 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-RLflow: Graph Reinforcement Learning for Neural Network Subgraphs Transformation
Apr 28, 2023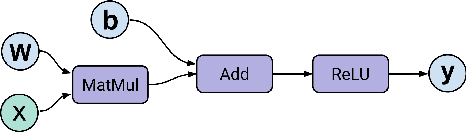
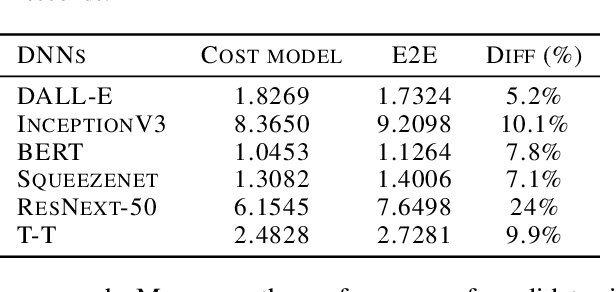
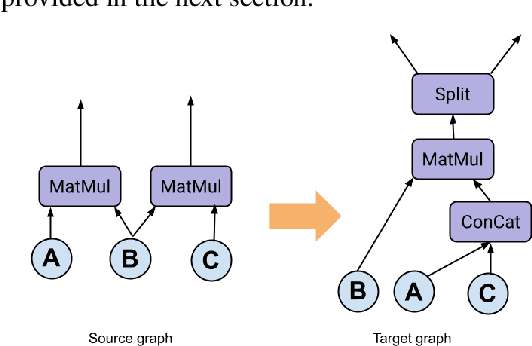
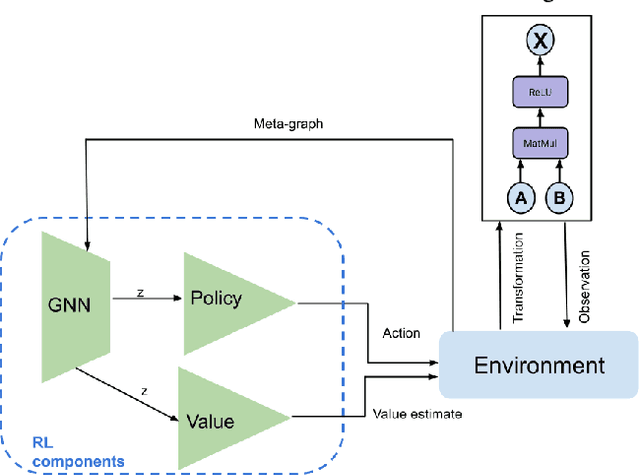
Tensor graph superoptimisation systems perform a sequence of subgraph substitution to neural networks, to find the optimal computation graph structure. Such a graph transformation process naturally falls into the framework of sequential decision-making, and existing systems typically employ a greedy search approach, which cannot explore the whole search space as it cannot tolerate a temporary loss of performance. In this paper, we address the tensor graph superoptimisation problem by exploring an alternative search approach, reinforcement learning (RL). Our proposed approach, X-RLflow, can learn to perform neural network dataflow graph rewriting, which substitutes a subgraph one at a time. X-RLflow is based on a model-free RL agent that uses a graph neural network (GNN) to encode the target computation graph and outputs a transformed computation graph iteratively. We show that our approach can outperform state-of-the-art superoptimisation systems over a range of deep learning models and achieve by up to 40% on those that are based on transformer-style architectures.
RLFlow: Optimising Neural Network Subgraph Transformation with World Models
May 09, 2022
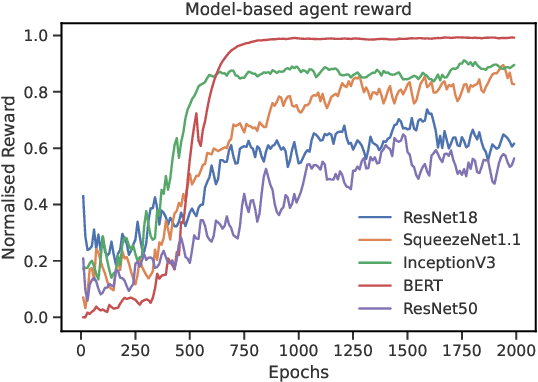
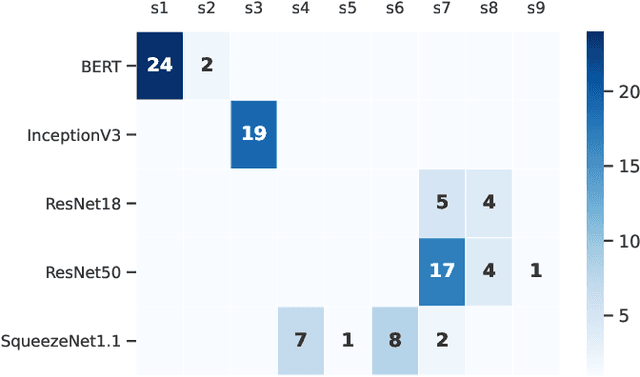
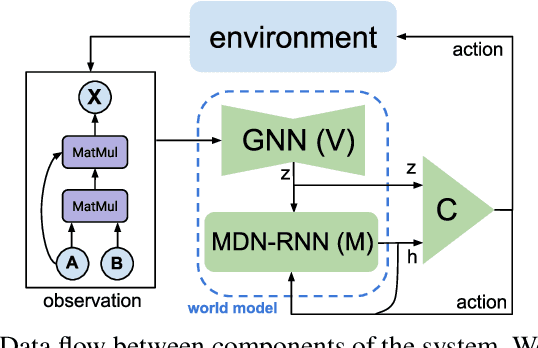
Training deep learning models takes an extremely long execution time and consumes large amounts of computing resources. At the same time, recent research proposed systems and compilers that are expected to decrease deep learning models runtime. An effective optimisation methodology in data processing is desirable, and the reduction of compute requirements of deep learning models is the focus of extensive research. In this paper, we address the neural network sub-graph transformation by exploring reinforcement learning (RL) agents to achieve performance improvement. Our proposed approach RLFlow can learn to perform neural network subgraph transformations, without the need for expertly designed heuristics to achieve a high level of performance. Recent work has aimed at applying RL to computer systems with some success, especially using model-free RL techniques. Model-based reinforcement learning methods have seen an increased focus in research as they can be used to learn the transition dynamics of the environment; this can be leveraged to train an agent using a hallucinogenic environment such as World Model (WM), thereby increasing sample efficiency compared to model-free approaches. WM uses variational auto-encoders and it builds a model of the system and allows exploring the model in an inexpensive way. In RLFlow, we propose a design for a model-based agent with WM which learns to optimise the architecture of neural networks by performing a sequence of sub-graph transformations to reduce model runtime. We show that our approach can match the state-of-the-art performance on common convolutional networks and outperforms by up to 5% those based on transformer-style architectures