 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning-Friendly Biomedical Datasets for Equivalence and Subsumption Ontology Matching
May 06, 2022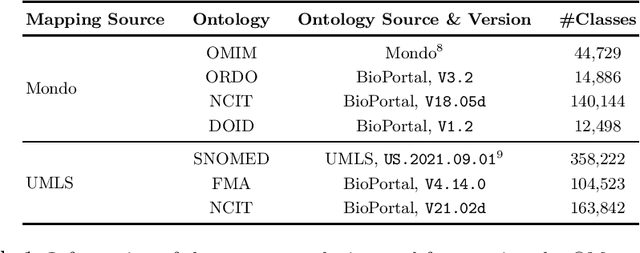
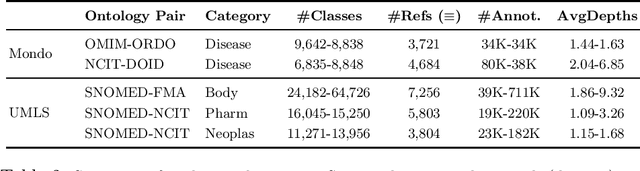
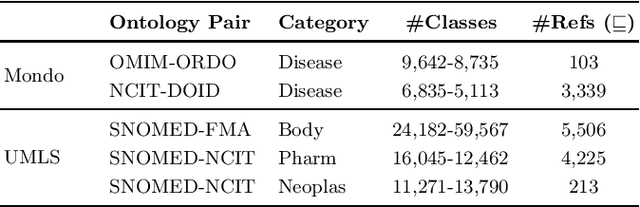
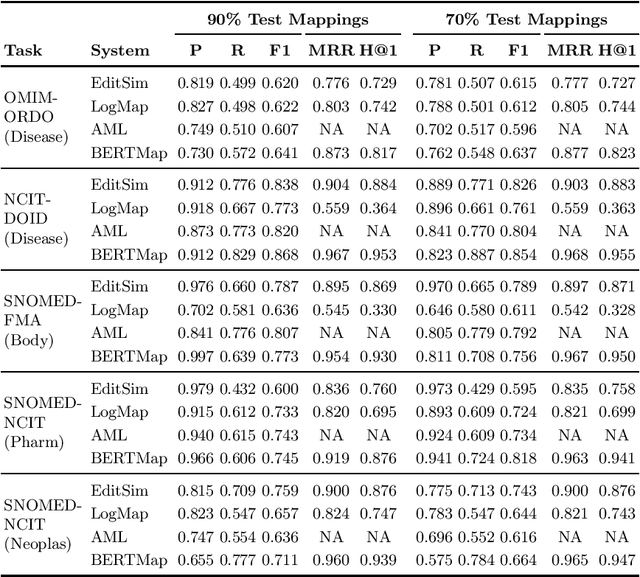
Ontology Matching (OM) plays an important role in many domains such as bioinformatics and the Semantic Web, and its research is becoming increasingly popular, especially with the application of machine learning (ML) techniques. Although the Ontology Alignment Evaluation Initiative (OAEI) represents an impressive effort for the systematic evaluation of OM systems, it still suffers from several limitations including limited evaluation of subsumption mappings, suboptimal reference mappings, and limited support for the evaluation of ML-based systems. To tackle these limitations, we introduce five new biomedical OM tasks involving ontologies extracted from Mondo and UMLS. Each task includes both equivalence and subsumption matching; the quality of reference mappings is ensured by human curation, ontology pruning, etc.; and a comprehensive evaluation framework is proposed to measure OM performance from various perspectives for both ML-based and non-ML-based OM systems. We report evaluation results for OM systems of different types to demonstrate the usage of these resources, all of which are publicly available
Hands-off Model Integration in Spatial Index Structures
Jun 29, 2020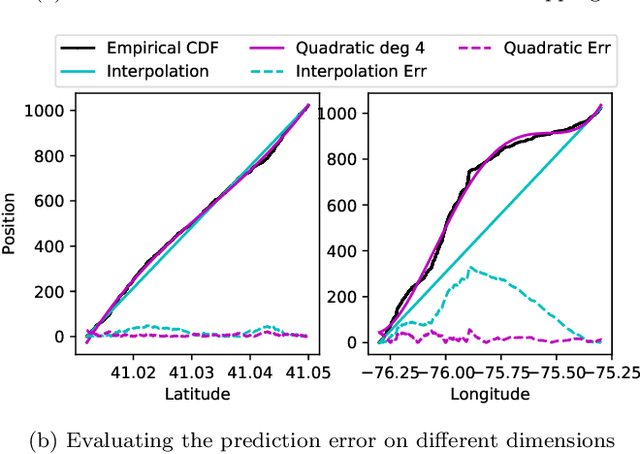
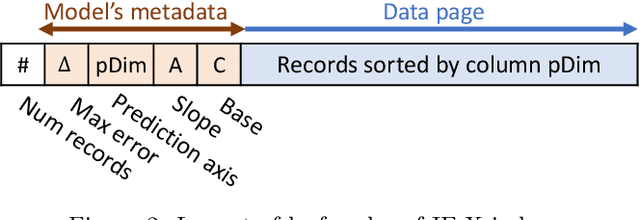
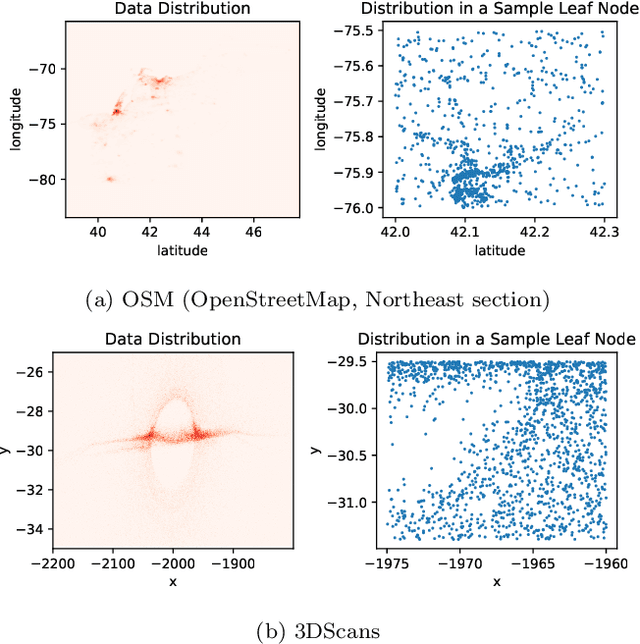
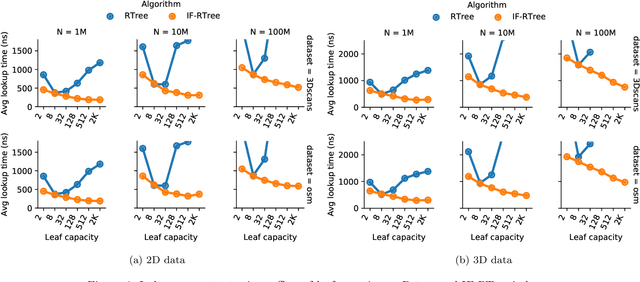
