 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling concept semantics via multilingual averaging in Sparse Autoencoders
Aug 19, 2025Connecting LLMs with formal knowledge representation and reasoning is a promising approach to address their shortcomings. Embeddings and sparse autoencoders are widely used to represent textual content, but the semantics are entangled with syntactic and language-specific information. We propose a method that isolates concept semantics in Large Langue Models by averaging concept activations derived via Sparse Autoencoders. We create English text representations from OWL ontology classes, translate the English into French and Chinese and then pass these texts as prompts to the Gemma 2B LLM. Using the open source Gemma Scope suite of Sparse Autoencoders, we obtain concept activations for each class and language version. We average the different language activations to derive a conceptual average. We then correlate the conceptual averages with a ground truth mapping between ontology classes. Our results give a strong indication that the conceptual average aligns to the true relationship between classes when compared with a single language by itself. The result hints at a new technique which enables mechanistic interpretation of internal network states with higher accuracy.
Large Language Models as Oracles for Ontology Alignment
Aug 11, 2025Ontology alignment plays a crucial role in integrating diverse data sources across domains. There is a large plethora of systems that tackle the ontology alignment problem, yet challenges persist in producing highly quality correspondences among a set of input ontologies. Human-in-the-loop during the alignment process is essential in applications requiring very accurate mappings. User involvement is, however, expensive when dealing with large ontologies. In this paper, we explore the feasibility of using Large Language Models (LLM) as an alternative to the domain expert. The use of the LLM focuses only on the validation of the subset of correspondences where an ontology alignment system is very uncertain. We have conducted an extensive evaluation over several matching tasks of the Ontology Alignment Evaluation Initiative (OAEI), analysing the performance of several state-of-the-art LLMs using different ontology-driven prompt templates. The LLM results are also compared against simulated Oracles with variable error rates.
Survey on Semantic Interpretation of Tabular Data: Challenges and Directions
Nov 07, 2024



Tabular data plays a pivotal role in various fields, making it a popular format for data manipulation and exchange, particularly on the web. The interpretation, extraction, and processing of tabular information are invaluable for knowledge-intensive applications. Notably, significant efforts have been invested in annotating tabular data with ontologies and entities from background knowledge graphs, a process known as Semantic Table Interpretation (STI). STI automation aids in building knowledge graphs, enriching data, and enhancing web-based question answering. This survey aims to provide a comprehensive overview of the STI landscape. It starts by categorizing approaches using a taxonomy of 31 attributes, allowing for comparisons and evaluations. It also examines available tools, assessing them based on 12 criteria. Furthermore, the survey offers an in-depth analysis of the Gold Standards used for evaluating STI approaches. Finally, it provides practical guidance to help end-users choose the most suitable approach for their specific tasks while also discussing unresolved issues and suggesting potential future research directions.
What can knowledge graph alignment gain with Neuro-Symbolic learning approaches?
Oct 11, 2023
Knowledge Graphs (KG) are the backbone of many data-intensive applications since they can represent data coupled with its meaning and context. Aligning KGs across different domains and providers is necessary to afford a fuller and integrated representation. A severe limitation of current KG alignment (KGA) algorithms is that they fail to articulate logical thinking and reasoning with lexical, structural, and semantic data learning. Deep learning models are increasingly popular for KGA inspired by their good performance in other tasks, but they suffer from limitations in explainability, reasoning, and data efficiency. Hybrid neurosymbolic learning models hold the promise of integrating logical and data perspectives to produce high-quality alignments that are explainable and support validation through human-centric approaches. This paper examines the current state of the art in KGA and explores the potential for neurosymbolic integration, highlighting promising research directions for combining these fields.
Understanding Adverse Biological Effect Predictions Using Knowledge Graphs
Oct 28, 2022



