 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverb: A Framework For Experience Replay
Paper and Code
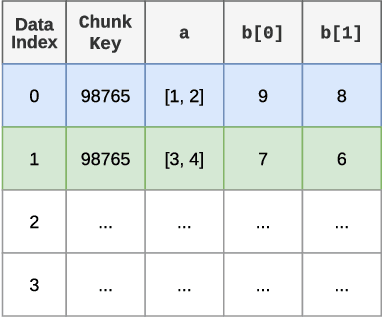
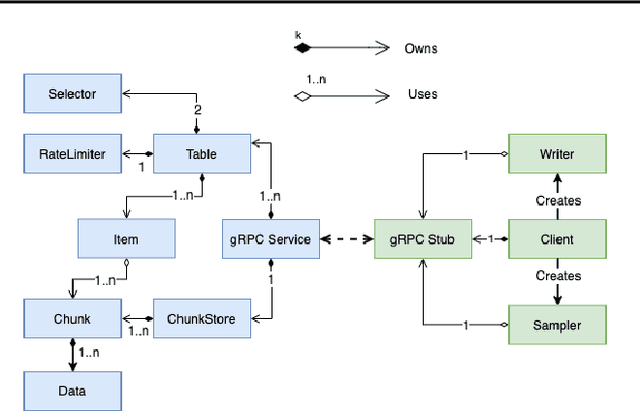
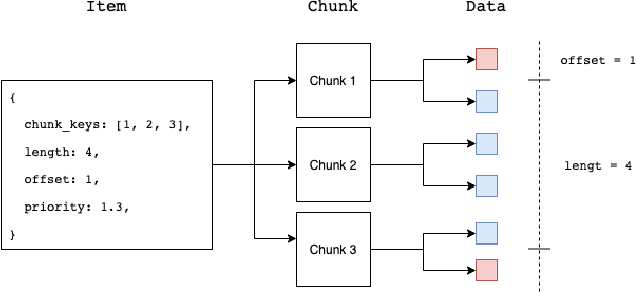
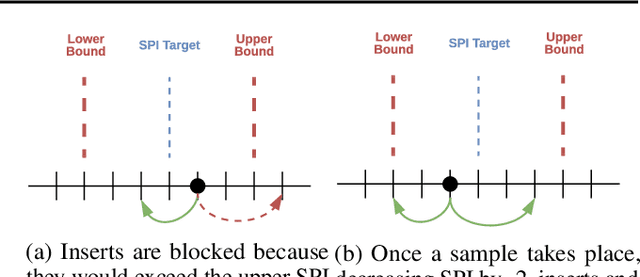
A central component of training in Reinforcement Learning (RL) is Experience: the data used for training. The mechanisms used to generate and consume this data have an important effect on the performance of RL algorithms. In this paper, we introduce Reverb: an efficient, extensible, and easy to use system designed specifically for experience replay in RL. Reverb is designed to work efficiently in distributed configurations with up to thousands of concurrent clients. The flexible API provides users with the tools to easily and accurately configure the replay buffer. It includes strategies for selecting and removing elements from the buffer, as well as options for controlling the ratio between sampled and inserted elements. This paper presents the core design of Reverb, gives examples of how it can be applied, and provides empirical results of Reverb's performance characteristics.