 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Paradigm in Tuning Learned Indexes: A Reinforcement Learning Enhanced Approach
Feb 07, 2025

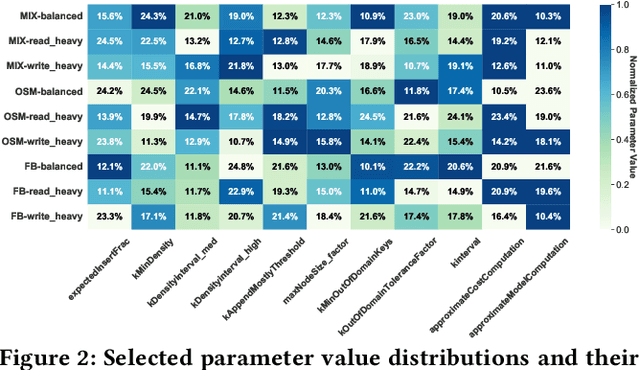

Learned Index Structures (LIS) have significantly advanced data management by leveraging machine learning models to optimize data indexing. However, designing these structures often involves critical trade-offs, making it challenging for both designers and end-users to find an optimal balance tailored to specific workloads and scenarios. While some indexes offer adjustable parameters that demand intensive manual tuning, others rely on fixed configurations based on heuristic auto-tuners or expert knowledge, which may not consistently deliver optimal performance. This paper introduces LITune, a novel framework for end-to-end automatic tuning of Learned Index Structures. LITune employs an adaptive training pipeline equipped with a tailor-made Deep Reinforcement Learning (DRL) approach to ensure stable and efficient tuning. To accommodate long-term dynamics arising from online tuning, we further enhance LITune with an on-the-fly updating mechanism termed the O2 system. These innovations allow LITune to effectively capture state transitions in online tuning scenarios and dynamically adjust to changing data distributions and workloads, marking a significant improvement over other tuning methods. Our experimental results demonstrate that LITune achieves up to a 98% reduction in runtime and a 17-fold increase in throughput compared to default parameter settings given a selected Learned Index instance. These findings highlight LITune's effectiveness and its potential to facilitate broader adoption of LIS in real-world applications.
CuAsmRL: Optimizing GPU SASS Schedules via Deep Reinforcement Learning
Jan 14, 2025

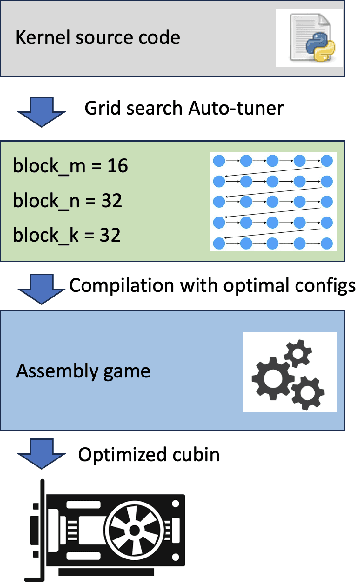

Large language models (LLMs) are remarked by their substantial computational requirements. To mitigate the cost, researchers develop specialized CUDA kernels, which often fuse several tensor operations to maximize the utilization of GPUs as much as possible. However, those specialized kernels may still leave performance on the table as CUDA assembly experts show that manual optimization of GPU SASS schedules can lead to better performance, and trial-and-error is largely employed to manually find the best GPU SASS schedules. In this work, we employ an automatic approach to optimize GPU SASS schedules, which thus can be integrated into existing compiler frameworks. The key to automatic optimization is training an RL agent to mimic how human experts perform manual scheduling. To this end, we formulate an assembly game, where RL agents can play to find the best GPU SASS schedules. The assembly game starts from a \textit{-O3} optimized SASS schedule, and the RL agents can iteratively apply actions to mutate the current schedules. Positive rewards are generated if the mutated schedules get higher throughput by executing on GPUs. Experiments show that CuAsmRL can further improve the performance of existing specialized CUDA kernels transparently by up to $26\%$, and on average $9\%$. Moreover, it is used as a tool to reveal potential optimization moves learned automatically.
