 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Knowledge Graphs and NLP to Analyze Instant Messaging Data in Criminal Investigations
Sep 30, 2025Criminal investigations often involve the analysis of messages exchanged through instant messaging apps such as WhatsApp, which can be an extremely effort-consuming task. Our approach integrates knowledge graphs and NLP models to support this analysis by semantically enriching data collected from suspects' mobile phones, and help prosecutors and investigators search into the data and get valuable insights. Our semantic enrichment process involves extracting message data and modeling it using a knowledge graph, generating transcriptions of voice messages, and annotating the data using an end-to-end entity extraction approach. We adopt two different solutions to help users get insights into the data, one based on querying and visualizing the graph, and one based on semantic search. The proposed approach ensures that users can verify the information by accessing the original data. While we report about early results and prototypes developed in the context of an ongoing project, our proposal has undergone practical applications with real investigation data. As a consequence, we had the chance to interact closely with prosecutors, collecting positive feedback but also identifying interesting opportunities as well as promising research directions to share with the research community.
ReFactX: Scalable Reasoning with Reliable Facts via Constrained Generation
Aug 23, 2025Knowledge gaps and hallucinations are persistent challenges for Large Language Models (LLMs), which generate unreliable responses when lacking the necessary information to fulfill user instructions. Existing approaches, such as Retrieval-Augmented Generation (RAG) and tool use, aim to address these issues by incorporating external knowledge. Yet, they rely on additional models or services, resulting in complex pipelines, potential error propagation, and often requiring the model to process a large number of tokens. In this paper, we present a scalable method that enables LLMs to access external knowledge without depending on retrievers or auxiliary models. Our approach uses constrained generation with a pre-built prefix-tree index. Triples from a Knowledge Graph are verbalized in textual facts, tokenized, and indexed in a prefix tree for efficient access. During inference, to acquire external knowledge, the LLM generates facts with constrained generation which allows only sequences of tokens that form an existing fact. We evaluate our proposal on Question Answering and show that it scales to large knowledge bases (800 million facts), adapts to domain-specific data, and achieves effective results. These gains come with minimal generation-time overhead. ReFactX code is available at https://github.com/rpo19/ReFactX.
Survey on Semantic Interpretation of Tabular Data: Challenges and Directions
Nov 07, 2024



Tabular data plays a pivotal role in various fields, making it a popular format for data manipulation and exchange, particularly on the web. The interpretation, extraction, and processing of tabular information are invaluable for knowledge-intensive applications. Notably, significant efforts have been invested in annotating tabular data with ontologies and entities from background knowledge graphs, a process known as Semantic Table Interpretation (STI). STI automation aids in building knowledge graphs, enriching data, and enhancing web-based question answering. This survey aims to provide a comprehensive overview of the STI landscape. It starts by categorizing approaches using a taxonomy of 31 attributes, allowing for comparisons and evaluations. It also examines available tools, assessing them based on 12 criteria. Furthermore, the survey offers an in-depth analysis of the Gold Standards used for evaluating STI approaches. Finally, it provides practical guidance to help end-users choose the most suitable approach for their specific tasks while also discussing unresolved issues and suggesting potential future research directions.
Evaluating Language Models on Entity Disambiguation in Tables
Aug 12, 2024