Extrapolation of adverse biological (toxic) effects of chemicals is an important contribution to expand available hazard data in (eco)toxicology without the use of animals in laboratory experiments. In this work, we extrapolate effects based on a knowledge graph (KG) consisting of the most relevant effect data as domain-specific background knowledge. An effect prediction model, with and without background knowledge, was used to predict mean adverse biological effect concentration of chemicals as a prototypical type of stressors. The background knowledge improves the model prediction performance by up to 40\% in terms of $R^2$ (\ie coefficient of determination). We use the KG and KG embeddings to provide quantitative and qualitative insights into the predictions. These insights are expected to improve the confidence in effect prediction. Larger scale implementation of such extrapolation models should be expected to support hazard and risk assessment, by simplifying and reducing testing needs.
Contextual Semantic Embeddings for Ontology Subsumption Prediction
Feb 20, 2022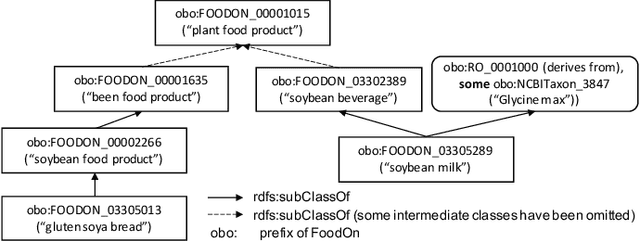
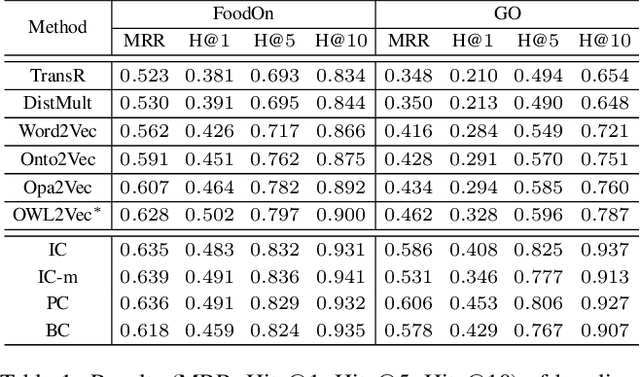
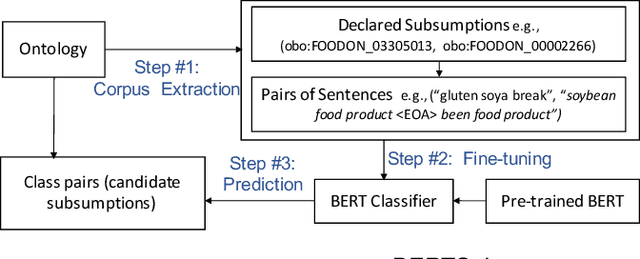
Automating ontology curation is a crucial task in knowledge engineering. Prediction by machine learning techniques such as semantic embedding is a promising direction, but the relevant research is still preliminary. In this paper, we present a class subsumption prediction method named BERTSubs, which uses the pre-trained language model BERT to compute contextual embeddings of the class labels and customized input templates to incorporate contexts of surrounding classes. The evaluation on two large-scale real-world ontologies has shown its better performance than the state-of-the-art.
OWL2Vec*: Embedding of OWL Ontologies
Sep 30, 2020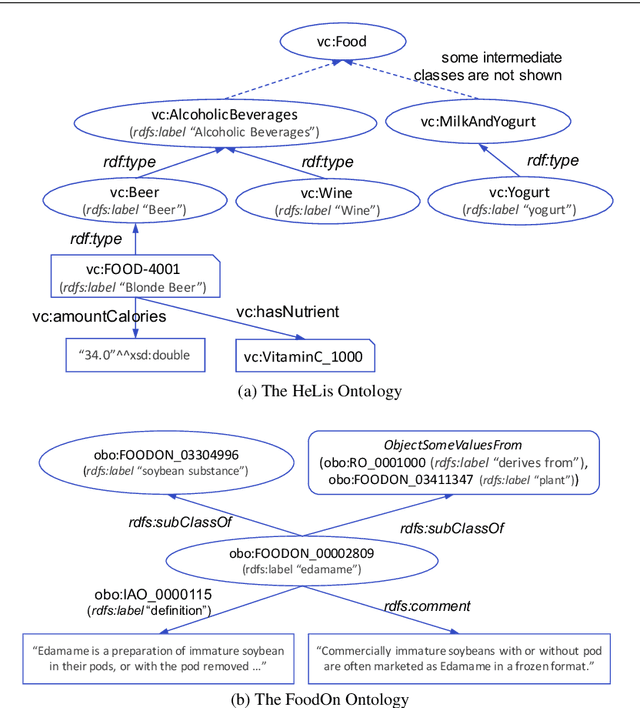

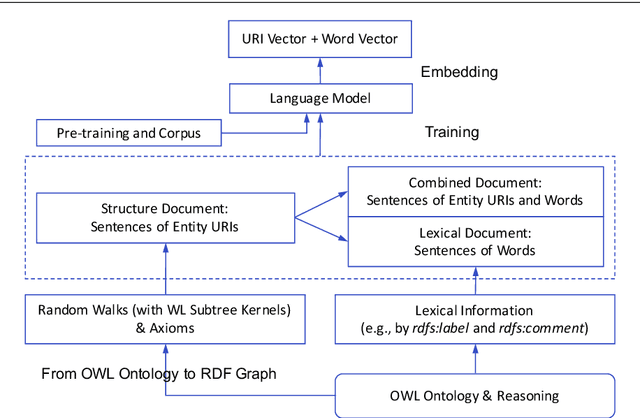

Semantic embedding of knowledge graphs has been widely studied and used for prediction and statistical analysis tasks across various domains such as Natural Language Processing and the Semantic Web. However, less attention has been paid to developing robust methods for embedding OWL (Web Ontology Language) ontologies. In this paper, we propose a language model based ontology embedding method named OWL2Vec*, which encodes the semantics of an ontology by taking into account its graph structure, lexical information and logic constructors. Our empirical evaluation with three real world datasets suggests that OWL2Vec* benefits from these three different aspects of an ontology in class membership prediction and class subsumption prediction tasks. Furthermore, OWL2Vec* often significantly outperforms the state-of-the-art methods in our experiments.
Correcting Knowledge Base Assertions
Jan 19, 2020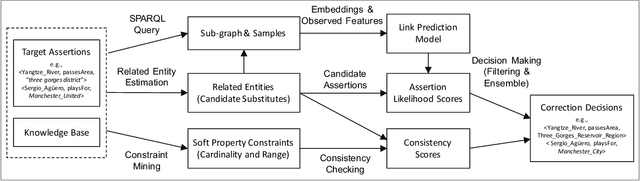


