 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Phenomenon of Policy Churn
Paper and Code
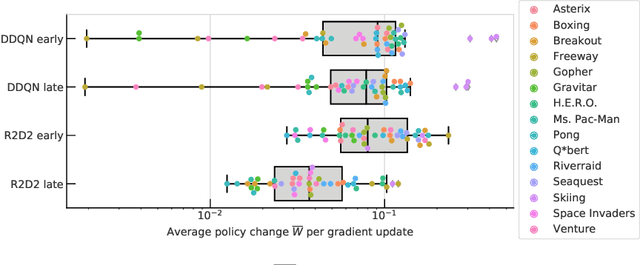

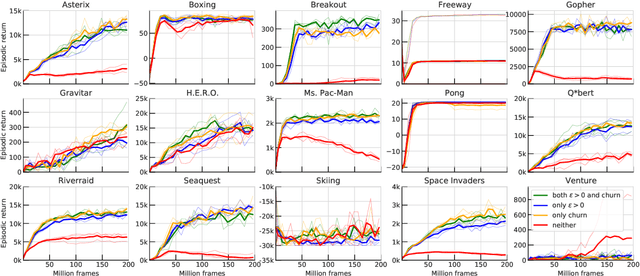
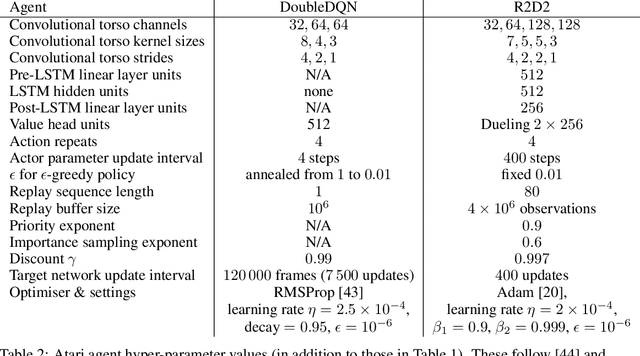
We identify and study the phenomenon of policy churn, that is, the rapid change of the greedy policy in value-based reinforcement learning. Policy churn operates at a surprisingly rapid pace, changing the greedy action in a large fraction of states within a handful of learning updates (in a typical deep RL set-up such as DQN on Atari). We characterise the phenomenon empirically, verifying that it is not limited to specific algorithm or environment properties. A number of ablations help whittle down the plausible explanations on why churn occurs to just a handful, all related to deep learning. Finally, we hypothesise that policy churn is a beneficial but overlooked form of implicit exploration that casts $\epsilon$-greedy exploration in a fresh light, namely that $\epsilon$-noise plays a much smaller role than expected.