 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMOMgen: Complex Multi-Ontology Alignment via Pattern-Guided In-Context Learning
Oct 24, 2025



Constructing comprehensive knowledge graphs requires the use of multiple ontologies in order to fully contextualize data into a domain. Ontology matching finds equivalences between concepts interconnecting ontologies and creating a cohesive semantic layer. While the simple pairwise state of the art is well established, simple equivalence mappings cannot provide full semantic integration of related but disjoint ontologies. Complex multi-ontology matching (CMOM) aligns one source entity to composite logical expressions of multiple target entities, establishing more nuanced equivalences and provenance along the ontological hierarchy. We present CMOMgen, the first end-to-end CMOM strategy that generates complete and semantically sound mappings, without establishing any restrictions on the number of target ontologies or entities. Retrieval-Augmented Generation selects relevant classes to compose the mapping and filters matching reference mappings to serve as examples, enhancing In-Context Learning. The strategy was evaluated in three biomedical tasks with partial reference alignments. CMOMgen outperforms baselines in class selection, demonstrating the impact of having a dedicated strategy. Our strategy also achieves a minimum of 63% in F1-score, outperforming all baselines and ablated versions in two out of three tasks and placing second in the third. Furthermore, a manual evaluation of non-reference mappings showed that 46% of the mappings achieve the maximum score, further substantiating its ability to construct semantically sound mappings.
What can knowledge graph alignment gain with Neuro-Symbolic learning approaches?
Oct 11, 2023
Knowledge Graphs (KG) are the backbone of many data-intensive applications since they can represent data coupled with its meaning and context. Aligning KGs across different domains and providers is necessary to afford a fuller and integrated representation. A severe limitation of current KG alignment (KGA) algorithms is that they fail to articulate logical thinking and reasoning with lexical, structural, and semantic data learning. Deep learning models are increasingly popular for KGA inspired by their good performance in other tasks, but they suffer from limitations in explainability, reasoning, and data efficiency. Hybrid neurosymbolic learning models hold the promise of integrating logical and data perspectives to produce high-quality alignments that are explainable and support validation through human-centric approaches. This paper examines the current state of the art in KGA and explores the potential for neurosymbolic integration, highlighting promising research directions for combining these fields.
Knowledge Graphs for the Life Sciences: Recent Developments, Challenges and Opportunities
Oct 06, 2023The term life sciences refers to the disciplines that study living organisms and life processes, and include chemistry, biology, medicine, and a range of other related disciplines. Research efforts in life sciences are heavily data-driven, as they produce and consume vast amounts of scientific data, much of which is intrinsically relational and graph-structured. The volume of data and the complexity of scientific concepts and relations referred to therein promote the application of advanced knowledge-driven technologies for managing and interpreting data, with the ultimate aim to advance scientific discovery. In this survey and position paper, we discuss recent developments and advances in the use of graph-based technologies in life sciences and set out a vision for how these technologies will impact these fields into the future. We focus on three broad topics: the construction and management of Knowledge Graphs (KGs), the use of KGs and associated technologies in the discovery of new knowledge, and the use of KGs in artificial intelligence applications to support explanations (explainable AI). We select a few exemplary use cases for each topic, discuss the challenges and open research questions within these topics, and conclude with a perspective and outlook that summarizes the overarching challenges and their potential solutions as a guide for future research.
Biomedical Knowledge Graph Embeddings with Negative Statements
Aug 07, 2023



A knowledge graph is a powerful representation of real-world entities and their relations. The vast majority of these relations are defined as positive statements, but the importance of negative statements is increasingly recognized, especially under an Open World Assumption. Explicitly considering negative statements has been shown to improve performance on tasks such as entity summarization and question answering or domain-specific tasks such as protein function prediction. However, no attention has been given to the exploration of negative statements by knowledge graph embedding approaches despite the potential of negative statements to produce more accurate representations of entities in a knowledge graph. We propose a novel approach, TrueWalks, to incorporate negative statements into the knowledge graph representation learning process. In particular, we present a novel walk-generation method that is able to not only differentiate between positive and negative statements but also take into account the semantic implications of negation in ontology-rich knowledge graphs. This is of particular importance for applications in the biomedical domain, where the inadequacy of embedding approaches regarding negative statements at the ontology level has been identified as a crucial limitation. We evaluate TrueWalks in ontology-rich biomedical knowledge graphs in two different predictive tasks based on KG embeddings: protein-protein interaction prediction and gene-disease association prediction. We conduct an extensive analysis over established benchmarks and demonstrate that our method is able to improve the performance of knowledge graph embeddings on all tasks.
Benchmark datasets for biomedical knowledge graphs with negative statements
Jul 21, 2023



