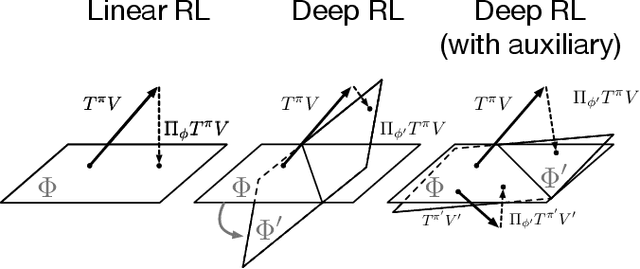

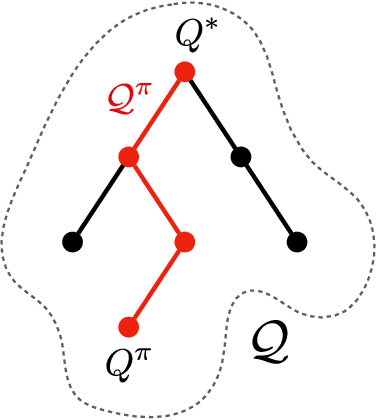

In value-based reinforcement learning (RL), unlike in supervised learning, the agent faces not a single, stationary, approximation problem, but a sequence of value prediction problems. Each time the policy improves, the nature of the problem changes, shifting both the distribution of states and their values. In this paper we take a novel perspective, arguing that the value prediction problems faced by an RL agent should not be addressed in isolation, but rather as a single, holistic, prediction problem. An RL algorithm generates a sequence of policies that, at least approximately, improve towards the optimal policy. We explicitly characterize the associated sequence of value functions and call it the value-improvement path. Our main idea is to approximate the value-improvement path holistically, rather than to solely track the value function of the current policy. Specifically, we discuss the impact that this holistic view of RL has on representation learning. We demonstrate that a representation that spans the past value-improvement path will also provide an accurate value approximation for future policy improvements. We use this insight to better understand existing approaches to auxiliary tasks and to propose new ones. To test our hypothesis empirically, we augmented a standard deep RL agent with an auxiliary task of learning the value-improvement path. In a study of Atari 2600 games, the augmented agent achieved approximately double the mean and median performance of the baseline agent.
General non-linear Bellman equations
Jul 08, 2019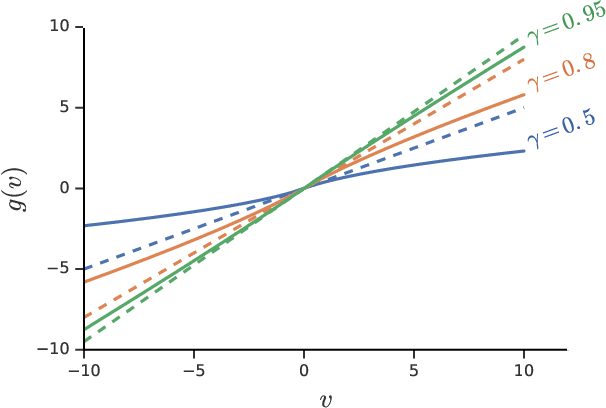
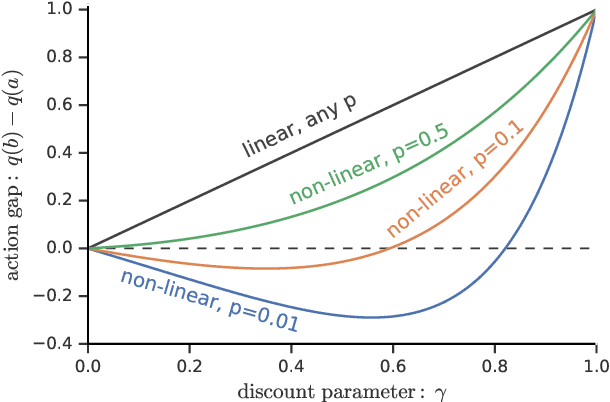
We consider a general class of non-linear Bellman equations. These open up a design space of algorithms that have interesting properties, which has two potential advantages. First, we can perhaps better model natural phenomena. For instance, hyperbolic discounting has been proposed as a mathematical model that matches human and animal data well, and can therefore be used to explain preference orderings. We present a different mathematical model that matches the same data, but that makes very different predictions under other circumstances. Second, the larger design space can perhaps lead to algorithms that perform better, similar to how discount factors are often used in practice even when the true objective is undiscounted. We show that many of the resulting Bellman operators still converge to a fixed point, and therefore that the resulting algorithms are reasonable and inherit many beneficial properties of their linear counterparts.
