 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaunchpad: A Programming Model for Distributed Machine Learning Research
Jun 07, 2021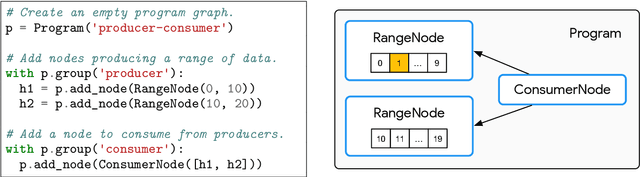
A major driver behind the success of modern machine learning algorithms has been their ability to process ever-larger amounts of data. As a result, the use of distributed systems in both research and production has become increasingly prevalent as a means to scale to this growing data. At the same time, however, distributing the learning process can drastically complicate the implementation of even simple algorithms. This is especially problematic as many machine learning practitioners are not well-versed in the design of distributed systems, let alone those that have complicated communication topologies. In this work we introduce Launchpad, a programming model that simplifies the process of defining and launching distributed systems that is specifically tailored towards a machine learning audience. We describe our framework, its design philosophy and implementation, and give a number of examples of common learning algorithms whose designs are greatly simplified by this approach.
Podracer architectures for scalable Reinforcement Learning
Apr 13, 2021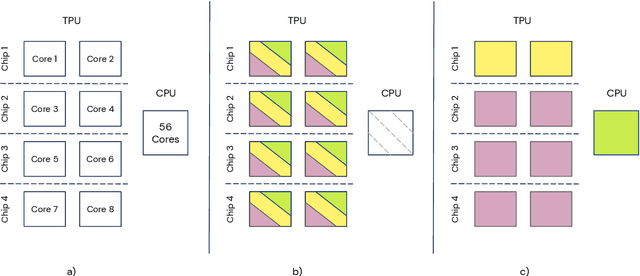
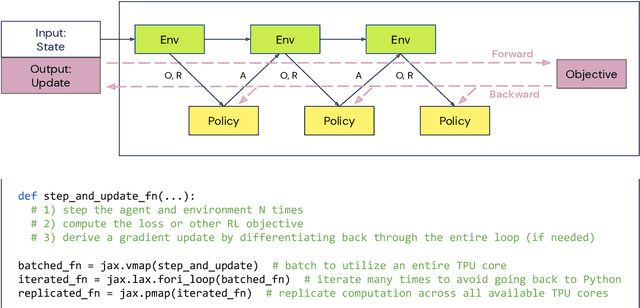
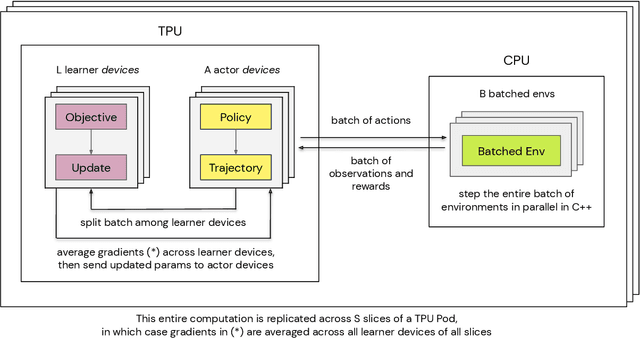
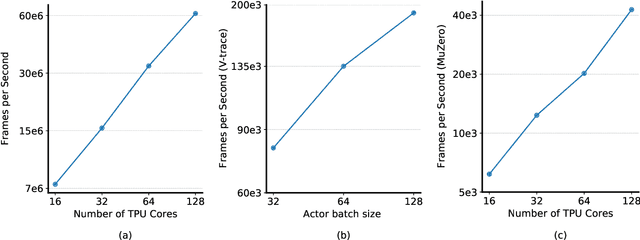
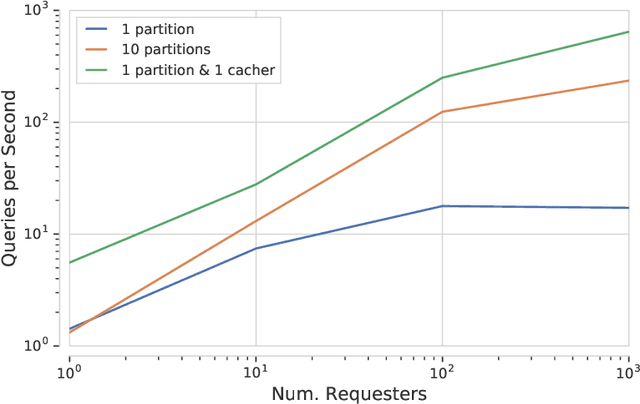
Supporting state-of-the-art AI research requires balancing rapid prototyping, ease of use, and quick iteration, with the ability to deploy experiments at a scale traditionally associated with production systems.Deep learning frameworks such as TensorFlow, PyTorch and JAX allow users to transparently make use of accelerators, such as TPUs and GPUs, to offload the more computationally intensive parts of training and inference in modern deep learning systems. Popular training pipelines that use these frameworks for deep learning typically focus on (un-)supervised learning. How to best train reinforcement learning (RL) agents at scale is still an active research area. In this report we argue that TPUs are particularly well suited for training RL agents in a scalable, efficient and reproducible way. Specifically we describe two architectures designed to make the best use of the resources available on a TPU Pod (a special configuration in a Google data center that features multiple TPU devices connected to each other by extremely low latency communication channels).
