 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Optimal Parallelism Placement and Reduction Strategies on Hierarchical Systems for Deep Learning
Paper and Code
Oct 20, 2021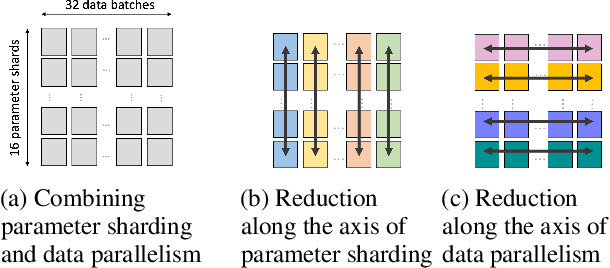
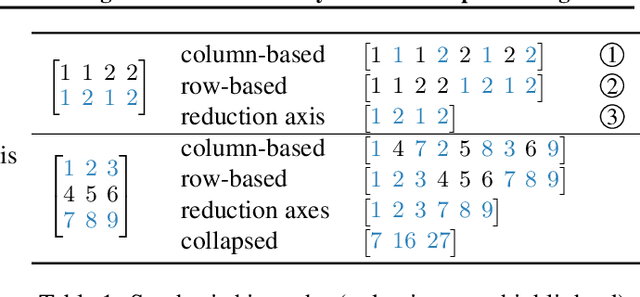
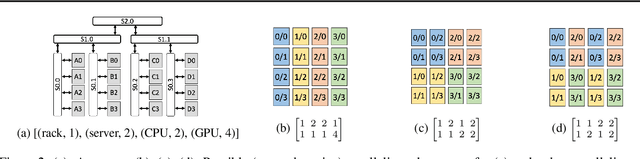
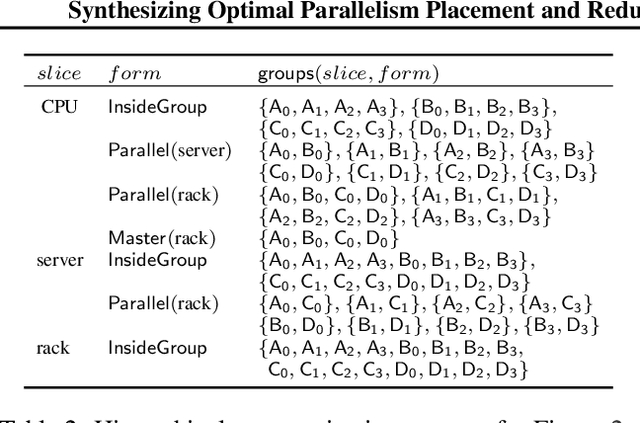
We present a novel characterization of the mapping of multiple parallelism forms (e.g. data and model parallelism) onto hierarchical accelerator systems that is hierarchy-aware and greatly reduces the space of software-to-hardware mapping. We experimentally verify the substantial effect of these mappings on all-reduce performance (up to 448x). We offer a novel syntax-guided program synthesis framework that is able to decompose reductions over one or more parallelism axes to sequences of collectives in a hierarchy- and mapping-aware way. For 69% of parallelism placements and user requested reductions, our framework synthesizes programs that outperform the default all-reduce implementation when evaluated on different GPU hierarchies (max 2.04x, average 1.27x). We complement our synthesis tool with a simulator exceeding 90% top-10 accuracy, which therefore reduces the need for massive evaluations of synthesis results to determine a small set of optimal programs and mappings.