Tables are crucial containers of information, but understanding their meaning may be challenging. Indeed, recently, there has been a focus on Semantic Table Interpretation (STI), i.e., the task that involves the semantic annotation of tabular data to disambiguate their meaning. Over the years, there has been a surge in interest in data-driven approaches based on deep learning that have increasingly been combined with heuristic-based approaches. In the last period, the advent of Large Language Models (LLMs) has led to a new category of approaches for table annotation. The interest in this research field, characterised by multiple challenges, has led to a proliferation of approaches employing different techniques. However, these approaches have not been consistently evaluated on a common ground, making evaluation and comparison difficult. This work proposes an extensive evaluation of four state-of-the-art (SOTA) approaches - Alligator (formerly s-elBat), Dagobah, TURL, and TableLlama; the first two belong to the family of heuristic-based algorithms, while the others are respectively encoder-only and decoder-only LLMs. The primary objective is to measure the ability of these approaches to solve the entity disambiguation task, with the ultimate aim of charting new research paths in the field.
Zero-Shot Hierarchical Classification on the Common Procurement Vocabulary Taxonomy
May 16, 2024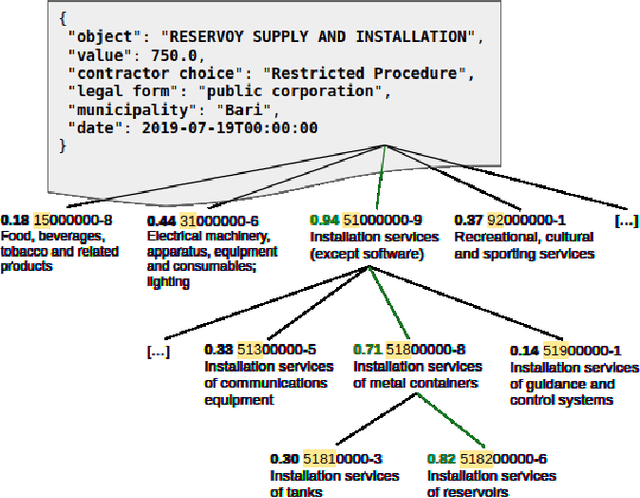



Classifying public tenders is a useful task for both companies that are invited to participate and for inspecting fraudulent activities. To facilitate the task for both participants and public administrations, the European Union presented a common taxonomy (\textit{Common Procurement Vocabulary}, CPV) which is mandatory for tenders of certain importance; however, the contracts in which a CPV label is mandatory are the minority compared to all the Public Administrations activities. Classifying over a real-world taxonomy introduces some difficulties that can not be ignored. First of all, some fine-grained classes have an insufficient (if any) number of observations in the training set, while other classes are far more frequent (even thousands of times) than the average. To overcome those difficulties, we present a zero-shot approach, based on a pre-trained language model that relies only on label description and respects the label taxonomy. To train our proposed model, we used industrial data, which comes from \url{contrattipubblici.org}, a service by \href{https://spaziodati.eu}{SpazioDati s.r.l}. that collects public contracts stipulated in Italy in the last 25 years. Results show that the proposed model achieves better performance in classifying low-frequent classes compared to three different baselines, and is also able to predict never-seen classes.
* Full-length version of the short paper accepted at COMPSAC 2024
SemTUI: a Framework for the Interactive Semantic Enrichment of Tabular Data
Mar 17, 2022
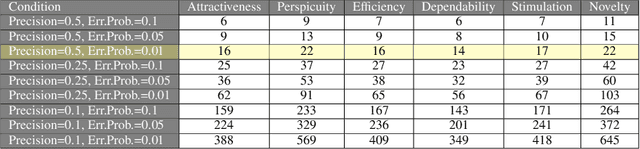
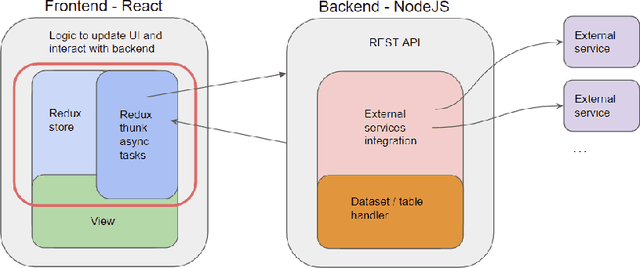