Spatial indexes are crucial for the analysis of the increasing amounts of spatial data, for example generated through IoT applications. The plethora of indexes that has been developed in recent decades has primarily been optimised for disk. With increasing amounts of memory even on commodity machines, however, moving them to main memory is an option. Doing so opens up the opportunity to use additional optimizations that are only amenable to main memory. In this paper we thus explore the opportunity to use light-weight machine learning models to accelerate queries on spatial indexes. We do so by exploring the potential of using interpolation and similar techniques on the R-tree, arguably the most broadly used spatial index. As we show in our experimental analysis, the query execution time can be reduced by up to 60% while simultaneously shrinking the index's memory footprint by over 90%
Leveraging Soft Functional Dependencies for Indexing Multi-dimensional Data
Jun 29, 2020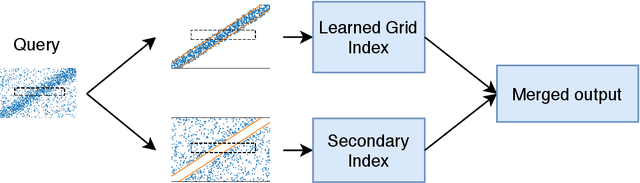

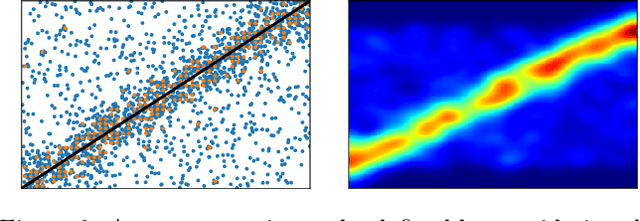
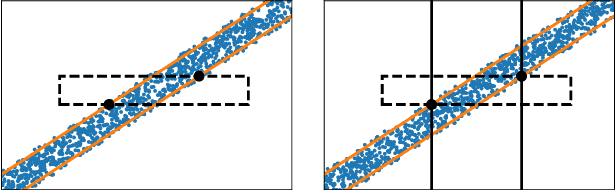
A new proposal in database indexing has been for index structures to automatically learn and use the distribution of the underlying data to improve their performance. Initial work on \textit{learned indexes} has repeatedly shown that by learning the distribution of the data, index structures such as the B-Tree, can boost their performance by an order of magnitude while using a smaller memory footprint. In this work we propose a new class of learned indexes for multidimensional data that instead of learning only from distribution of keys, learns from correlations between columns of the dataset. Our approach is motivated by the observation that in real datasets, correlation between two or more attributes of the data is a common occurrence. This idea of learning from functional dependencies has been previously explored and implemented in many state of the art query optimisers to predict selectivity of queries and come up with better query plans. In this project we aim to take the use of learned functional dependencies a step further in databases. Consequently, we focus on using learned