HiBO: Hierarchical Bayesian Optimization via Adaptive Search Space Partitioning
Oct 31, 2024



Optimizing black-box functions in high-dimensional search spaces has been known to be challenging for traditional Bayesian Optimization (BO). In this paper, we introduce HiBO, a novel hierarchical algorithm integrating global-level search space partitioning information into the acquisition strategy of a local BO-based optimizer. HiBO employs a search-tree-based global-level navigator to adaptively split the search space into partitions with different sampling potential. The local optimizer then utilizes this global-level information to guide its acquisition strategy towards most promising regions within the search space. A comprehensive set of evaluations demonstrates that HiBO outperforms state-of-the-art methods in high-dimensional synthetic benchmarks and presents significant practical effectiveness in the real-world task of tuning configurations of database management systems (DBMSs).
Optimizing Tensor Computation Graphs with Equality Saturation and Monte Carlo Tree Search
Oct 07, 2024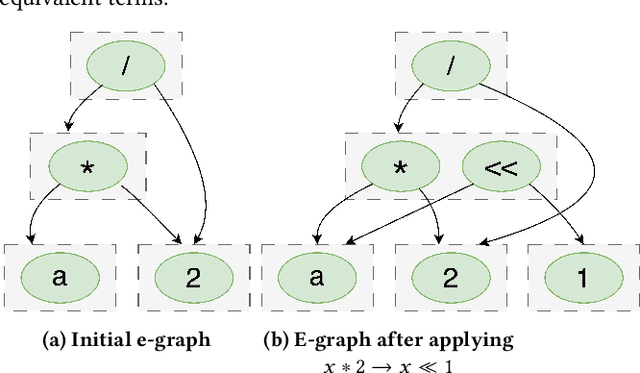

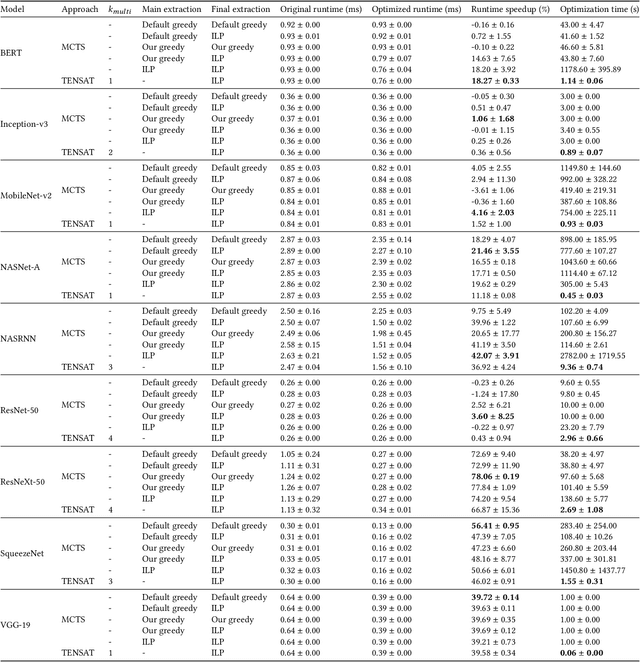
The real-world effectiveness of deep neural networks often depends on their latency, thereby necessitating optimization techniques that can reduce a model's inference time while preserving its performance. One popular approach is to sequentially rewrite the input computation graph into an equivalent but faster one by replacing individual subgraphs. This approach gives rise to the so-called phase-ordering problem in which the application of one rewrite rule can eliminate the possibility to apply an even better one later on. Recent work has shown that equality saturation, a technique from compiler optimization, can mitigate this issue by first building an intermediate representation (IR) that efficiently stores multiple optimized versions of the input program before extracting the best solution in a second step. In practice, however, memory constraints prevent the IR from capturing all optimized versions and thus reintroduce the phase-ordering problem in the construction phase. In this paper, we present a tensor graph rewriting approach that uses Monte Carlo tree search to build superior IRs by identifying the most promising rewrite rules. We also introduce a novel extraction algorithm that can provide fast and accurate runtime estimates of tensor programs represented in an IR. Our approach improves the inference speedup of neural networks by up to 11% compared to existing methods.
