 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartIR: Composing SPMD Partitioning Strategies for Machine Learning
Jan 23, 2024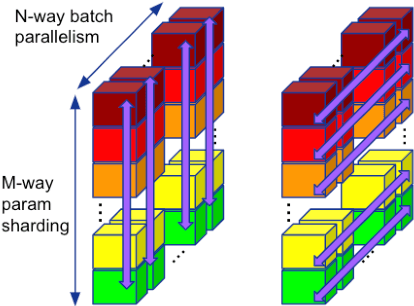
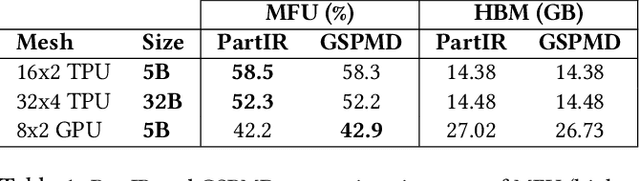
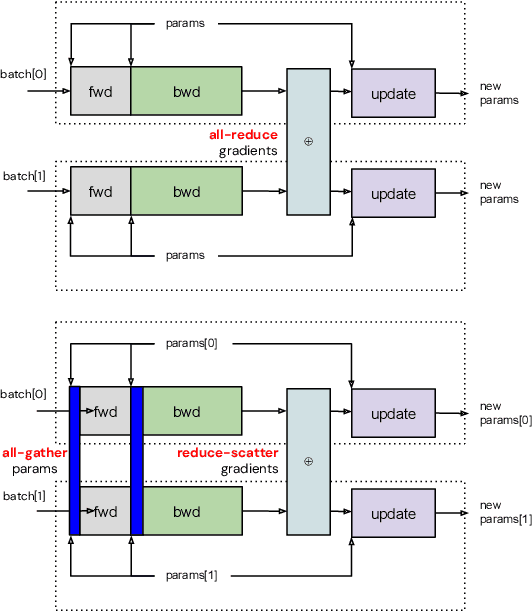
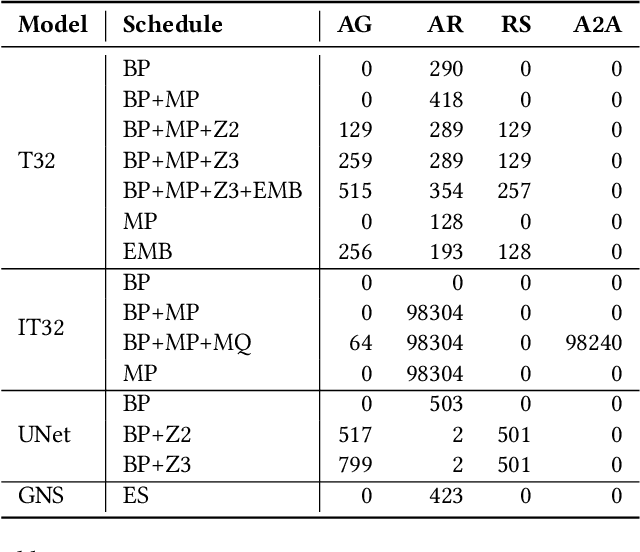
Training of modern large neural networks (NN) requires a combination of parallelization strategies encompassing data, model, or optimizer sharding. When strategies increase in complexity, it becomes necessary for partitioning tools to be 1) expressive, allowing the composition of simpler strategies, and 2) predictable to estimate performance analytically. We present PartIR, our design for a NN partitioning system. PartIR is focused on an incremental approach to rewriting and is hardware-and-runtime agnostic. We present a simple but powerful API for composing sharding strategies and a simulator to validate them. The process is driven by high-level programmer-issued partitioning tactics, which can be both manual and automatic. Importantly, the tactics are specified separately from the model code, making them easy to change. We evaluate PartIR on several different models to demonstrate its predictability, expressibility, and ability to reach peak performance..
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Automatic Discovery of Composite SPMD Partitioning Strategies in PartIR
Oct 07, 2022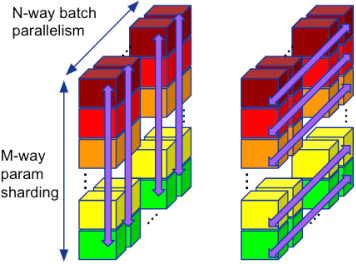


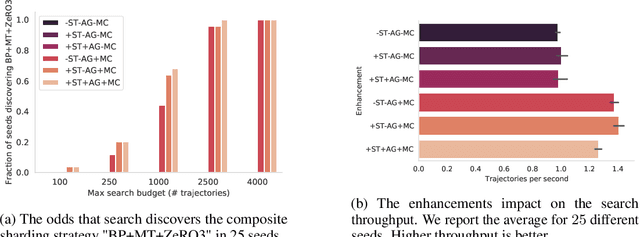
Large neural network models are commonly trained through a combination of advanced parallelism strategies in a single program, multiple data (SPMD) paradigm. For example, training large transformer models requires combining data, model, and pipeline partitioning; and optimizer sharding techniques. However, identifying efficient combinations for many model architectures and accelerator systems requires significant manual analysis. In this work, we present an automatic partitioner that identifies these combinations through a goal-oriented search. Our key findings are that a Monte Carlo Tree Search-based partitioner leveraging partition-specific compiler analysis directly into the search and guided goals matches expert-level strategies for various models.
Fast and Memory-Efficient Neural Code Completion
Apr 29, 2020


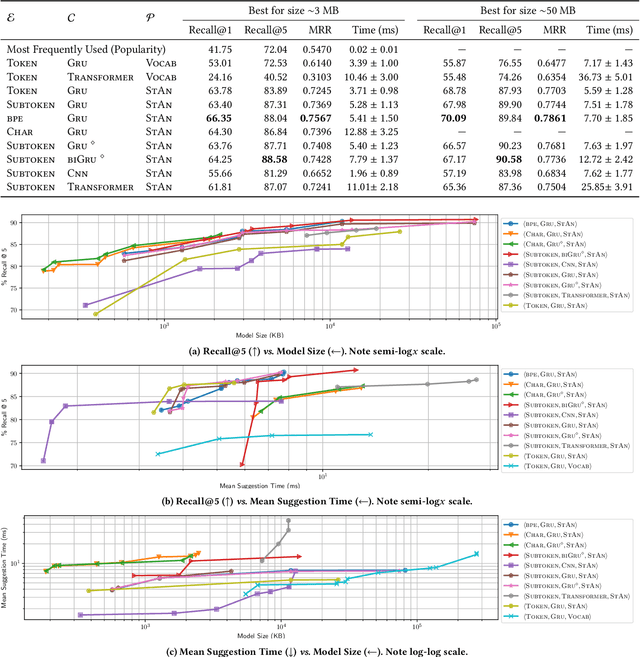
Code completion is one of the most widely used features of modern integrated development environments (IDEs). Deep learning has recently made significant progress in the statistical prediction of source code. However, state-of-the-art neural network models consume prohibitively large amounts of memory, causing computational burden to the development environment, especially when deployed in lightweight client devices. In this work, we reframe neural code completion from a generation task to a task of learning to rank the valid completion suggestions computed from static analyses. By doing so, we are able to design and test a variety of deep neural network model configurations. One of our best models consumes 6 MB of RAM, computes a single suggestion in 8 ms, and achieves 90% recall in its top five suggestions. Our models outperform standard language modeling code completion techniques in terms of predictive performance, computational speed, and memory efficiency. Furthermore, they learn about code semantics from the natural language aspects of the code (e.g. identifier names) and can generalize better to previously unseen code.