 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise or Nuance: An Investigation Into Useful Information and Filtering For LLM Driven AKBC
Sep 10, 2025RAG and fine-tuning are prevalent strategies for improving the quality of LLM outputs. However, in constrained situations, such as that of the 2025 LM-KBC challenge, such techniques are restricted. In this work we investigate three facets of the triple completion task: generation, quality assurance, and LLM response parsing. Our work finds that in this constrained setting: additional information improves generation quality, LLMs can be effective at filtering poor quality triples, and the tradeoff between flexibility and consistency with LLM response parsing is setting dependent.
Towards a Knowledge Graph for Teaching Knowledge Graphs
Nov 02, 2024
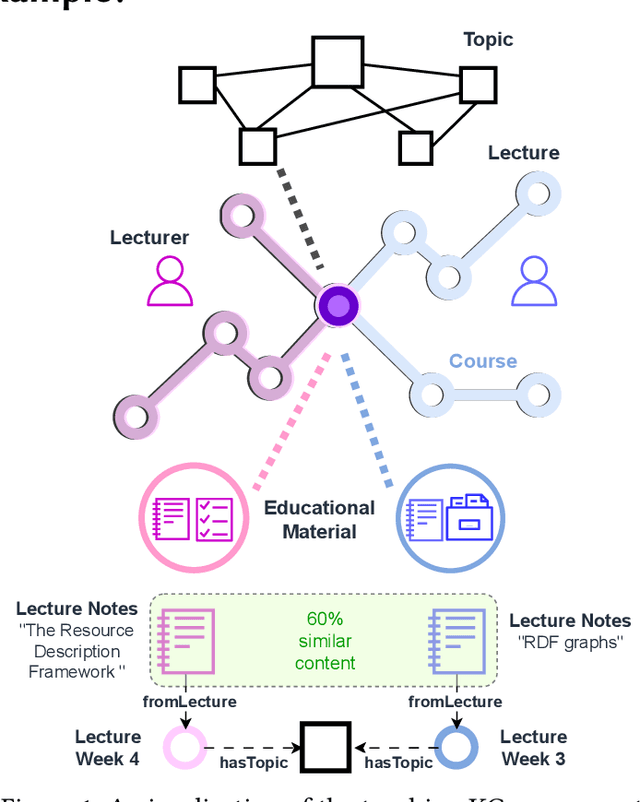
This poster paper describes the ongoing research project for the creation of a use-case-driven Knowledge Graph resource tailored to the needs of teaching education in Knowledge Graphs (KGs). We gather resources related to KG courses from lectures offered by the Semantic Web community, with the help of the COST Action Distributed Knowledge Graphs and the interest group on KGs at The Alan Turing Institute. Our goal is to create a resource-focused KG with multiple interconnected semantic layers that interlink topics, courses, and materials with each lecturer. Our approach formulates a domain KG in teaching and relates it with multiple Personal KGs created for the lecturers.
Information for Conversation Generation: Proposals Utilising Knowledge Graphs
Oct 21, 2024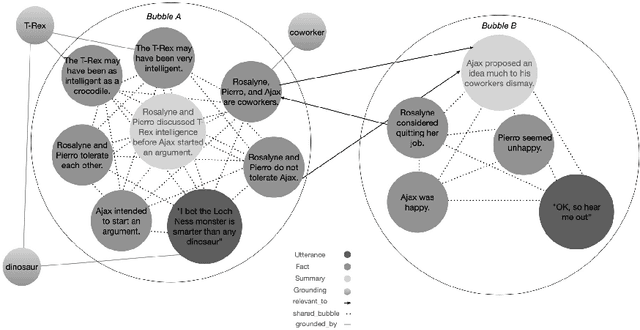
LLMs are frequently used tools for conversational generation. Without additional information LLMs can generate lower quality responses due to lacking relevant content and hallucinations, as well as the perception of poor emotional capability, and an inability to maintain a consistent character. Knowledge graphs are commonly used forms of external knowledge and may provide solutions to these challenges. This paper introduces three proposals, utilizing knowledge graphs to enhance LLM generation. Firstly, dynamic knowledge graph embeddings and recommendation could allow for the integration of new information and the selection of relevant knowledge for response generation. Secondly, storing entities with emotional values as additional features may provide knowledge that is better emotionally aligned with the user input. Thirdly, integrating character information through narrative bubbles would maintain character consistency, as well as introducing a structure that would readily incorporate new information.
