 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving cosmological reach of a gravitational wave observatory using Deep Loop Shaping
Sep 17, 2025Improved low-frequency sensitivity of gravitational wave observatories would unlock study of intermediate-mass black hole mergers, binary black hole eccentricity, and provide early warnings for multi-messenger observations of binary neutron star mergers. Today's mirror stabilization control injects harmful noise, constituting a major obstacle to sensitivity improvements. We eliminated this noise through Deep Loop Shaping, a reinforcement learning method using frequency domain rewards. We proved our methodology on the LIGO Livingston Observatory (LLO). Our controller reduced control noise in the 10--30Hz band by over 30x, and up to 100x in sub-bands surpassing the design goal motivated by the quantum limit. These results highlight the potential of Deep Loop Shaping to improve current and future GW observatories, and more broadly instrumentation and control systems.
PartIR: Composing SPMD Partitioning Strategies for Machine Learning
Jan 23, 2024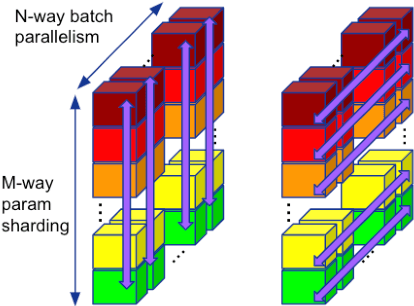
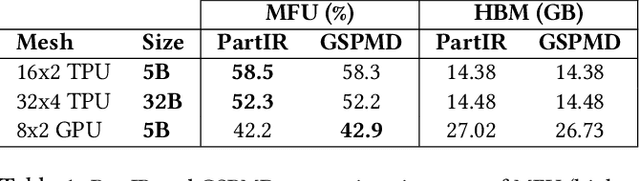
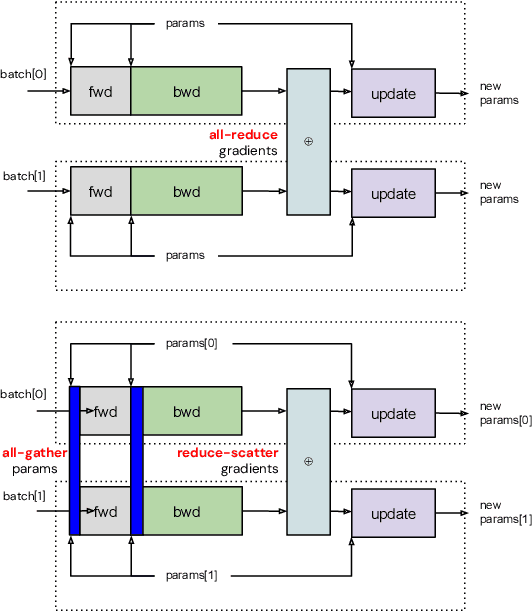
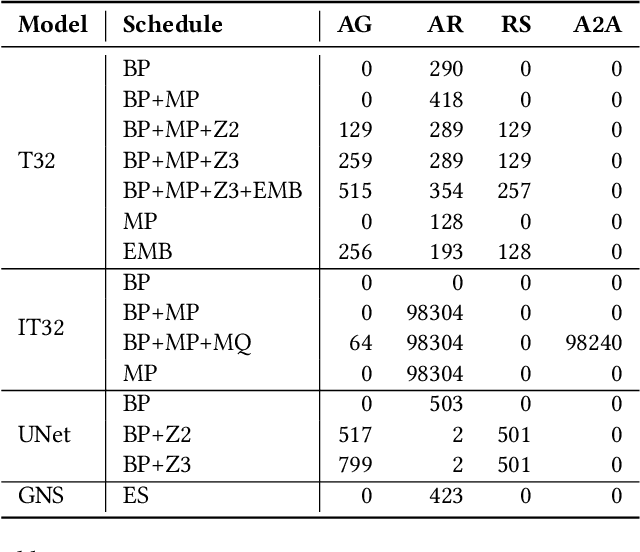
Training of modern large neural networks (NN) requires a combination of parallelization strategies encompassing data, model, or optimizer sharding. When strategies increase in complexity, it becomes necessary for partitioning tools to be 1) expressive, allowing the composition of simpler strategies, and 2) predictable to estimate performance analytically. We present PartIR, our design for a NN partitioning system. PartIR is focused on an incremental approach to rewriting and is hardware-and-runtime agnostic. We present a simple but powerful API for composing sharding strategies and a simulator to validate them. The process is driven by high-level programmer-issued partitioning tactics, which can be both manual and automatic. Importantly, the tactics are specified separately from the model code, making them easy to change. We evaluate PartIR on several different models to demonstrate its predictability, expressibility, and ability to reach peak performance..
