 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLower Bounds for the Algorithmic Complexity of Learned Indexes
Jan 10, 2026Learned index structures aim to accelerate queries by training machine learning models to approximate the rank function associated with a database attribute. While effective in practice, their theoretical limitations are not fully understood. We present a general framework for proving lower bounds on query time for learned indexes, expressed in terms of their space overhead and parameterized by the model class used for approximation. Our formulation captures a broad family of learned indexes, including most existing designs, as piecewise model-based predictors. We solve the problem of lower bounding query time in two steps: first, we use probabilistic tools to control the effect of sampling when the database attribute is drawn from a probability distribution. Then, we analyze the approximation-theoretic problem of how to optimally represent a cumulative distribution function with approximators from a given model class. Within this framework, we derive lower bounds under a range of modeling and distributional assumptions, paying particular attention to the case of piecewise linear and piecewise constant model classes, which are common in practical implementations. Our analysis shows how tools from approximation theory, such as quantization and Kolmogorov widths, can be leveraged to formalize the space-time tradeoffs inherent to learned index structures. The resulting bounds illuminate core limitations of these methods.
Inclusive Training Separation and Implicit Knowledge Interaction for Balanced Online Class-Incremental Learning
Apr 29, 2025



Online class-incremental learning (OCIL) focuses on gradually learning new classes (called plasticity) from a stream of data in a single-pass, while concurrently preserving knowledge of previously learned classes (called stability). The primary challenge in OCIL lies in maintaining a good balance between the knowledge of old and new classes within the continually updated model. Most existing methods rely on explicit knowledge interaction through experience replay, and often employ exclusive training separation to address bias problems. Nevertheless, it still remains a big challenge to achieve a well-balanced learner, as these methods often exhibit either reduced plasticity or limited stability due to difficulties in continually integrating knowledge in the OCIL setting. In this paper, we propose a novel replay-based method, called Balanced Online Incremental Learning (BOIL), which can achieve both high plasticity and stability, thus ensuring more balanced performance in OCIL. Our BOIL method proposes an inclusive training separation strategy using dual classifiers so that knowledge from both old and new classes can effectively be integrated into the model, while introducing implicit approaches for transferring knowledge across the two classifiers. Extensive experimental evaluations over three widely-used OCIL benchmark datasets demonstrate the superiority of BOIL, showing more balanced yet better performance compared to state-of-the-art replay-based OCIL methods.
A New Paradigm in Tuning Learned Indexes: A Reinforcement Learning Enhanced Approach
Feb 07, 2025

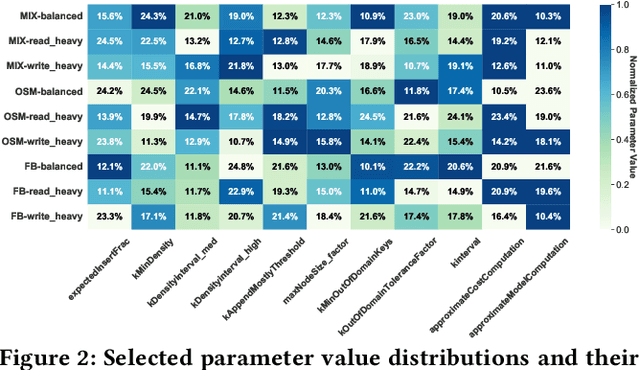

Learned Index Structures (LIS) have significantly advanced data management by leveraging machine learning models to optimize data indexing. However, designing these structures often involves critical trade-offs, making it challenging for both designers and end-users to find an optimal balance tailored to specific workloads and scenarios. While some indexes offer adjustable parameters that demand intensive manual tuning, others rely on fixed configurations based on heuristic auto-tuners or expert knowledge, which may not consistently deliver optimal performance. This paper introduces LITune, a novel framework for end-to-end automatic tuning of Learned Index Structures. LITune employs an adaptive training pipeline equipped with a tailor-made Deep Reinforcement Learning (DRL) approach to ensure stable and efficient tuning. To accommodate long-term dynamics arising from online tuning, we further enhance LITune with an on-the-fly updating mechanism termed the O2 system. These innovations allow LITune to effectively capture state transitions in online tuning scenarios and dynamically adjust to changing data distributions and workloads, marking a significant improvement over other tuning methods. Our experimental results demonstrate that LITune achieves up to a 98% reduction in runtime and a 17-fold increase in throughput compared to default parameter settings given a selected Learned Index instance. These findings highlight LITune's effectiveness and its potential to facilitate broader adoption of LIS in real-world applications.