OWL2Vec4OA: Tailoring Knowledge Graph Embeddings for Ontology Alignment
Aug 12, 2024



Ontology alignment is integral to achieving semantic interoperability as the number of available ontologies covering intersecting domains is increasing. This paper proposes OWL2Vec4OA, an extension of the ontology embedding system OWL2Vec*. While OWL2Vec* has emerged as a powerful technique for ontology embedding, it currently lacks a mechanism to tailor the embedding to the ontology alignment task. OWL2Vec4OA incorporates edge confidence values from seed mappings to guide the random walk strategy. We present the theoretical foundations, implementation details, and experimental evaluation of our proposed extension, demonstrating its potential effectiveness for ontology alignment tasks.
Knowledge Graphs for the Life Sciences: Recent Developments, Challenges and Opportunities
Oct 06, 2023
The term life sciences refers to the disciplines that study living organisms and life processes, and include chemistry, biology, medicine, and a range of other related disciplines. Research efforts in life sciences are heavily data-driven, as they produce and consume vast amounts of scientific data, much of which is intrinsically relational and graph-structured. The volume of data and the complexity of scientific concepts and relations referred to therein promote the application of advanced knowledge-driven technologies for managing and interpreting data, with the ultimate aim to advance scientific discovery. In this survey and position paper, we discuss recent developments and advances in the use of graph-based technologies in life sciences and set out a vision for how these technologies will impact these fields into the future. We focus on three broad topics: the construction and management of Knowledge Graphs (KGs), the use of KGs and associated technologies in the discovery of new knowledge, and the use of KGs in artificial intelligence applications to support explanations (explainable AI). We select a few exemplary use cases for each topic, discuss the challenges and open research questions within these topics, and conclude with a perspective and outlook that summarizes the overarching challenges and their potential solutions as a guide for future research.
NeSy4VRD: A Multifaceted Resource for Neurosymbolic AI Research using Knowledge Graphs in Visual Relationship Detection
May 22, 2023NeSy4VRD is a multifaceted resource designed to support the development of neurosymbolic AI (NeSy) research. NeSy4VRD re-establishes public access to the images of the VRD dataset and couples them with an extensively revised, quality-improved version of the VRD visual relationship annotations. Crucially, NeSy4VRD provides a well-aligned, companion OWL ontology that describes the dataset domain.It comes with open source infrastructure that provides comprehensive support for extensibility of the annotations (which, in turn, facilitates extensibility of the ontology), and open source code for loading the annotations to/from a knowledge graph. We are contributing NeSy4VRD to the computer vision, NeSy and Semantic Web communities to help foster more NeSy research using OWL-based knowledge graphs.
Language Model Analysis for Ontology Subsumption Inference
Feb 14, 2023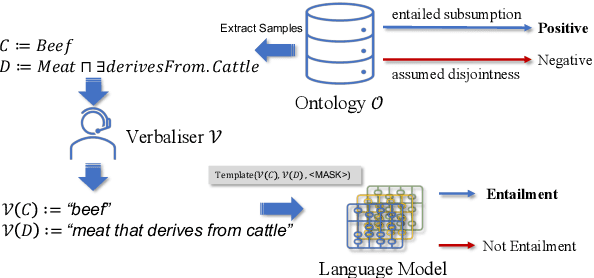

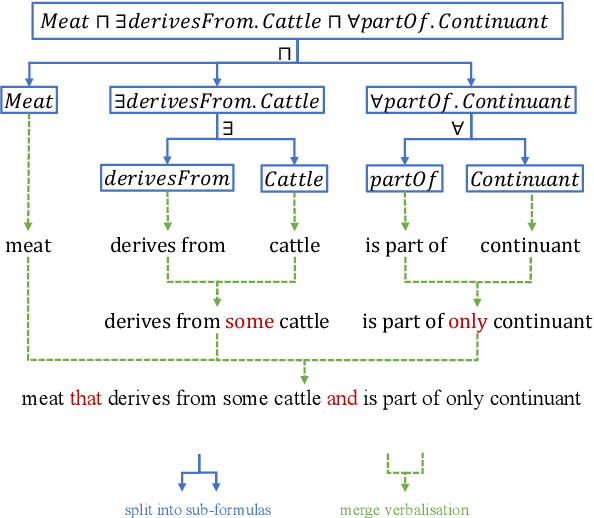
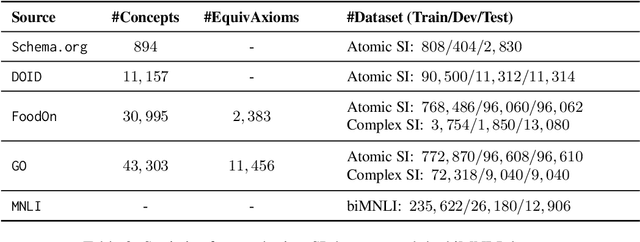
Pre-trained language models (LMs) have made significant advances in various Natural Language Processing (NLP) domains, but it is unclear to what extent they can infer formal semantics in ontologies, which are often used to represent conceptual knowledge and serve as the schema of data graphs. To investigate an LM's knowledge of ontologies, we propose OntoLAMA, a set of inference-based probing tasks and datasets from ontology subsumption axioms involving both atomic and complex concepts. We conduct extensive experiments on ontologies of different domains and scales, and our results demonstrate that LMs encode relatively less background knowledge of Subsumption Inference (SI) than traditional Natural Language Inference (NLI) but can improve on SI significantly when a small number of samples are given. We will open-source our code and datasets.