Automatic Discovery of Composite SPMD Partitioning Strategies in PartIR
Oct 07, 2022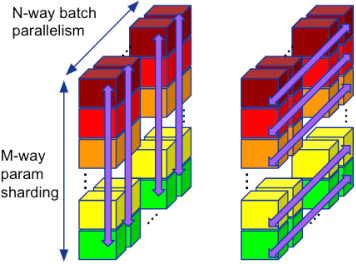


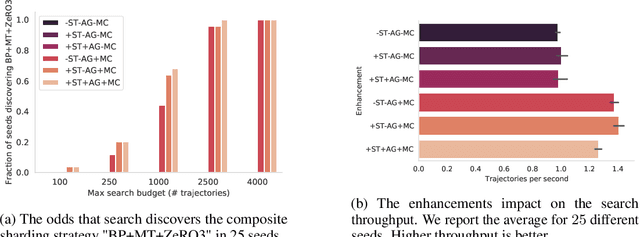
Large neural network models are commonly trained through a combination of advanced parallelism strategies in a single program, multiple data (SPMD) paradigm. For example, training large transformer models requires combining data, model, and pipeline partitioning; and optimizer sharding techniques. However, identifying efficient combinations for many model architectures and accelerator systems requires significant manual analysis. In this work, we present an automatic partitioner that identifies these combinations through a goal-oriented search. Our key findings are that a Monte Carlo Tree Search-based partitioner leveraging partition-specific compiler analysis directly into the search and guided goals matches expert-level strategies for various models.
Automap: Towards Ergonomic Automated Parallelism for ML Models
Dec 06, 2021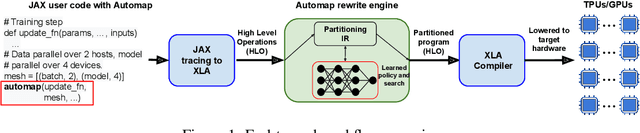
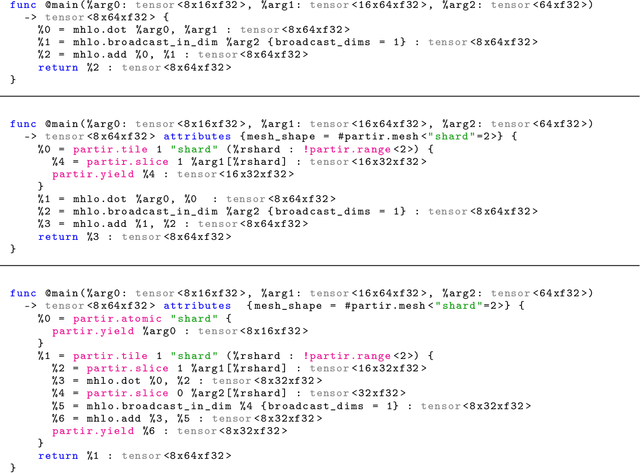


The rapid rise in demand for training large neural network architectures has brought into focus the need for partitioning strategies, for example by using data, model, or pipeline parallelism. Implementing these methods is increasingly supported through program primitives, but identifying efficient partitioning strategies requires expensive experimentation and expertise. We present the prototype of an automated partitioner that seamlessly integrates into existing compilers and existing user workflows. Our partitioner enables SPMD-style parallelism that encompasses data parallelism and parameter/activation sharding. Through a combination of inductive tactics and search in a platform-independent partitioning IR, automap can recover expert partitioning strategies such as Megatron sharding for transformer layers.