IA2: Leveraging Instance-Aware Index Advisor with Reinforcement Learning for Diverse Workloads
Apr 10, 2024



This study introduces the Instance-Aware Index Advisor (IA2), a novel deep reinforcement learning (DRL)-based approach for optimizing index selection in databases facing large action spaces of potential candidates. IA2 introduces the Twin Delayed Deep Deterministic Policy Gradient - Temporal Difference State-Wise Action Refinery (TD3-TD-SWAR) model, enabling efficient index selection by understanding workload-index dependencies and employing adaptive action masking. This method includes a comprehensive workload model, enhancing its ability to adapt to unseen workloads and ensuring robust performance across diverse database environments. Evaluation on benchmarks such as TPC-H reveals IA2's suggested indexes' performance in enhancing runtime, securing a 40% reduction in runtime for complex TPC-H workloads compared to scenarios without indexes, and delivering a 20% improvement over existing state-of-the-art DRL-based index advisors.
SIP: Autotuning GPU Native Schedules via Stochastic Instruction Perturbation
Mar 25, 2024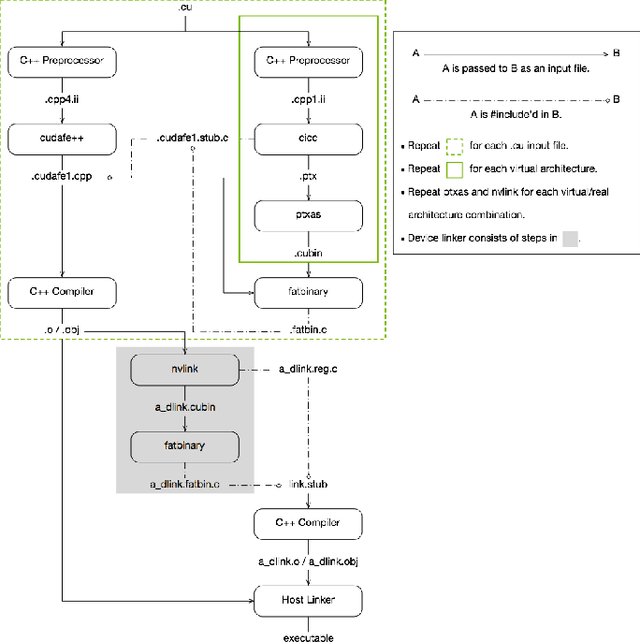
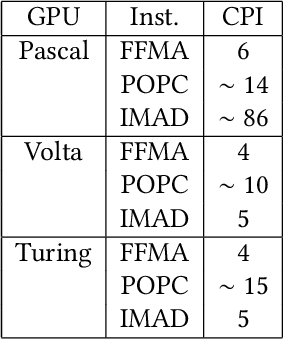
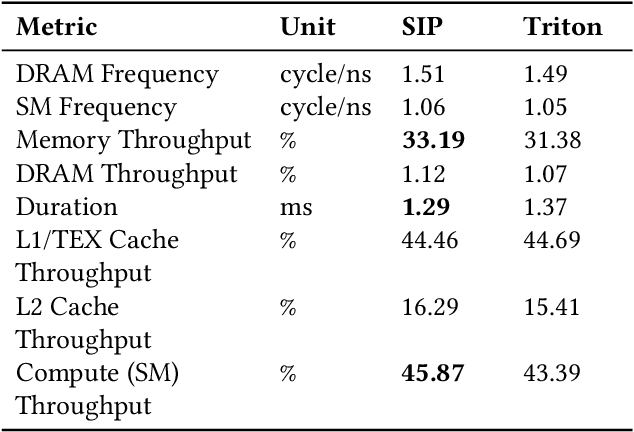
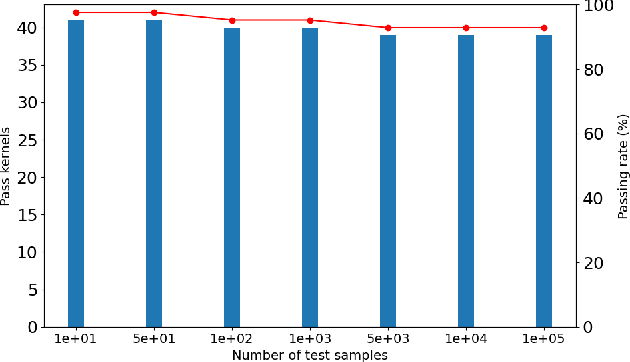
Large language models (LLMs) have become a significant workload since their appearance. However, they are also computationally expensive as they have billions of parameters and are trained with massive amounts of data. Thus, recent works have developed dedicated CUDA kernels for LLM training and inference instead of relying on compilergenerated ones, so that hardware resources are as fully utilized as possible. In this work, we explore the possibility of GPU native instruction