Single Exposure Quantitative Phase Imaging with a Conventional Microscope using Diffusion Models
Jun 06, 2024Phase imaging is gaining importance due to its applications in fields like biomedical imaging and material characterization. In biomedical applications, it can provide quantitative information missing in label-free microscopy modalities. One of the most prominent methods in phase quantification is the Transport-of-Intensity Equation (TIE). TIE often requires multiple acquisitions at different defocus distances, which is not always feasible in a clinical setting. To address this issue, we propose to use chromatic aberrations to induce the required through-focus images with a single exposure, effectively generating a through-focus stack. Since the defocus distance induced by the aberrations is small, conventional TIE solvers are insufficient to address the resulting artifacts. We propose Zero-Mean Diffusion, a modified version of diffusion models designed for quantitative image prediction, and train it with synthetic data to ensure robust phase retrieval. Our contributions offer an alternative TIE approach that leverages chromatic aberrations, achieving accurate single-exposure phase measurement with white light and thus improving the efficiency of phase imaging. Moreover, we present a new class of diffusion models that are well-suited for quantitative data and have a sound theoretical basis. To validate our approach, we employ a widespread brightfield microscope equipped with a commercially available color camera. We apply our model to clinical microscopy of patients' urine, obtaining accurate phase measurements.
Conditional Variational Diffusion Models
Dec 04, 2023



Inverse problems aim to determine parameters from observations, a crucial task in engineering and science. Lately, generative models, especially diffusion models, have gained popularity in this area for their ability to produce realistic solutions and their good mathematical properties. Despite their success, an important drawback of diffusion models is their sensitivity to the choice of variance schedule, which controls the dynamics of the diffusion process. Fine-tuning this schedule for specific applications is crucial but time-costly and does not guarantee an optimal result. We propose a novel approach for learning the schedule as part of the training process. Our method supports probabilistic conditioning on data, provides high-quality solutions, and is flexible, proving able to adapt to different applications with minimum overhead. This approach is tested in two unrelated inverse problems: super-resolution microscopy and quantitative phase imaging, yielding comparable or superior results to previous methods and fine-tuned diffusion models. We conclude that fine-tuning the schedule by experimentation should be avoided because it can be learned during training in a stable way that yields better results.