Knowledge graphs represent facts about real-world entities. Most of these facts are defined as positive statements. The negative statements are scarce but highly relevant under the open-world assumption. Furthermore, they have been demonstrated to improve the performance of several applications, namely in the biomedical domain. However, no benchmark dataset supports the evaluation of the methods that consider these negative statements. We present a collection of datasets for three relation prediction tasks - protein-protein interaction prediction, gene-disease association prediction and disease prediction - that aim at circumventing the difficulties in building benchmarks for knowledge graphs with negative statements. These datasets include data from two successful biomedical ontologies, Gene Ontology and Human Phenotype Ontology, enriched with negative statements. We also generate knowledge graph embeddings for each dataset with two popular path-based methods and evaluate the performance in each task. The results show that the negative statements can improve the performance of knowledge graph embeddings.
Explainable Representations for Relation Prediction in Knowledge Graphs
Jun 22, 2023Knowledge graphs represent real-world entities and their relations in a semantically-rich structure supported by ontologies. Exploring this data with machine learning methods often relies on knowledge graph embeddings, which produce latent representations of entities that preserve structural and local graph neighbourhood properties, but sacrifice explainability. However, in tasks such as link or relation prediction, understanding which specific features better explain a relation is crucial to support complex or critical applications. We propose SEEK, a novel approach for explainable representations to support relation prediction in knowledge graphs. It is based on identifying relevant shared semantic aspects (i.e., subgraphs) between entities and learning representations for each subgraph, producing a multi-faceted and explainable representation. We evaluate SEEK on two real-world highly complex relation prediction tasks: protein-protein interaction prediction and gene-disease association prediction. Our extensive analysis using established benchmarks demonstrates that SEEK achieves significantly better performance than standard learning representation methods while identifying both sufficient and necessary explanations based on shared semantic aspects.
Predicting Gene-Disease Associations with Knowledge Graph Embeddings over Multiple Ontologies
May 31, 2021
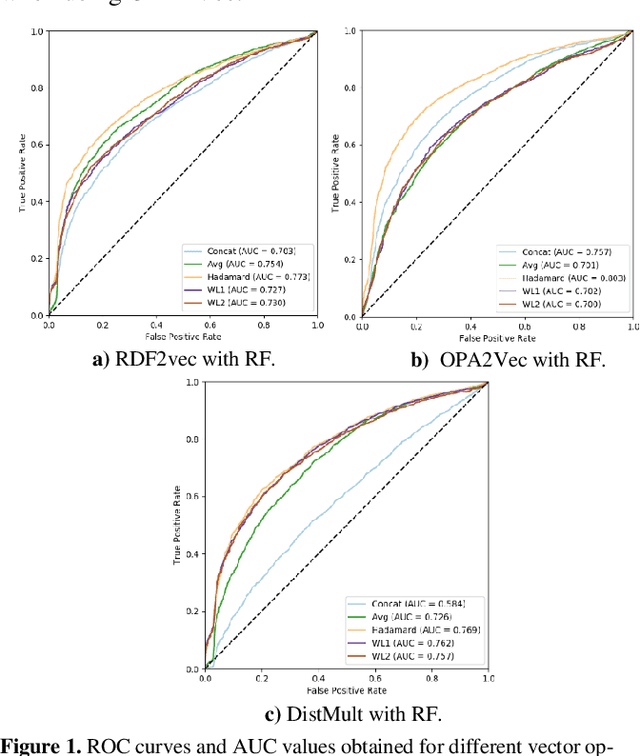
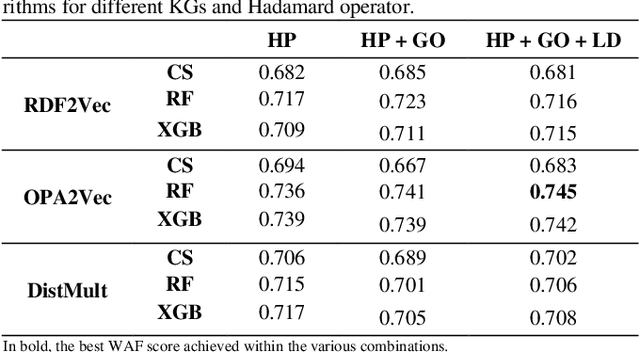
Ontology-based approaches for predicting gene-disease associations include the more classical semantic similarity methods and more recently knowledge graph embeddings. While semantic similarity is typically restricted to hierarchical relations within the ontology, knowledge graph embeddings consider their full breadth. However, embeddings are produced over a single graph and complex tasks such as gene-disease association may require additional ontologies. We investigate the impact of employing richer semantic representations that are based on more than one ontology, able to represent both genes and diseases and consider multiple kinds of relations within the ontologies. Our experiments demonstrate the value of employing knowledge graph embeddings based on random-walks and highlight the need for a closer integration of different ontologies.
Testing the AgreementMaker System in the Anatomy Task of OAEI 2012
Dec 07, 2012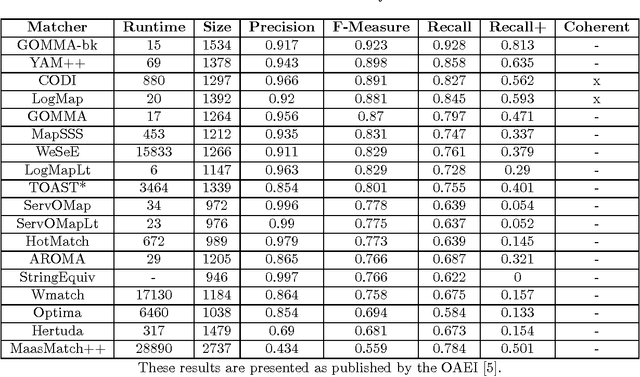
The AgreementMaker system was the leading system in the anatomy task of the Ontology Alignment Evaluation Initiative (OAEI) competition in 2011. While AgreementMaker did not compete in OAEI 2012, here we report on its performance in the 2012 anatomy task, using the same configurations of AgreementMaker submitted to OAEI 2011. Additionally, we also test AgreementMaker using an updated version of the UBERON ontology as a mediating ontology, and otherwise identical configurations. AgreementMaker achieved an F-measure of 91.8% with the 2011 configurations, and an F-measure of 92.2% with the updated UBERON ontology. Thus, AgreementMaker would have been the second best system had it competed in the anatomy task of OAEI 2012, and only 0.1% below the F-measure of the best system.