 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOAST: Fast and scalable auto-partitioning based on principled static analysis
Aug 20, 2025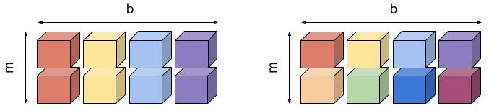


Partitioning large machine learning models across distributed accelerator systems is a complex process, requiring a series of interdependent decisions that are further complicated by internal sharding ambiguities. Consequently, existing auto-partitioners often suffer from out-of-memory errors or are prohibitively slow when exploring the exponentially large space of possible partitionings. To mitigate this, they artificially restrict the search space, but this approach frequently yields infeasible solutions that violate device memory constraints or lead to sub-optimal performance. We propose a system that combines a novel static compiler analysis with a Monte Carlo Tree Search. Our analysis constructs an efficient decision space by identifying (i) tensor dimensions requiring identical sharding, and (ii) partitioning "conflicts" that require resolution. Our system significantly outperforms state-of-the-art industrial methods across diverse hardware platforms and model architectures, discovering previously unknown, superior solutions, and the process is fully automated even for complex and large models.
PartIR: Composing SPMD Partitioning Strategies for Machine Learning
Jan 23, 2024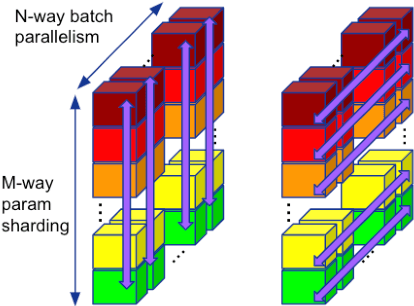
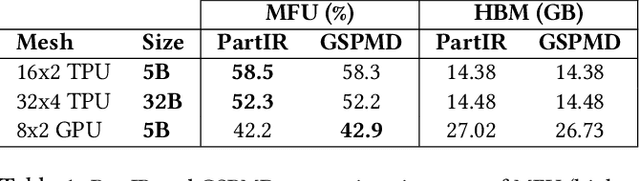
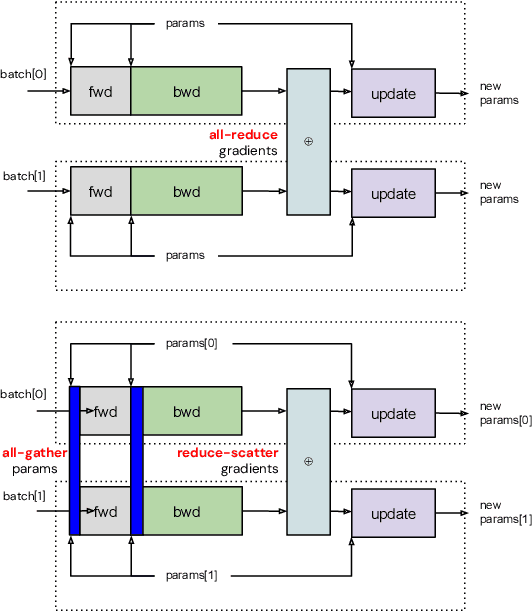
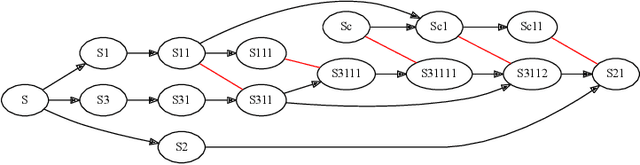
Training of modern large neural networks (NN) requires a combination of parallelization strategies encompassing data, model, or optimizer sharding. When strategies increase in complexity, it becomes necessary for partitioning tools to be 1) expressive, allowing the composition of simpler strategies, and 2) predictable to estimate performance analytically. We present PartIR, our design for a NN partitioning system. PartIR is focused on an incremental approach to rewriting and is hardware-and-runtime agnostic. We present a simple but powerful API for composing sharding strategies and a simulator to validate them. The process is driven by high-level programmer-issued partitioning tactics, which can be both manual and automatic. Importantly, the tactics are specified separately from the model code, making them easy to change. We evaluate PartIR on several different models to demonstrate its predictability, expressibility, and ability to reach peak performance..