Transfer in Deep Reinforcement Learning Using Successor Features and Generalised Policy Improvement
Jan 30, 2019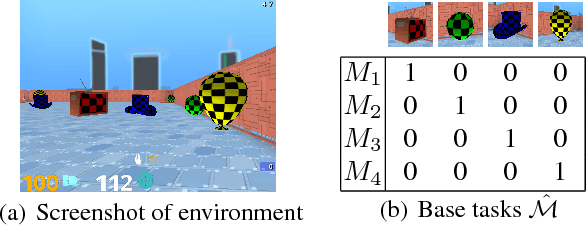
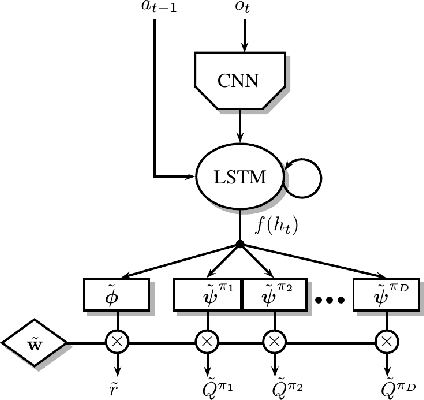
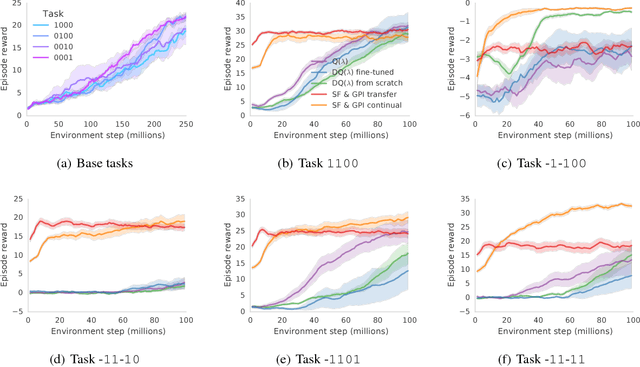
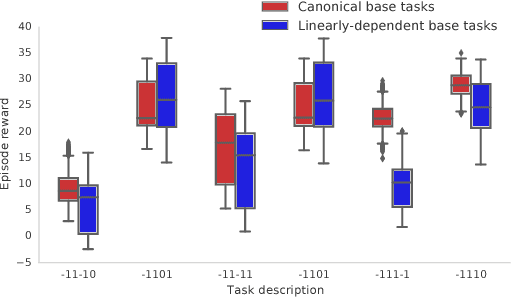
The ability to transfer skills across tasks has the potential to scale up reinforcement learning (RL) agents to environments currently out of reach. Recently, a framework based on two ideas, successor features (SFs) and generalised policy improvement (GPI), has been introduced as a principled way of transferring skills. In this paper we extend the SFs & GPI framework in two ways. One of the basic assumptions underlying the original formulation of SFs & GPI is that rewards for all tasks of interest can be computed as linear combinations of a fixed set of features. We relax this constraint and show that the theoretical guarantees supporting the framework can be extended to any set of tasks that only differ in the reward function. Our second contribution is to show that one can use the reward functions themselves as features for future tasks, without any loss of expressiveness, thus removing the need to specify a set of features beforehand. This makes it possible to combine SFs & GPI with deep learning in a more stable way. We empirically verify this claim on a complex 3D environment where observations are images from a first-person perspective. We show that the transfer promoted by SFs & GPI leads to very good policies on unseen tasks almost instantaneously. We also describe how to learn policies specialised to the new tasks in a way that allows them to be added to the agent's set of skills, and thus be reused in the future.