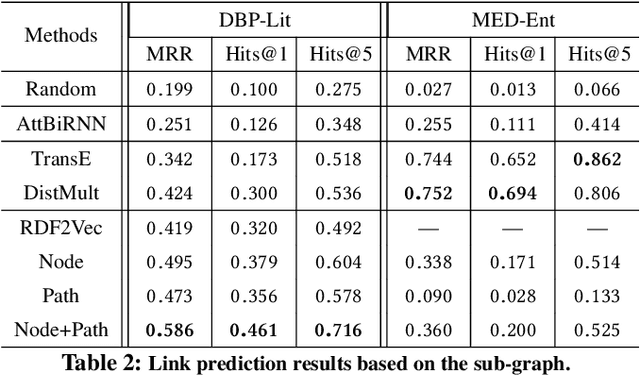
The usefulness and usability of knowledge bases (KBs) is often limited by quality issues. One common issue is the presence of erroneous assertions, often caused by lexical or semantic confusion. We study the problem of correcting such assertions, and present a general correction framework which combines lexical matching, semantic embedding, soft constraint mining and semantic consistency checking. The framework is evaluated using DBpedia and an enterprise medical KB.
Enabling Semantic Data Access for Toxicological Risk Assessment
Sep 11, 2019
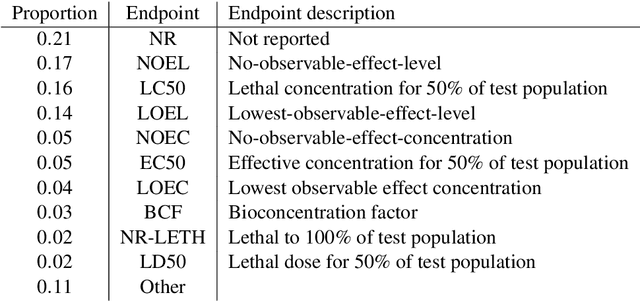


Experimental effort and animal welfare are concerns when exploring the effects a compound has on an organism. Appropriate methods for extrapolating chemical effects can further mitigate these challenges. In this paper we present the efforts to (i) (pre)process and gather data from public and private sources, varying from tabular files to SPARQL endpoints, (ii) integrate the data and represent them as a knowledge graph with richer semantics. This knowledge graph is further applied to facilitate the retrieval of the relevant data for a ecological risk assessment task, extrapolation of effect data, where two prediction techniques are developed.
Knowledge Graph Embedding for Ecotoxicological Effect Prediction
Jul 02, 2019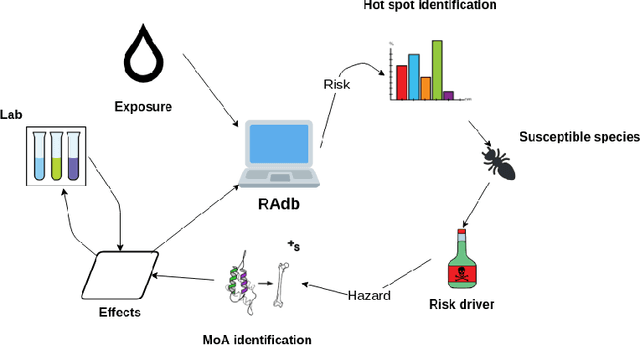
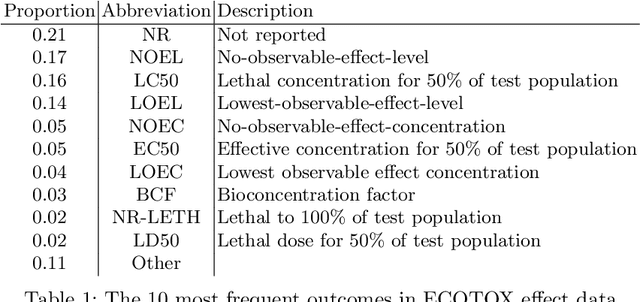


Exploring the effects a chemical compound has on a species takes a considerable experimental effort. Appropriate methods for estimating and suggesting new effects can dramatically reduce the work needed to be done by a laboratory. In this paper we explore the suitability of using a knowledge graph embedding approach for ecotoxicological effect prediction. A knowledge graph has been constructed from publicly available data sets, including a species taxonomy and chemical classification and similarity. The publicly available effect data is integrated to the knowledge graph using ontology alignment techniques. Our experimental results show that the knowledge graph based approach improves the selected baselines.