Automatic Discovery of Composite SPMD Partitioning Strategies in PartIR
Oct 07, 2022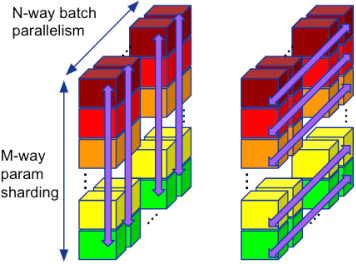


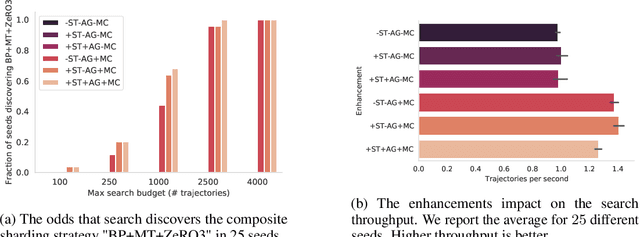
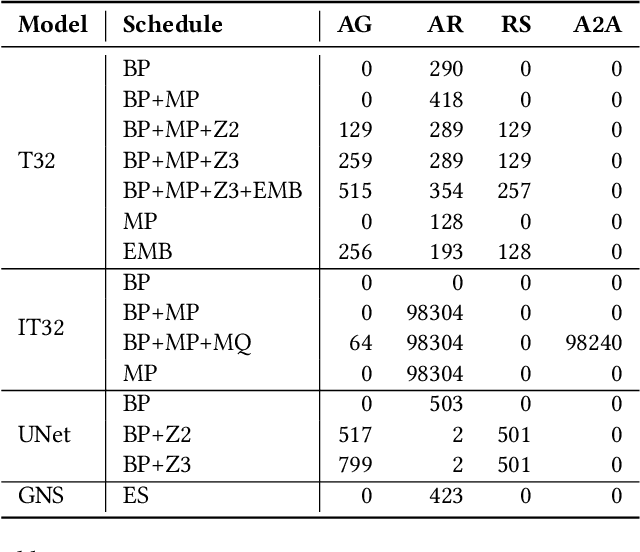
Large neural network models are commonly trained through a combination of advanced parallelism strategies in a single program, multiple data (SPMD) paradigm. For example, training large transformer models requires combining data, model, and pipeline partitioning; and optimizer sharding techniques. However, identifying efficient combinations for many model architectures and accelerator systems requires significant manual analysis. In this work, we present an automatic partitioner that identifies these combinations through a goal-oriented search. Our key findings are that a Monte Carlo Tree Search-based partitioner leveraging partition-specific compiler analysis directly into the search and guided goals matches expert-level strategies for various models.
RLFlow: Optimising Neural Network Subgraph Transformation with World Models
May 09, 2022
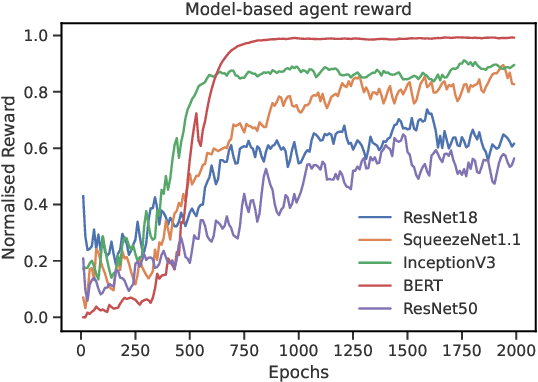
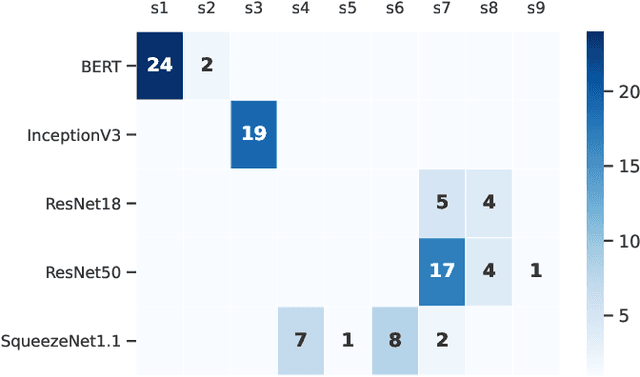
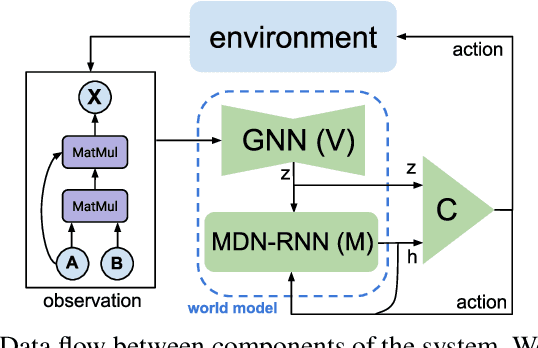
Training deep learning models takes an extremely long execution time and consumes large amounts of computing resources. At the same time, recent research proposed systems and compilers that are expected to decrease deep learning models runtime. An effective optimisation methodology in data processing is desirable, and the reduction of compute requirements of deep learning models is the focus of extensive research. In this paper, we address the neural network sub-graph transformation by exploring reinforcement learning (RL) agents to achieve performance improvement. Our proposed approach RLFlow can learn to perform neural network subgraph transformations, without the need for expertly designed heuristics to achieve a high level of performance. Recent work has aimed at applying RL to computer systems with some success, especially using model-free RL techniques. Model-based reinforcement learning methods have seen an increased focus in research as they can be used to learn the transition dynamics of the environment; this can be leveraged to train an agent using a hallucinogenic environment such as World Model (WM), thereby increasing sample efficiency compared to model-free approaches. WM uses variational auto-encoders and it builds a model of the system and allows exploring the model in an inexpensive way. In RLFlow, we propose a design for a model-based agent with WM which learns to optimise the architecture of neural networks by performing a sequence of sub-graph transformations to reduce model runtime. We show that our approach can match the state-of-the-art performance on common convolutional networks and outperforms by up to 5% those based on transformer-style architectures