Reverb: A Framework For Experience Replay
Feb 09, 2021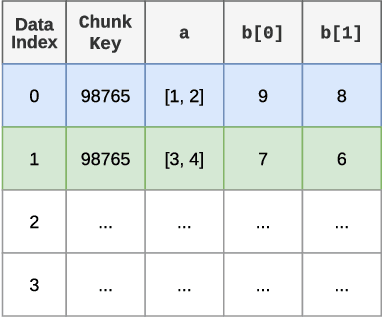
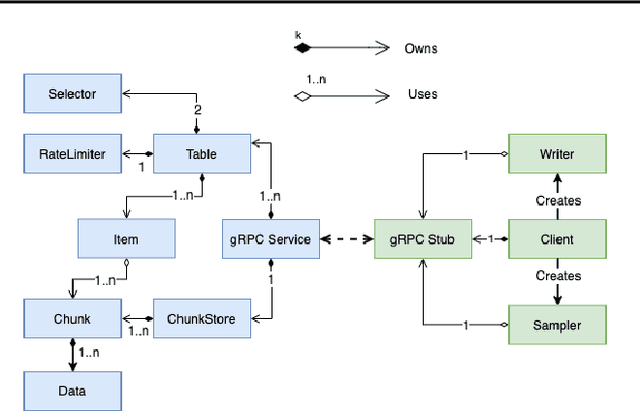
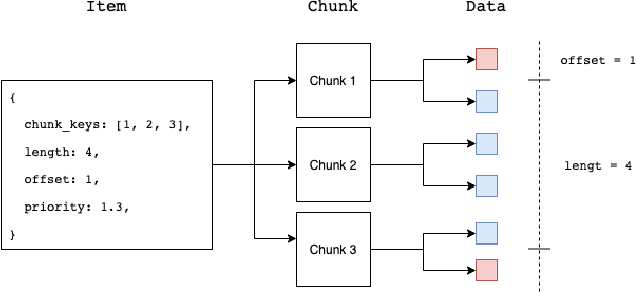
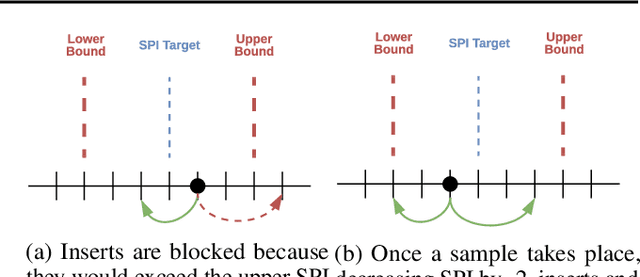
A central component of training in Reinforcement Learning (RL) is Experience: the data used for training. The mechanisms used to generate and consume this data have an important effect on the performance of RL algorithms. In this paper, we introduce Reverb: an efficient, extensible, and easy to use system designed specifically for experience replay in RL. Reverb is designed to work efficiently in distributed configurations with up to thousands of concurrent clients. The flexible API provides users with the tools to easily and accurately configure the replay buffer. It includes strategies for selecting and removing elements from the buffer, as well as options for controlling the ratio between sampled and inserted elements. This paper presents the core design of Reverb, gives examples of how it can be applied, and provides empirical results of Reverb's performance characteristics.
What Can Learned Intrinsic Rewards Capture?
Dec 11, 2019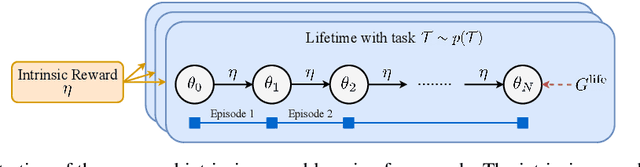
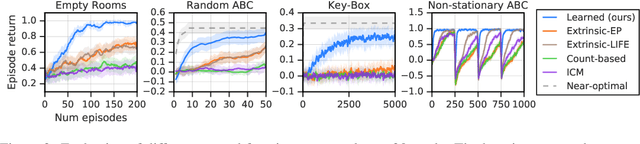
Reinforcement learning agents can include different components, such as policies, value functions, state representations, and environment models. Any or all of these can be the loci of knowledge, i.e., structures where knowledge, whether given or learned, can be deposited and reused. The objective of an agent is to behave so as to maximise the sum of a suitable scalar function of state: the reward. As far as the learning algorithm is concerned, these rewards are typically given and immutable. In this paper we instead consider the proposition that the reward function itself may be a good locus of knowledge. This is consistent with a common use, in the literature, of hand-designed intrinsic rewards to improve the learning dynamics of an agent. We adopt the multi-lifetime setting of the Optimal Rewards Framework, and propose to meta-learn an intrinsic reward function from experience that allows agents to maximise their extrinsic rewards accumulated until the end of their lifetimes. Rewards as a locus of knowledge provide guidance on "what" the agent should strive to do rather than "how" the agent should behave; the latter is more directly captured in policies or value functions for example. Thus, our focus here is on demonstrating the following: (1) that it is feasible to meta-learn good reward functions, (2) that the learned reward functions can capture interesting kinds of "what" knowledge, and (3) that because of the indirectness of this form of knowledge the learned reward functions can generalise to other kinds of agents and to changes in the dynamics of the environment.