optimization to further push the CUDA kernels to extreme performance. Contrary to prior works, we adopt an automatic optimization approach by defining a search space of possible GPU native instruction schedules, and then we apply stochastic search to perform optimization. Experiments show that SIP can further improve CUDA kernel throughput by automatically discovering better GPU native instruction schedules and the optimized schedules are tested by 10 million test samples.
X-RLflow: Graph Reinforcement Learning for Neural Network Subgraphs Transformation
Apr 28, 2023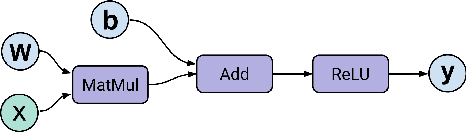
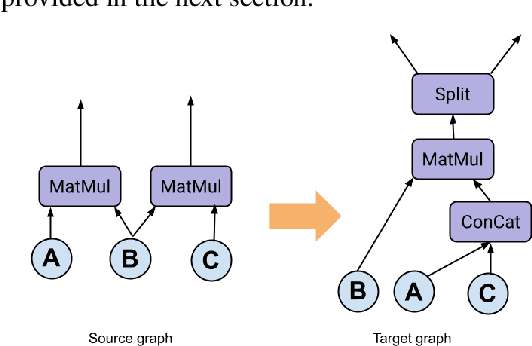
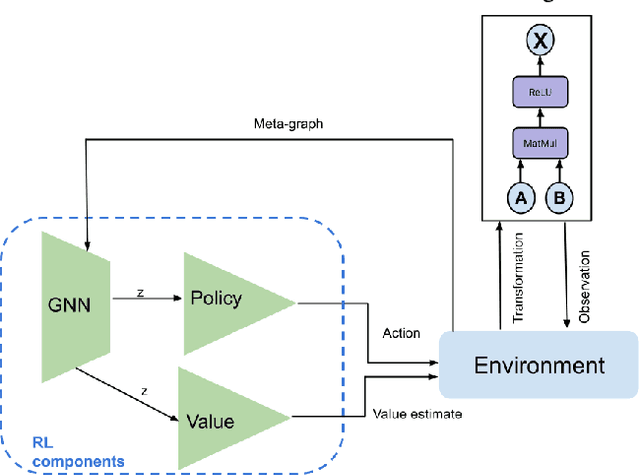
Tensor graph superoptimisation systems perform a sequence of subgraph substitution to neural networks, to find the optimal computation graph structure. Such a graph transformation process naturally falls into the framework of sequential decision-making, and existing systems typically employ a greedy search approach, which cannot explore the whole search space as it cannot tolerate a temporary loss of performance. In this paper, we address the tensor graph superoptimisation problem by exploring an alternative search approach, reinforcement learning (RL). Our proposed approach, X-RLflow, can learn to perform neural network dataflow graph rewriting, which substitutes a subgraph one at a time. X-RLflow is based on a model-free RL agent that uses a graph neural network (GNN) to encode the target computation graph and outputs a transformed computation graph iteratively. We show that our approach can outperform state-of-the-art superoptimisation systems over a range of deep learning models and achieve by up to 40% on those that are based on transformer-style architectures.