Universal Successor Features Approximators
Dec 18, 2018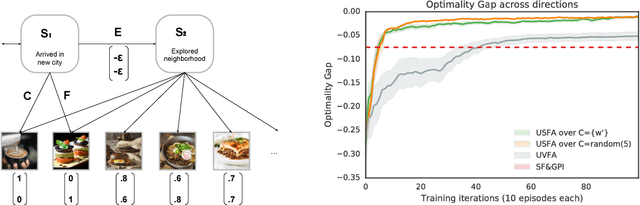

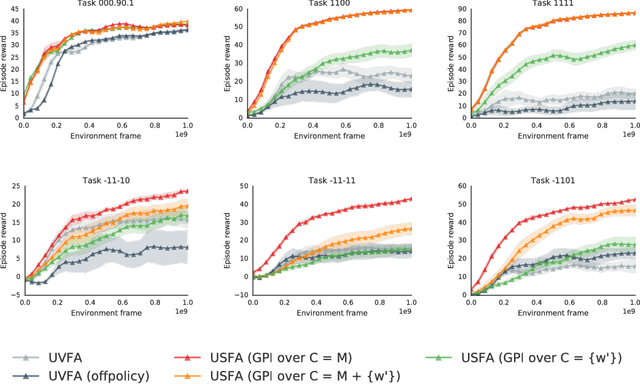

The ability of a reinforcement learning (RL) agent to learn about many reward functions at the same time has many potential benefits, such as the decomposition of complex tasks into simpler ones, the exchange of information between tasks, and the reuse of skills. We focus on one aspect in particular, namely the ability to generalise to unseen tasks. Parametric generalisation relies on the interpolation power of a function approximator that is given the task description as input; one of its most common form are universal value function approximators (UVFAs). Another way to generalise to new tasks is to exploit structure in the RL problem itself. Generalised policy improvement (GPI) combines solutions of previous tasks into a policy for the unseen task; this relies on instantaneous policy evaluation of old policies under the new reward function, which is made possible through successor features (SFs). Our proposed universal successor features approximators (USFAs) combine the advantages of all of these, namely the scalability of UVFAs, the instant inference of SFs, and the strong generalisation of GPI. We discuss the challenges involved in training a USFA, its generalisation properties and demonstrate its practical benefits and transfer abilities on a large-scale domain in which the agent has to navigate in a first-person perspective three-dimensional environment.
Unicorn: Continual Learning with a Universal, Off-policy Agent
Jul 03, 2018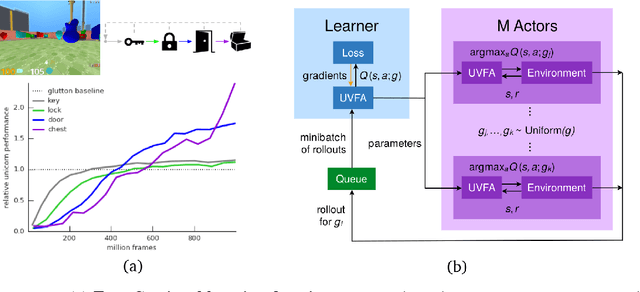
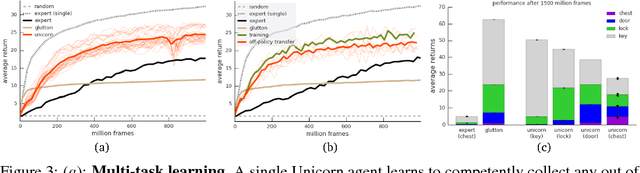
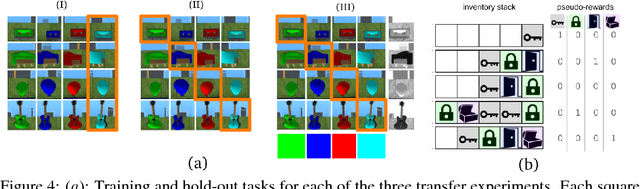
Some real-world domains are best characterized as a single task, but for others this perspective is limiting. Instead, some tasks continually grow in complexity, in tandem with the agent's competence. In continual learning, also referred to as lifelong learning, there are no explicit task boundaries or curricula. As learning agents have become more powerful, continual learning remains one of the frontiers that has resisted quick progress. To test continual learning capabilities we consider a challenging 3D domain with an implicit sequence of tasks and sparse rewards. We propose a novel agent architecture called Unicorn, which demonstrates strong continual learning and outperforms several baseline agents on the proposed domain. The agent achieves this by jointly representing and learning multiple policies efficiently, using a parallel off-policy learning setup.