Query-based Industrial Analytics over Knowledge Graphs with Ontology Reshaping
Sep 22, 2022Industrial analytics that includes among others equipment diagnosis and anomaly detection heavily relies on integration of heterogeneous production data. Knowledge Graphs (KGs) as the data format and ontologies as the unified data schemata are a prominent solution that offers high quality data integration and a convenient and standardised way to exchange data and to layer analytical applications over it. However, poor design of ontologies of high degree of mismatch between them and industrial data naturally lead to KGs of low quality that impede the adoption and scalability of industrial analytics. Indeed, such KGs substantially increase the training time of writing queries for users, consume high volume of storage for redundant information, and are hard to maintain and update. To address this problem we propose an ontology reshaping approach to transform ontologies into KG schemata that better reflect the underlying data and thus help to construct better KGs. In this poster we present a preliminary discussion of our on-going research, evaluate our approach with a rich set of SPARQL queries on real-world industry data at Bosch and discuss our findings.
Machine Learning-Friendly Biomedical Datasets for Equivalence and Subsumption Ontology Matching
May 06, 2022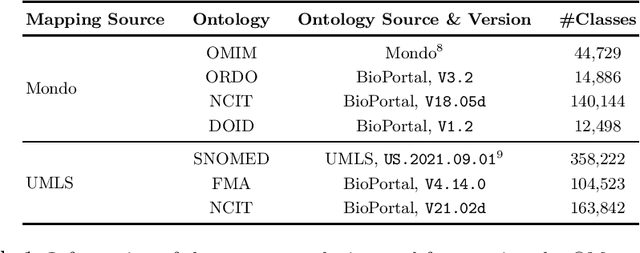
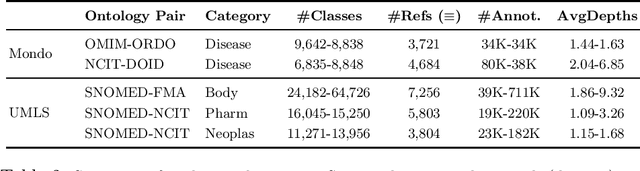
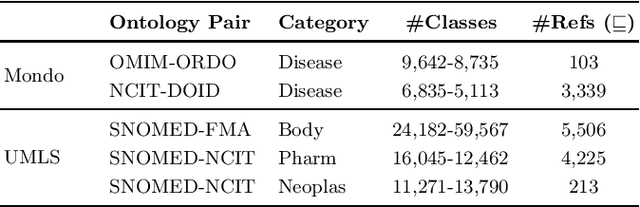
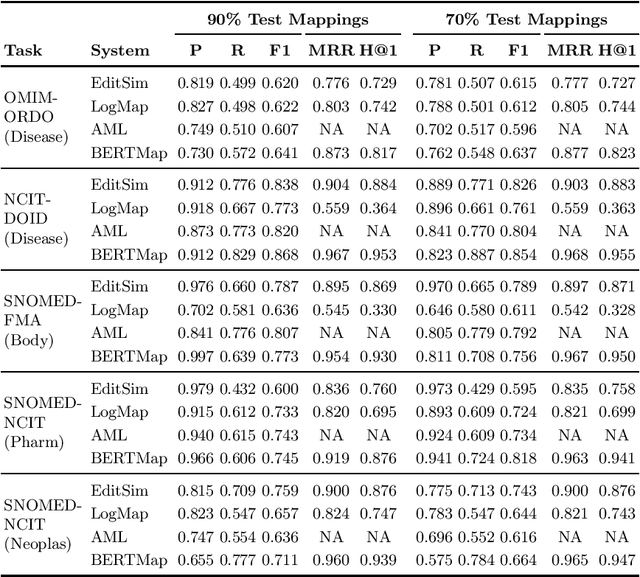
Ontology Matching (OM) plays an important role in many domains such as bioinformatics and the Semantic Web, and its research is becoming increasingly popular, especially with the application of machine learning (ML) techniques. Although the Ontology Alignment Evaluation Initiative (OAEI) represents an impressive effort