MCTS-GEB: Monte Carlo Tree Search is a Good E-graph Builder
Mar 08, 2023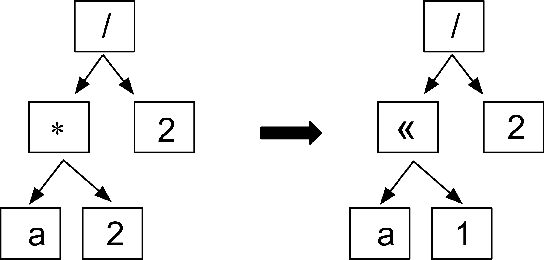
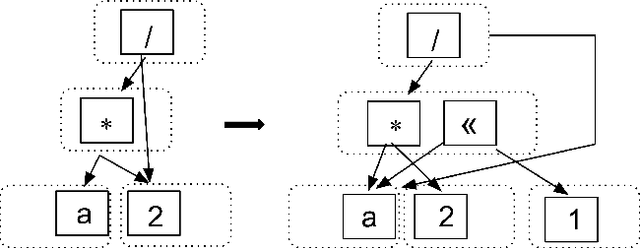
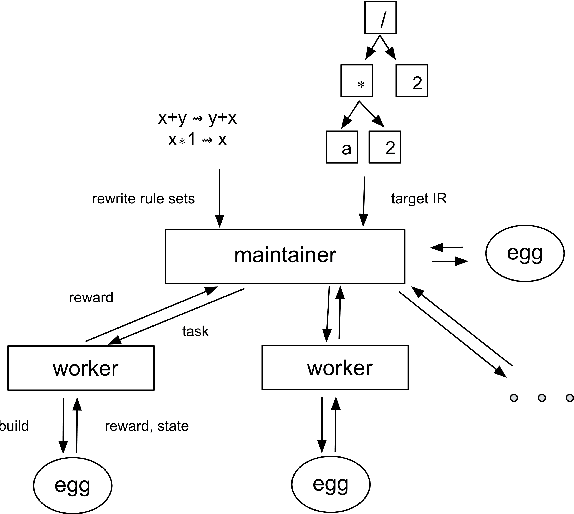
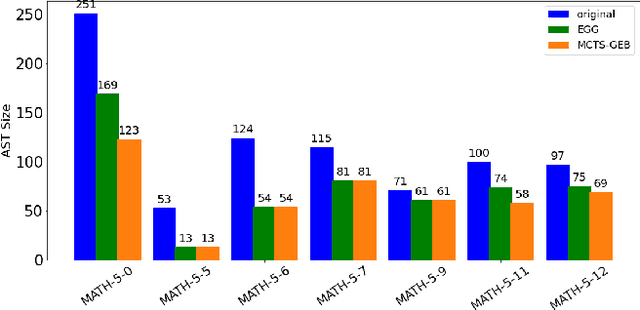
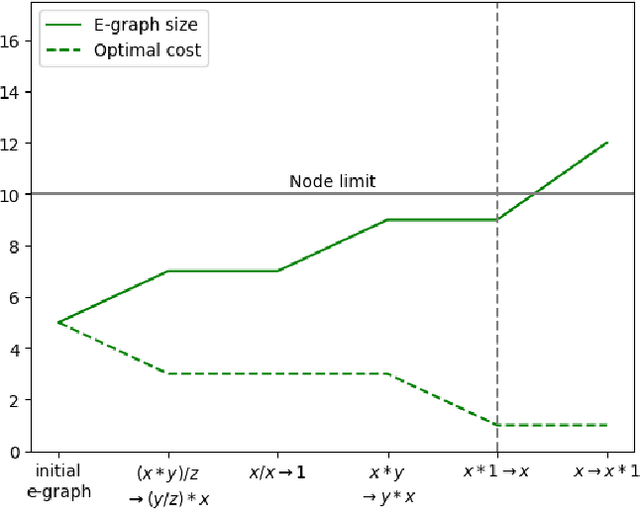
Rewrite systems [6, 10, 12] have been widely employing equality saturation [9], which is an optimisation methodology that uses a saturated e-graph to represent all possible sequences of rewrite simultaneously, and then extracts the optimal one. As such, optimal results can be achieved by avoiding the phase-ordering problem. However, we observe that when the e-graph is not saturated, it cannot represent all possible rewrite opportunities and therefore the phase-ordering problem is re-introduced during the construction phase of the e-graph. To address this problem, we propose MCTS-GEB, a domain-general rewrite system that applies reinforcement learning (RL) to e-graph construction. At its core, MCTS-GEB uses a Monte Carlo Tree Search (MCTS) [3] to efficiently plan for the optimal e-graph construction, and therefore it can effectively eliminate the phase-ordering problem at the construction phase and achieve better performance within a reasonable time. Evaluation in two different domains shows MCTS-GEB can outperform the state-of-the-art rewrite systems by up to 49x, while the optimisation can generally take less than an hour, indicating MCTS-GEB is a promising building block for the future generation of rewrite systems.
RLFlow: Optimising Neural Network Subgraph Transformation with World Models
May 09, 2022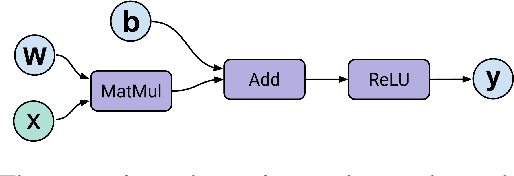
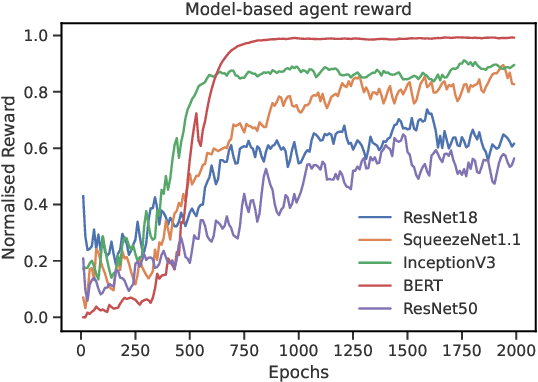