BoGraph: Structured Bayesian Optimization From Logs for Systems with High-dimensional Parameter Space
Dec 16, 2021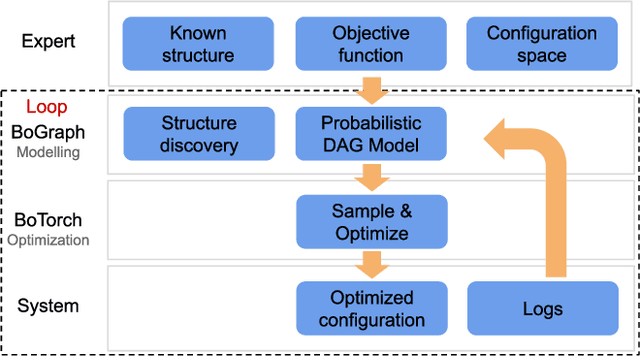

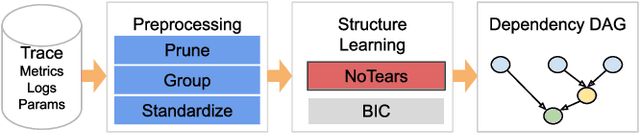

Current auto-tuning frameworks struggle with tuning computer systems configurations due to their large parameter space, complex interdependencies, and high evaluation cost. Utilizing probabilistic models, Structured Bayesian Optimization (SBO) has recently overcome these difficulties. SBO decomposes the parameter space by utilizing contextual information provided by system experts leading to fast convergence. However, the complexity of building probabilistic models has hindered its wider adoption. We propose BoAnon, a SBO framework that learns the system structure from its logs. BoAnon provides an API enabling experts to encode knowledge of the system as performance models or components dependency. BoAnon takes in the learned structure and transforms it into a probabilistic graph model. Then it applies the expert-provided knowledge to the graph to further contextualize the system behavior. BoAnon probabilistic graph allows the optimizer to find efficient configurations faster than other methods. We evaluate BoAnon via a hardware architecture search problem, achieving an improvement in energy-latency objectives ranging from $5-7$ x-factors improvement over the default architecture. With its novel contextual structure learning pipeline, BoAnon makes using SBO accessible for a wide range of other computer systems such as databases and stream processors.
High-Dimensional Bayesian Optimization with Multi-Task Learning for RocksDB
Mar 31, 2021

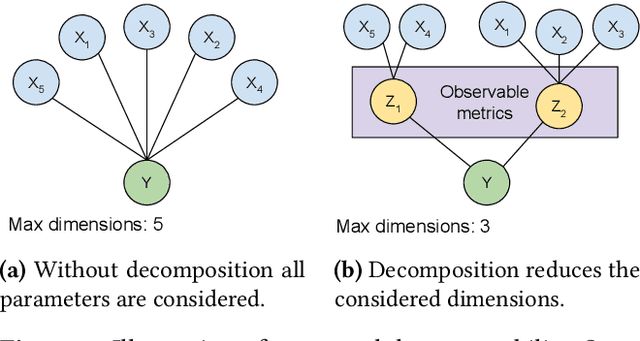

RocksDB is a general-purpose embedded key-value store used in multiple different settings. Its versatility comes at the cost of complex tuning configurations. This paper investigates maximizing the throughput of RocksDB IO operations by auto-tuning ten parameters of varying ranges. Off-the-shelf optimizers struggle with high-dimensional problem spaces and require a large number of training samples. We propose two techniques to tackle this problem: multi-task modeling and dimensionality reduction through a manual grouping of parameters. By incorporating adjacent optimization in the model, the model converged faster and found complicated settings that other tuners could not find. This approach had an additional computational complexity overhead, which we mitigated by manually assigning parameters to each sub-goal through our knowledge of RocksDB. The model is then incorporated in a standard Bayesian Optimization loop to find parameters that maximize RocksDB's IO throughput. Our method achieved x1.3 improvement when benchmarked against a simulation of Facebook's social graph traffic, and converged in ten optimization steps compared to other state-of-the-art methods that required fifty steps.
