 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
DiscoGen: Learning to Discover Gene Regulatory Networks
Apr 12, 2023Accurately inferring Gene Regulatory Networks (GRNs) is a critical and challenging task in biology. GRNs model the activatory and inhibitory interactions between genes and are inherently causal in nature. To accurately identify GRNs, perturbational data is required. However, most GRN discovery methods only operate on observational data. Recent advances in neural network-based causal discovery methods have significantly improved causal discovery, including handling interventional data, improvements in performance and scalability. However, applying state-of-the-art (SOTA) causal discovery methods in biology poses challenges, such as noisy data and a large number of samples. Thus, adapting the causal discovery methods is necessary to handle these challenges. In this paper, we introduce DiscoGen, a neural network-based GRN discovery method that can denoise gene expression measurements and handle interventional data. We demonstrate that our model outperforms SOTA neural network-based causal discovery methods.
Unified Scaling Laws for Routed Language Models
Feb 09, 2022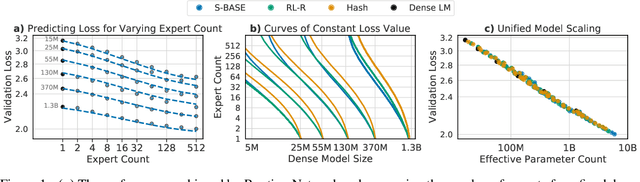

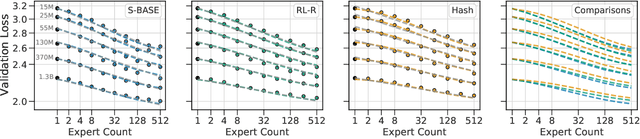
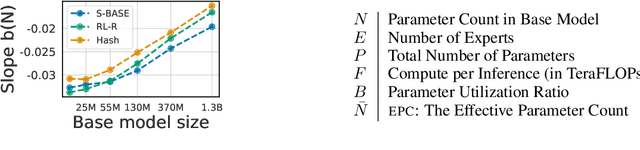
The performance of a language model has been shown to be effectively modeled as a power-law in its parameter count. Here we study the scaling behaviors of Routing Networks: architectures that conditionally use only a subset of their parameters while processing an input. For these models, parameter count and computational requirement form two independent axes along which an increase leads to better performance. In this work we derive and justify scaling laws defined on these two variables which generalize those known for standard language models and describe the performance of a wide range of routing architectures trained via three different techniques. Afterwards we provide two applications of these laws: first deriving an Effective Parameter Count along which all models scale at the same rate, and then using the scaling coefficients to give a quantitative comparison of the three routing techniques considered. Our analysis derives from an extensive evaluation of Routing Networks across five orders of magnitude of size, including models with hundreds of experts and hundreds of billions of parameters.
Improving language models by retrieving from trillions of tokens
Jan 11, 2022



We enhance auto-regressive language models by conditioning on document chunks retrieved from a large corpus, based on local similarity with preceding tokens. With a $2$ trillion token database, our Retrieval-Enhanced Transformer (RETRO) obtains comparable performance to GPT-3 and Jurassic-1 on the Pile, despite using 25$\times$ fewer parameters. After fine-tuning, RETRO performance translates to downstream knowledge-intensive tasks such as question answering. RETRO combines a frozen Bert retriever, a differentiable encoder and a chunked cross-attention mechanism to predict tokens based on an order of magnitude more data than what is typically consumed during training. We typically train RETRO from scratch, yet can also rapidly RETROfit pre-trained transformers with retrieval and still achieve good performance. Our work opens up new avenues for improving language models through explicit memory at unprecedented scale.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Dec 08, 2021



Language modelling provides a step towards intelligent communication systems by harnessing large repositories of written human knowledge to better predict and understand the world. In this paper, we present an analysis of Transformer-based language model performance across a wide range of model scales -- from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit. We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity. Finally we discuss the application of language models to AI safety and the mitigation of downstream harms.