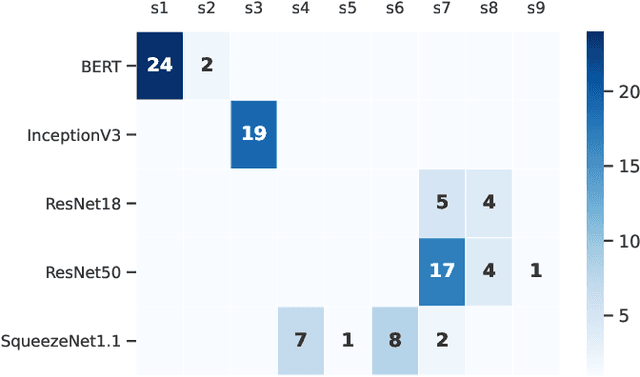
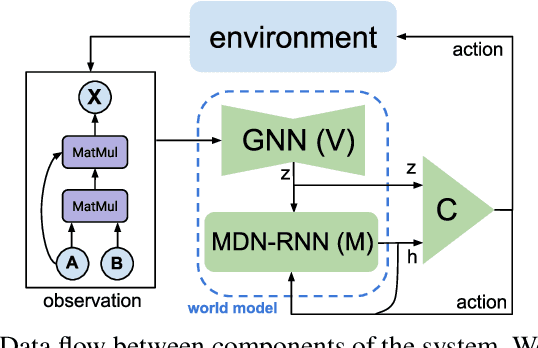
Training deep learning models takes an extremely long execution time and consumes large amounts of computing resources. At the same time, recent research proposed systems and compilers that are expected to decrease deep learning models runtime. An effective optimisation methodology in data processing is desirable, and the reduction of compute requirements of deep learning models is the focus of extensive research. In this paper, we address the neural network sub-graph transformation by exploring reinforcement learning (RL) agents to achieve performance improvement. Our proposed approach RLFlow can learn to perform neural network subgraph transformations, without the need for expertly designed heuristics to achieve a high level of performance. Recent work has aimed at applying RL to computer systems with some success, especially using model-free RL techniques. Model-based reinforcement learning methods have seen an increased focus in research as they can be used to learn the transition dynamics of the environment; this can be leveraged to train an agent using a hallucinogenic environment such as World Model (WM), thereby increasing sample efficiency compared to model-free approaches. WM uses variational auto-encoders and it builds a model of the system and allows exploring the model in an inexpensive way. In RLFlow, we propose a design for a model-based agent with WM which learns to optimise the architecture of neural networks by performing a sequence of sub-graph transformations to reduce model runtime. We show that our approach can match the state-of-the-art performance on common convolutional networks and outperforms by up to 5% those based on transformer-style architectures