RLCache: Automated Cache Management Using Reinforcement Learning
Sep 30, 2019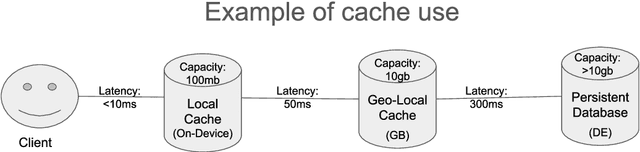
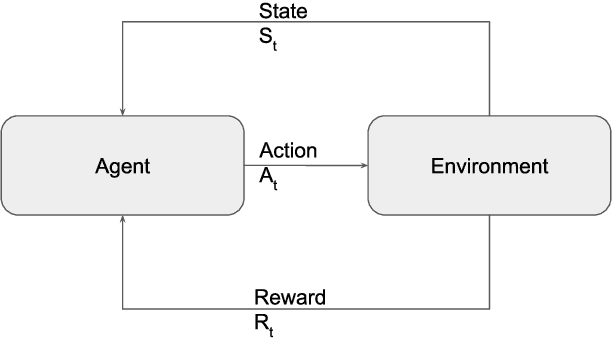
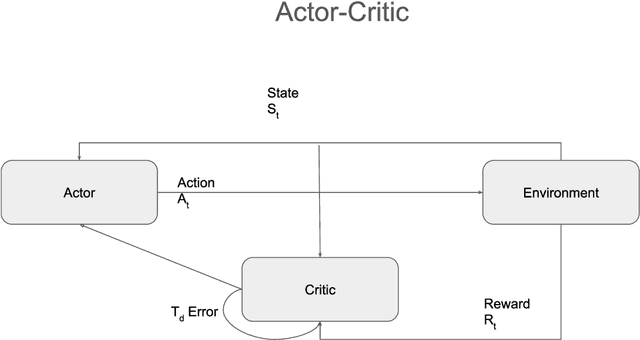
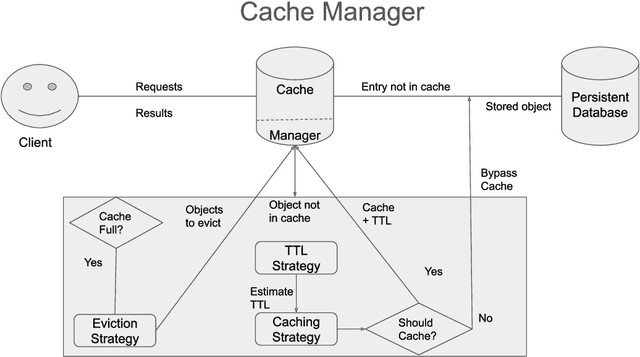
This study investigates the use of reinforcement learning to guide a general purpose cache manager decisions. Cache managers directly impact the overall performance of computer systems. They govern decisions about which objects should be cached, the duration they should be cached for, and decides on which objects to evict from the cache if it is full. These three decisions impact both the cache hit rate and size of the storage that is needed to achieve that cache hit rate. An optimal cache manager will avoid unnecessary operations, maximise the cache hit rate which results in fewer round trips to a slower backend storage system, and minimise the size of storage needed to achieve a high hit-rate. This project investigates using reinforcement learning in cache management by designing three separate agents for each of the cache manager tasks. Furthermore, the project investigates two advanced reinforcement learning architectures for multi-decision problems: a single multi-task agent and a multi-agent. We also introduce a framework to simplify the modelling of computer systems problems as a reinforcement learning task. The framework abstracts delayed experiences observations and reward assignment in computer systems while providing a flexible way to scale to multiple agents. Simulation results based on an established database benchmark system show that reinforcement learning agents can achieve a higher cache hit rate over heuristic driven algorithms while minimising the needed space. They are also able to adapt to a changing workload and dynamically adjust their caching strategy accordingly. The proposed cache manager model is generic and applicable to other types of caches, such as file system caches. This project is the first, to our knowledge, to model cache manager decisions as a multi-task control problem.