Reverb: A Framework For Experience Replay
Feb 09, 2021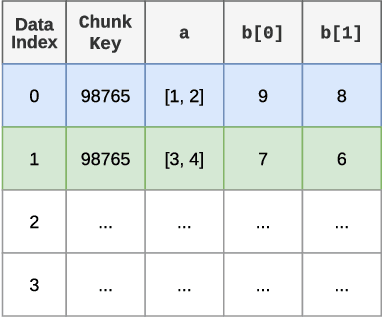
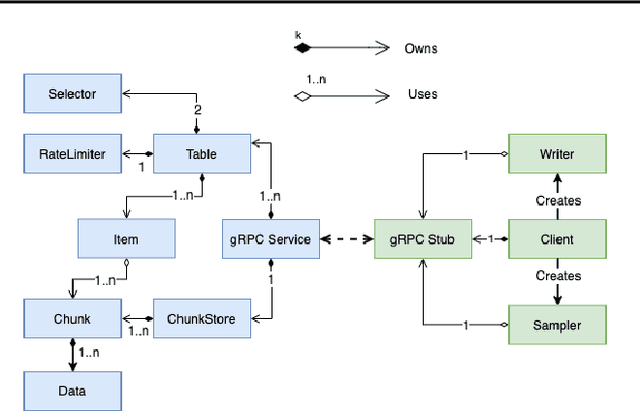
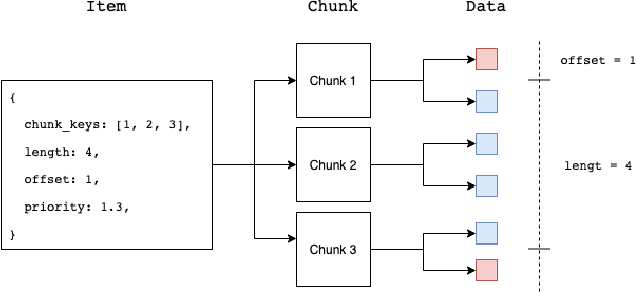
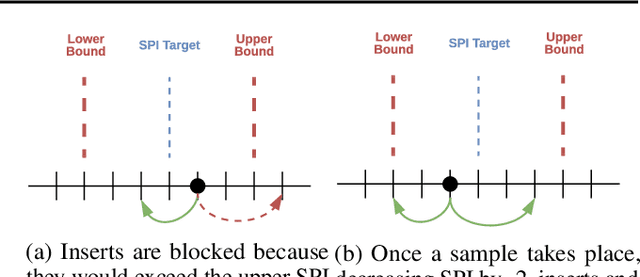
A central component of training in Reinforcement Learning (RL) is Experience: the data used for training. The mechanisms used to generate and consume this data have an important effect on the performance of RL algorithms. In this paper, we introduce Reverb: an efficient, extensible, and easy to use system designed specifically for experience replay in RL. Reverb is designed to work efficiently in distributed configurations with up to thousands of concurrent clients. The flexible API provides users with the tools to easily and accurately configure the replay buffer. It includes strategies for selecting and removing elements from the buffer, as well as options for controlling the ratio between sampled and inserted elements. This paper presents the core design of Reverb, gives examples of how it can be applied, and provides empirical results of Reverb's performance characteristics.
Acme: A Research Framework for Distributed Reinforcement Learning
Jun 01, 2020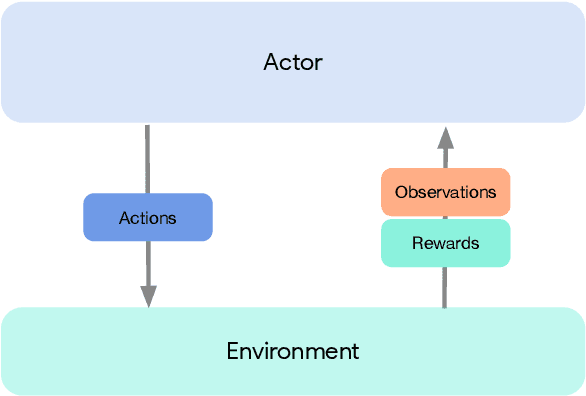
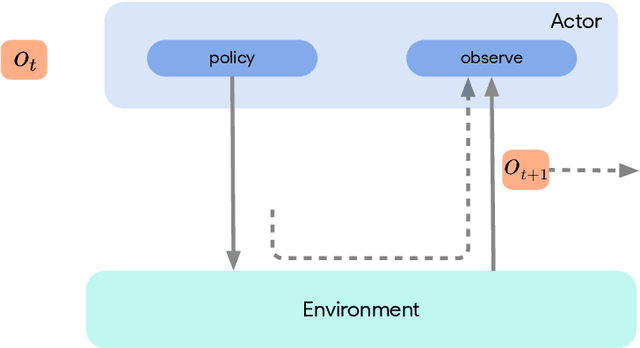
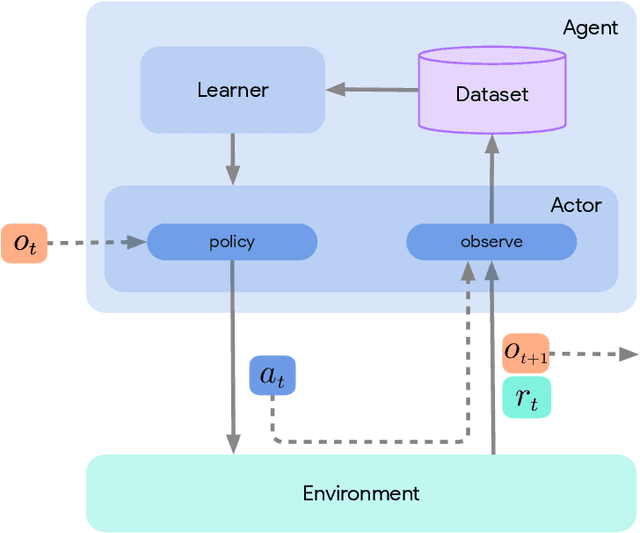
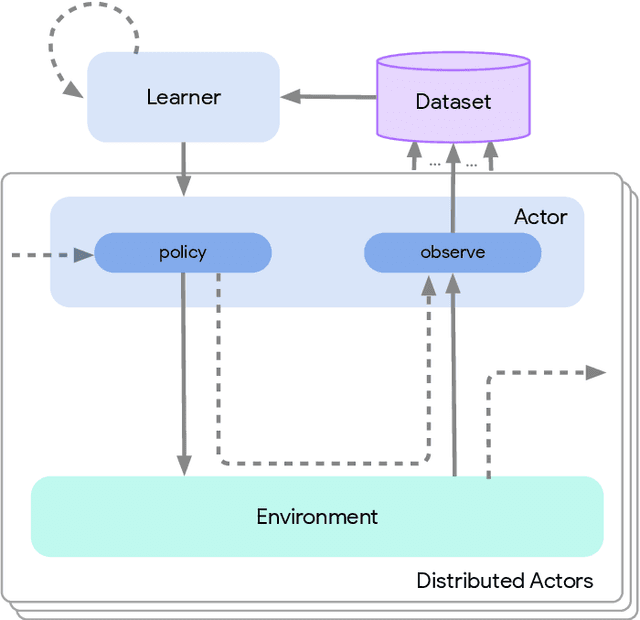
Deep reinforcement learning has led to many recent-and groundbreaking-advancements. However, these advances have often come at the cost of both the scale and complexity of the underlying RL algorithms. Increases in complexity have in turn made it more difficult for researchers to reproduce published RL algorithms or rapidly prototype ideas. To address this, we introduce Acme, a tool to simplify the development of novel RL algorithms that is specifically designed to enable simple agent implementations that can be run at various scales of execution. Our aim is also to make the results of various RL algorithms developed in academia and industrial labs easier to reproduce and extend. To this end we are releasing baseline implementations of various algorithms, created using our framework. In this work we introduce the major design decisions behind Acme and show how these are used to construct these baselines. We also experiment with these agents at different scales of both complexity and computation-including distributed versions. Ultimately, we show that the design decisions behind Acme lead to agents that can be scaled both up and down and that, for the most part, greater levels of parallelization result in agents with equivalent performance, just faster.