BoGraph: Structured Bayesian Optimization From Logs for Systems with High-dimensional Parameter Space
Dec 16, 2021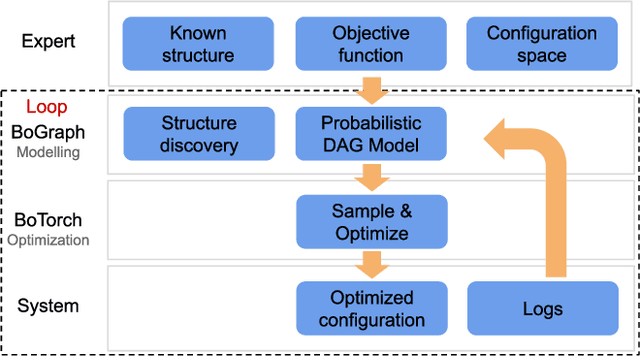

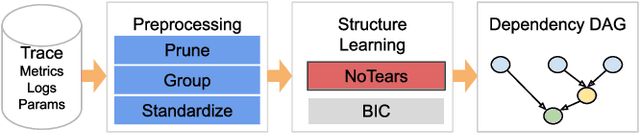

Current auto-tuning frameworks struggle with tuning computer systems configurations due to their large parameter space, complex interdependencies, and high evaluation cost. Utilizing probabilistic models, Structured Bayesian Optimization (SBO) has recently overcome these difficulties. SBO decomposes the parameter space by utilizing contextual information provided by system experts leading to fast convergence. However, the complexity of building probabilistic models has hindered its wider adoption. We propose BoAnon, a SBO framework that learns the system structure from its logs. BoAnon provides an API enabling experts to encode knowledge of the system as performance models or components dependency. BoAnon takes in the learned structure and transforms it into a probabilistic graph model. Then it applies the expert-provided knowledge to the graph to further contextualize the system behavior. BoAnon probabilistic graph allows the optimizer to find efficient configurations faster than other methods. We evaluate BoAnon via a hardware architecture search problem, achieving an improvement in energy-latency objectives ranging from $5-7$ x-factors improvement over the default architecture. With its novel contextual structure learning pipeline, BoAnon makes using SBO accessible for a wide range of other computer systems such as databases and stream processors.