DNA data storage, sequencing data-carrying DNA
May 11, 2022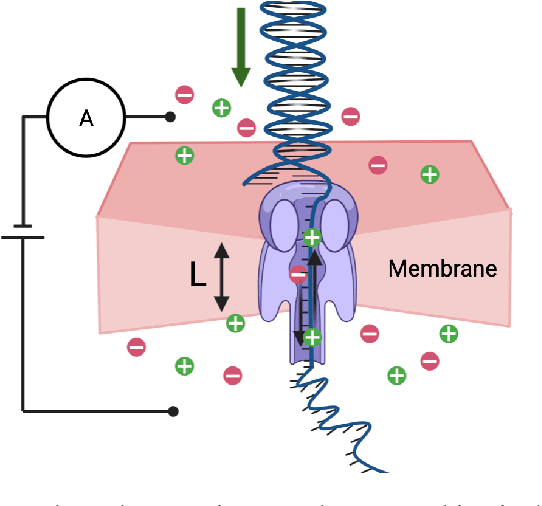
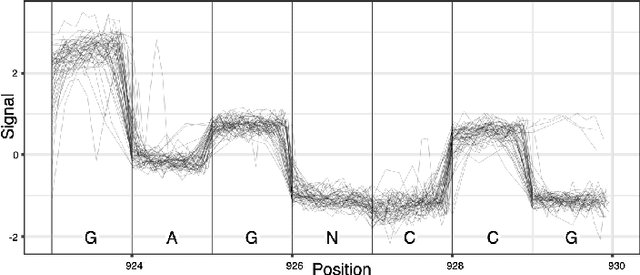
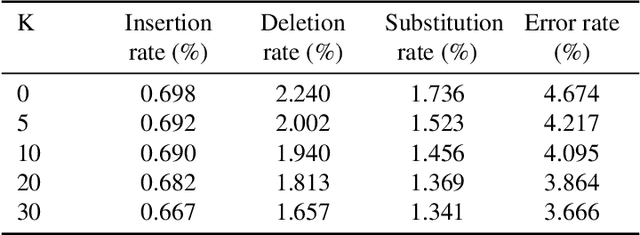
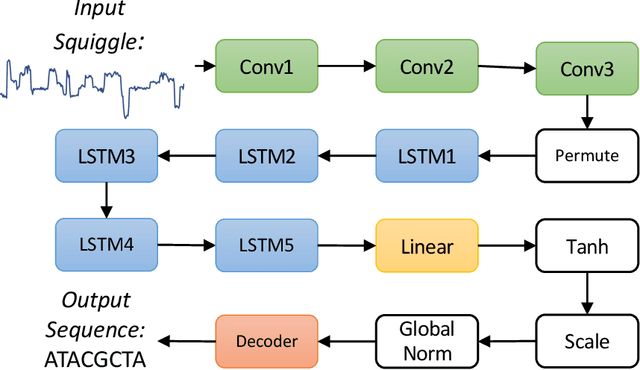
DNA is a leading candidate as the next archival storage media due to its density, durability and sustainability. To read (and write) data DNA storage exploits technology that has been developed over decades to sequence naturally occurring DNA in the life sciences. To achieve higher accuracy for previously unseen, biological DNA, sequencing relies on extending and training deep machine learning models known as basecallers. This growth in model complexity requires substantial resources, both computational and data sets. It also eliminates the possibility of a compact read head for DNA as a storage medium. We argue that we need to depart from blindly using sequencing models from the life sciences for DNA data storage. The difference is striking: for life science applications we have no control over the DNA, however, in the case of DNA data storage, we control how it is written, as well as the particular write head. More specifically, data-carrying DNA can be modulated and embedded with alignment markers and error correcting codes to guarantee higher fidelity and to carry out some of the work that the machine learning models perform. In this paper, we study accuracy trade-offs between deep model size and error correcting codes. We show that, starting with a model size of 107MB, the reduced accuracy from model compression can be compensated by using simple error correcting codes in the DNA sequences. In our experiments, we show that a substantial reduction in the size of the model does not incur an undue penalty for the error correcting codes used, therefore paving the way for portable data-carrying DNA read head. Crucially, we show that through the joint use of model compression and error correcting codes, we achieve a higher read accuracy than without compression and error correction codes.
Hands-off Model Integration in Spatial Index Structures
Jun 29, 2020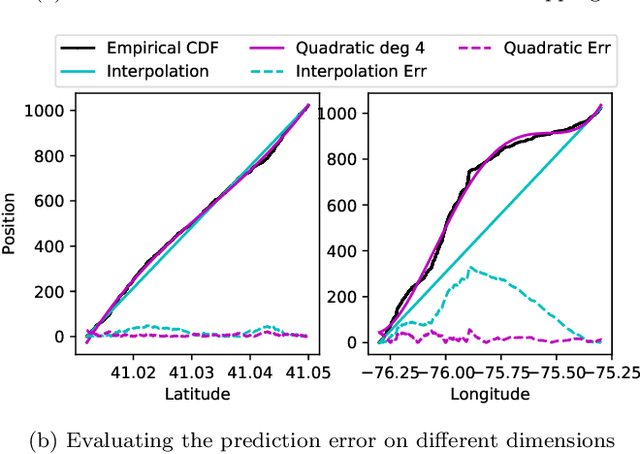
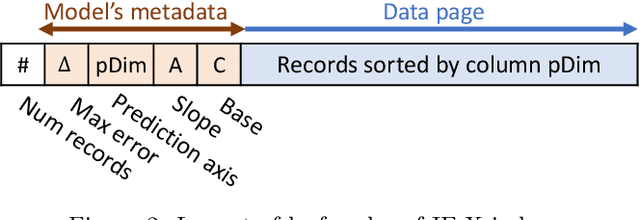
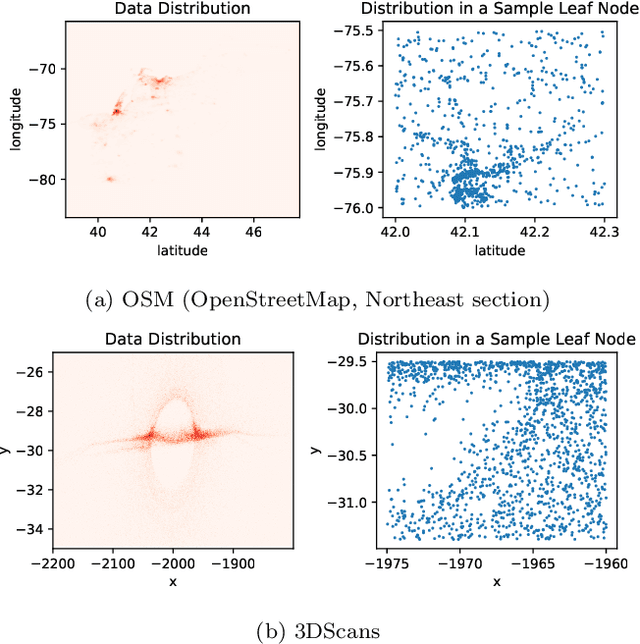
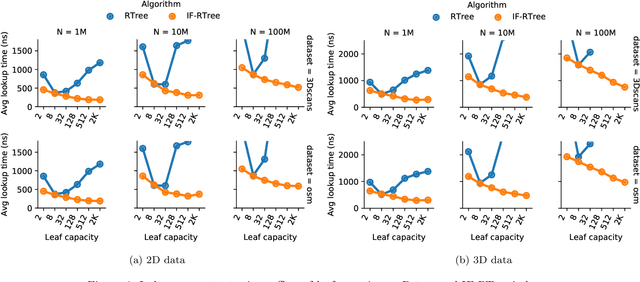