for the systematic evaluation of OM systems, it still suffers from several limitations including limited evaluation of subsumption mappings, suboptimal reference mappings, and limited support for the evaluation of ML-based systems. To tackle these limitations, we introduce five new biomedical OM tasks involving ontologies extracted from Mondo and UMLS. Each task includes both equivalence and subsumption matching; the quality of reference mappings is ensured by human curation, ontology pruning, etc.; and a comprehensive evaluation framework is proposed to measure OM performance from various perspectives for both ML-based and non-ML-based OM systems. We report evaluation results for OM systems of different types to demonstrate the usage of these resources, all of which are publicly available
Prediction of Adverse Biological Effects of Chemicals Using Knowledge Graph Embeddings
Dec 08, 2021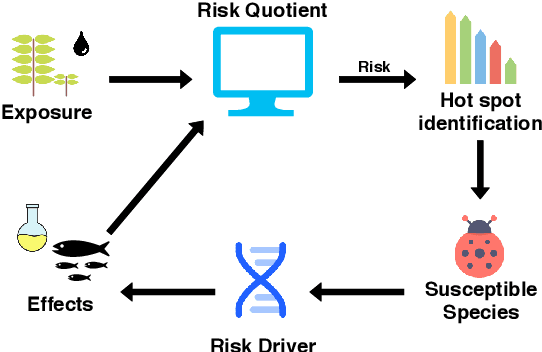
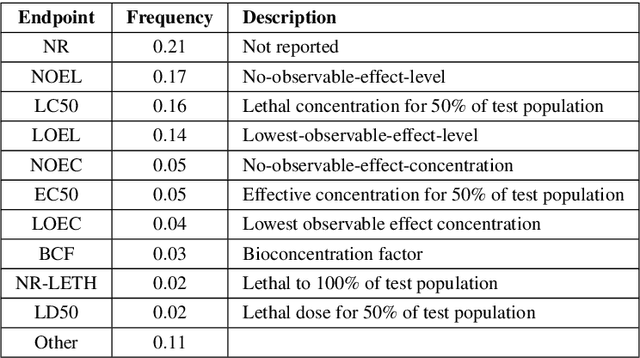
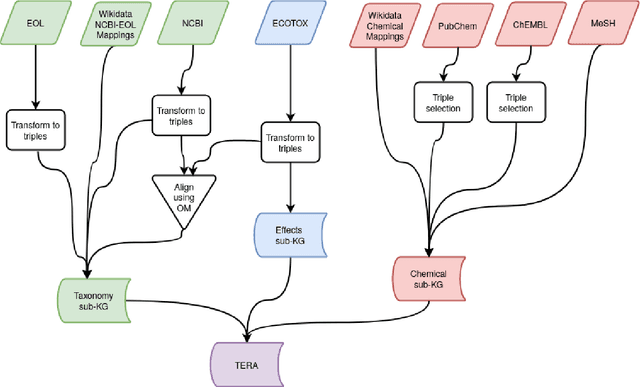
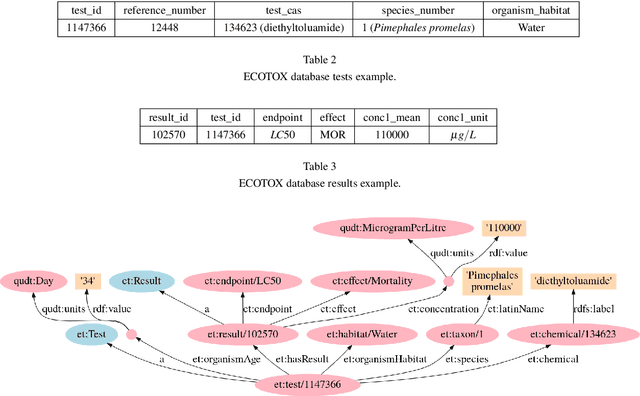
We have created a knowledge graph based on major data sources used in ecotoxicological risk assessment. We have applied this knowledge graph to an important task in risk assessment, namely chemical effect prediction. We have evaluated nine knowledge graph embedding models from a selection of geometric, decomposition, and convolutional models on this prediction task. We show that using knowledge graph embeddings can increase the accuracy of effect prediction with neural networks. Furthermore, we have implemented a fine-tuning architecture which adapts the knowledge graph embeddings to the effect prediction task and leads to a better performance. Finally, we evaluate certain characteristics of the knowledge graph embedding models to shed light on the individual model performance.