Transformation-based Adversarial Video Prediction on Large-Scale Data
Mar 09, 2020
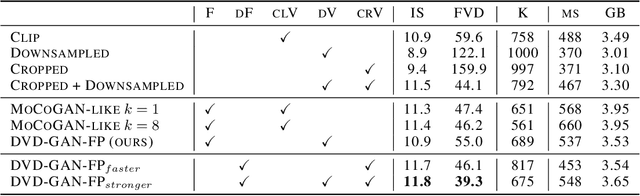
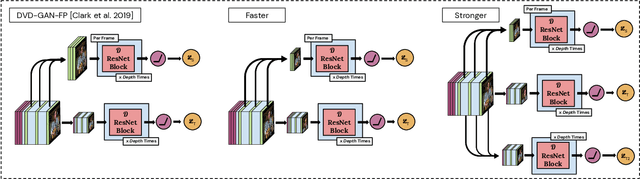
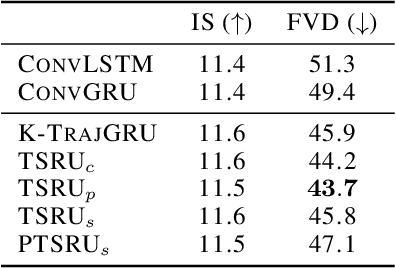
Recent breakthroughs in adversarial generative modeling have led to models capable of producing video samples of high quality, even on large and complex datasets of real-world video. In this work, we focus on the task of video prediction, where given a sequence of frames extracted from a video, the goal is to generate a plausible future sequence. We first improve the state of the art by performing a systematic empirical study of discriminator decompositions and proposing an architecture that yields faster convergence and higher performance than previous approaches. We then analyze recurrent units in the generator, and propose a novel recurrent unit which transforms its past hidden state according to predicted motion-like features, and refines it to to handle dis-occlusions, scene changes and other complex behavior. We show that this recurrent unit consistently outperforms previous designs. Our final model leads to a leap in the state-of-the-art performance, obtaining a test set Frechet Video Distance of 25.7, down from 69.2, on the large-scale Kinetics-600 dataset.
Randomized Prior Functions for Deep Reinforcement Learning
Jun 08, 2018



Dealing with uncertainty is essential for efficient reinforcement learning. There is a growing literature on uncertainty estimation for deep learning from fixed datasets, but many of the most popular approaches are poorly-suited to sequential decision problems. Other methods, such as bootstrap sampling, have no mechanism for uncertainty that does not come from the observed data. We highlight why this can be a crucial shortcoming and propose a simple remedy through addition of a randomized untrainable `prior' network to each ensemble member. We prove that this approach is efficient with linear representations, provide simple illustrations of its efficacy with nonlinear representations and show that this approach scales to large-scale problems far better than previous attempts.