Synthesizing Optimal Parallelism Placement and Reduction Strategies on Hierarchical Systems for Deep Learning
Oct 20, 2021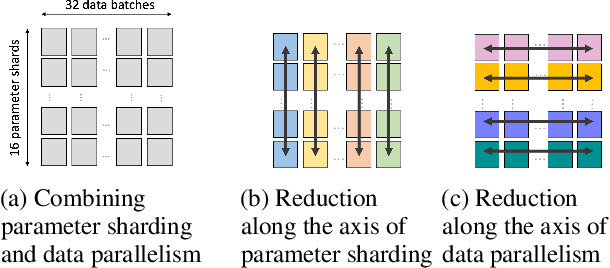
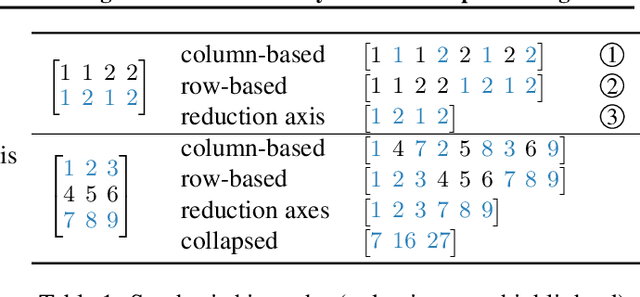
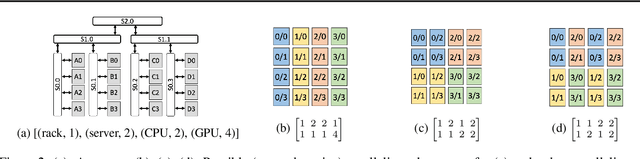
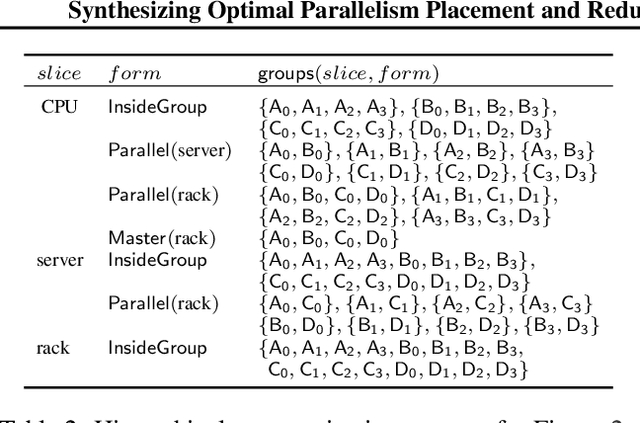
We present a novel characterization of the mapping of multiple parallelism forms (e.g. data and model parallelism) onto hierarchical accelerator systems that is hierarchy-aware and greatly reduces the space of software-to-hardware mapping. We experimentally verify the substantial effect of these mappings on all-reduce performance (up to 448x). We offer a novel syntax-guided program synthesis framework that is able to decompose reductions over one or more parallelism axes to sequences of collectives in a hierarchy- and mapping-aware way. For 69% of parallelism placements and user requested reductions, our framework synthesizes programs that outperform the default all-reduce implementation when evaluated on different GPU hierarchies (max 2.04x, average 1.27x). We complement our synthesis tool with a simulator exceeding 90% top-10 accuracy, which therefore reduces the need for massive evaluations of synthesis results to determine a small set of optimal programs and mappings.