Spatial indexes are crucial for the analysis of the increasing amounts of spatial data, for example generated through IoT applications. The plethora of indexes that has been developed in recent decades has primarily been optimised for disk. With increasing amounts of memory even on commodity machines, however, moving them to main memory is an option. Doing so opens up the opportunity to use additional optimizations that are only amenable to main memory. In this paper we thus explore the opportunity to use light-weight machine learning models to accelerate queries on spatial indexes. We do so by exploring the potential of using interpolation and similar techniques on the R-tree, arguably the most broadly used spatial index. As we show in our experimental analysis, the query execution time can be reduced by up to 60% while simultaneously shrinking the index's memory footprint by over 90%
Leveraging Soft Functional Dependencies for Indexing Multi-dimensional Data
Jun 29, 2020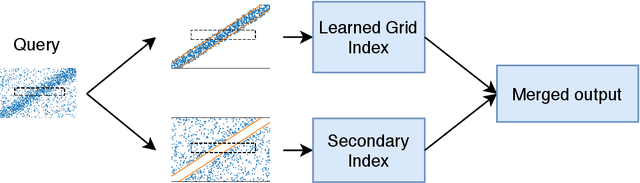

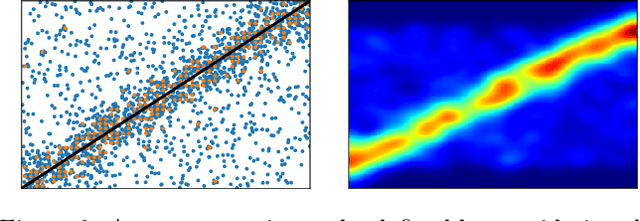
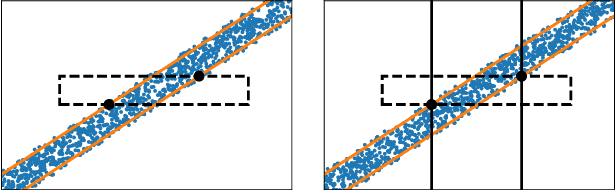
A new proposal in database indexing has been for index structures to automatically learn and use the distribution of the underlying data to improve their performance. Initial work on \textit{learned indexes} has repeatedly shown that by learning the distribution of the data, index structures such as the B-Tree, can boost their performance by an order of magnitude while using a smaller memory footprint. In this work we propose a new class of learned indexes for multidimensional data that instead of learning only from distribution of keys, learns from correlations between columns of the dataset. Our approach is motivated by the observation that in real datasets, correlation between two or more attributes of the data is a common occurrence. This idea of learning from functional dependencies has been previously explored and implemented in many state of the art query optimisers to predict selectivity of queries and come up with better query plans. In this project we aim to take the use of learned functional dependencies a step further in databases. Consequently, we focus on using learned functional dependencies to reduce the dimensionality of datasets. With this we attempt to work around the curse of dimensionality - which in the context of spatial data stipulates that with every additional dimension, the performance of an index deteriorates further - to accelerate query execution. In more precise terms, we learn how to infer one (or multiple) attributes from the remaining attributes and hence no longer need to index predicted columns. This method reduces the dimensionality of the index and thus makes it more efficient. We show experimentally that by predicting correlated attributes in the data, rather than indexing them, we can improve the query execution time and reduce the memory overhead of the index at the same time.