functional dependencies to reduce the dimensionality of datasets. With this we attempt to work around the curse of dimensionality - which in the context of spatial data stipulates that with every additional dimension, the performance of an index deteriorates further - to accelerate query execution. In more precise terms, we learn how to infer one (or multiple) attributes from the remaining attributes and hence no longer need to index predicted columns. This method reduces the dimensionality of the index and thus makes it more efficient. We show experimentally that by predicting correlated attributes in the data, rather than indexing them, we can improve the query execution time and reduce the memory overhead of the index at the same time.
Multi-View Learning for Web Spam Detection
Jul 24, 2013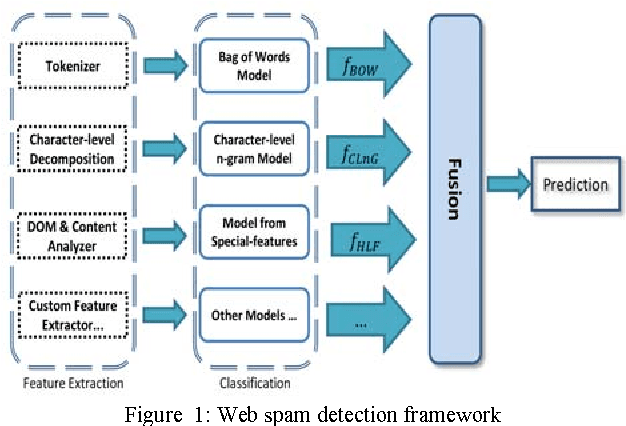
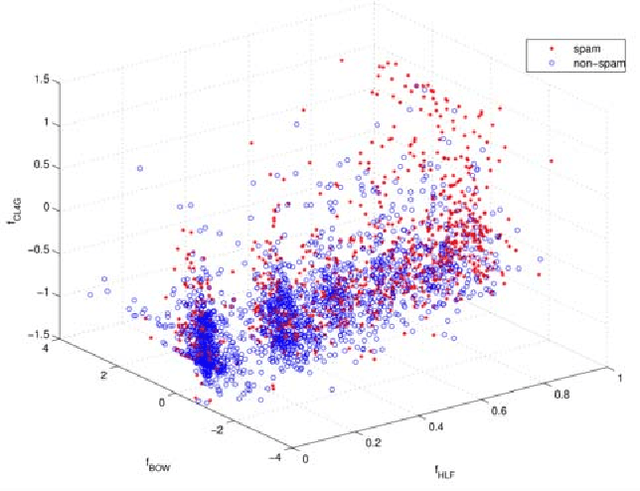
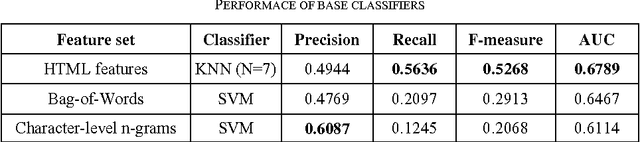
Spam pages are designed to maliciously appear among the top search results by excessive usage of popular terms. Therefore, spam pages should be removed using an effective and efficient spam detection system. Previous methods for web spam classification used several features from various information sources (page contents, web graph, access logs, etc.) to detect web spam. In this paper, we follow page-level classification approach to build fast and scalable spam filters. We show that each web page can be classified with satisfiable accuracy using only its own HTML content. In order to design a multi-view classification system, we used state-of-the-art spam classification methods with distinct feature sets (views) as the base classifiers. Then, a fusion model is learned to combine the output of the base classifiers and make final prediction. Results show that multi-view learning significantly improves the classification performance, namely AUC by 22%, while providing linear speedup for parallel execution.