Acme: A Research Framework for Distributed Reinforcement Learning
Jun 01, 2020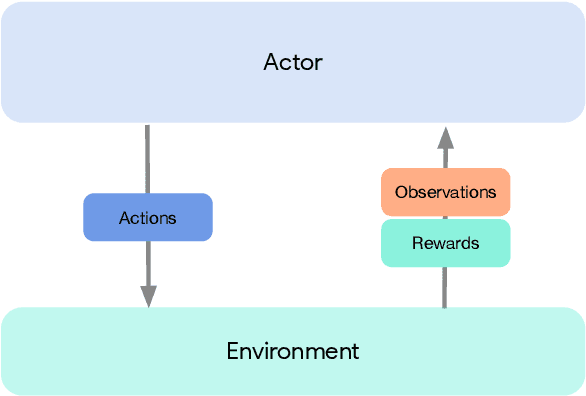
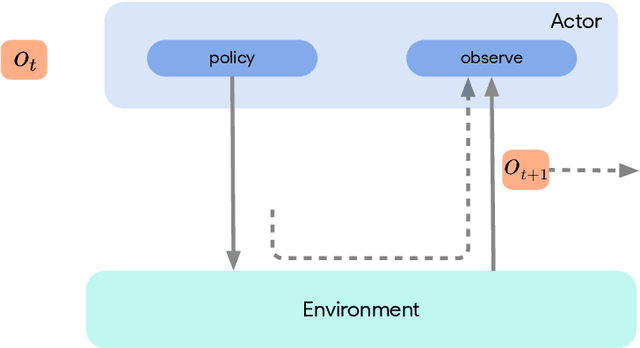
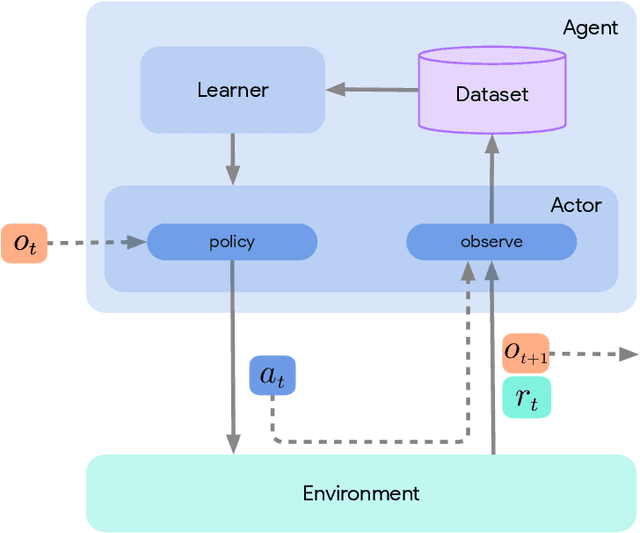
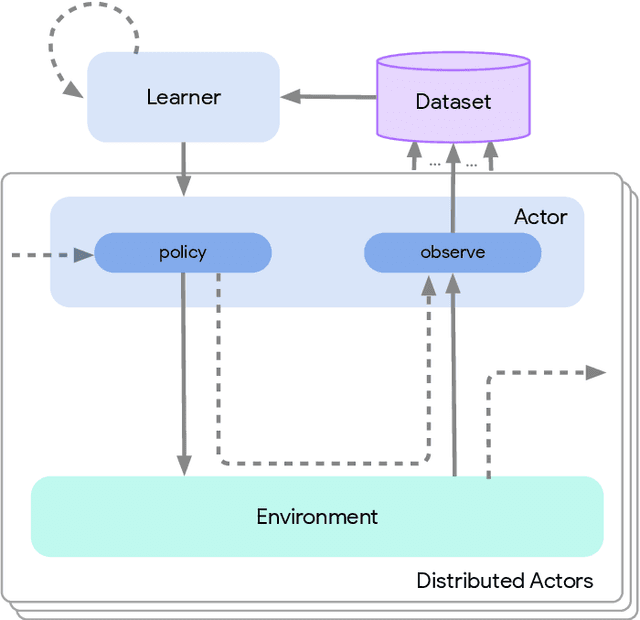
Deep reinforcement learning has led to many recent-and groundbreaking-advancements. However, these advances have often come at the cost of both the scale and complexity of the underlying RL algorithms. Increases in complexity have in turn made it more difficult for researchers to reproduce published RL algorithms or rapidly prototype ideas. To address this, we introduce Acme, a tool to simplify the development of novel RL algorithms that is specifically designed to enable simple agent implementations that can be run at various scales of execution. Our aim is also to make the results of various RL algorithms developed in academia and industrial labs easier to reproduce and extend. To this end we are releasing baseline implementations of various algorithms, created using our framework. In this work we introduce the major design decisions behind Acme and show how these are used to construct these baselines. We also experiment with these agents at different scales of both complexity and computation-including distributed versions. Ultimately, we show that the design decisions behind Acme lead to agents that can be scaled both up and down and that, for the most part, greater levels of parallelization result in agents with equivalent performance, just faster.