The large availability of datasets fosters the use of \acrshort{ml} and \acrshort{ai} technologies to gather insights, study trends, and predict unseen behaviours out of the world of data. Today, gathering and integrating data from different sources is mainly a manual activity that requires the knowledge of expert users at an high cost in terms of both time and money. It is, therefore, necessary to make the process of gathering and linking data from many different sources affordable to make datasets ready to perform the desired analysis. In this work, we propose the development of a comprehensive framework, named SemTUI, to make the enrichment process flexible, complete, and effective through the use of semantics. The approach is to promote fast integration of external services to perform enrichment tasks such as reconciliation and extension; and to provide users with a graphical interface to support additional tasks, such as refinement to correct ambiguous results provided by automatic enrichment algorithms. A task-driven user evaluation proved SemTUI to be understandable, usable, and capable of achieving table enrichment with little effort and time with user tests that involved people with different skills and experiences.
On the Impact of Temporal Representations on Metaphor Detection
Nov 05, 2021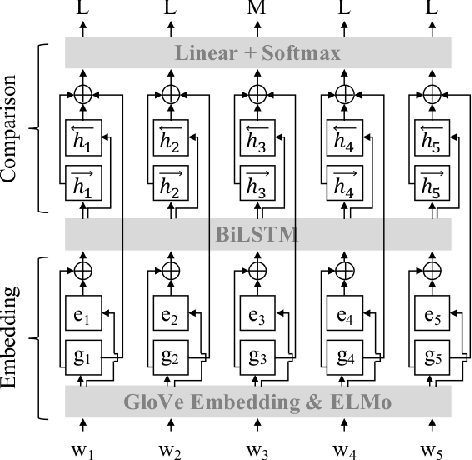
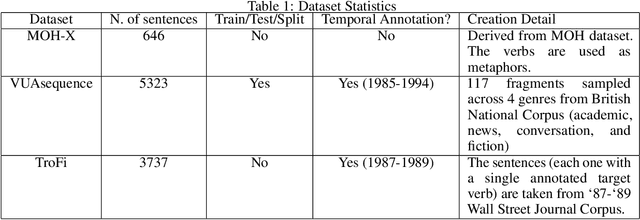

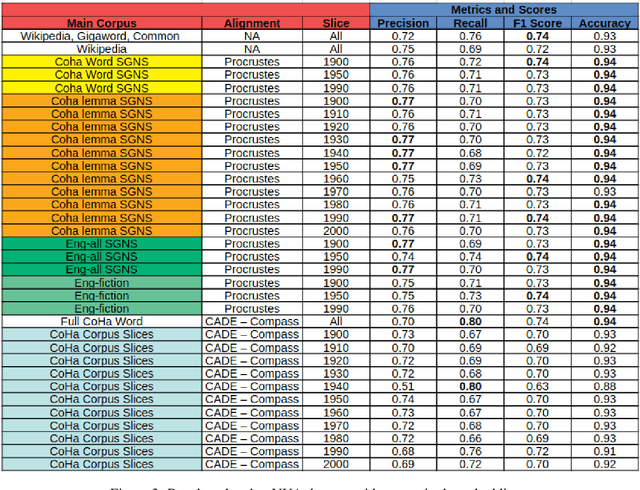
State-of-the-art approaches for metaphor detection compare their literal - or core - meaning and their contextual meaning using sequential metaphor classifiers based on neural networks. The signal that represents the literal meaning is often represented by (non-contextual) word embeddings. However, metaphorical expressions evolve over time due to various reasons, such as cultural and societal impact. Metaphorical expressions are known to co-evolve with language and literal word meanings, and even drive, to some extent, this evolution. This rises the question whether different, possibly time-specific, representations of literal meanings may impact on the metaphor detection task. To the best of our knowledge, this is the first study which examines the metaphor detection task with a detailed exploratory analysis where different temporal and static word embeddings are used to account for different representations of literal meanings. Our experimental analysis is based on three popular benchmarks used for metaphor detection and word embeddings extracted from different corpora and temporally aligned to different state-of-the-art approaches. The results suggest that different word embeddings do impact on the metaphor detection task and some temporal word embeddings slightly outperform static methods on some performance measures. However, results also suggest that temporal word embeddings may provide representations of words' core meaning even too close to their metaphorical meaning, thus confusing the classifier. Overall, the interaction between temporal language evolution and metaphor detection appears tiny in the benchmark datasets used in our experiments. This suggests that future work for the computational analysis of this important linguistic phenomenon should first start by creating a new dataset where this interaction is better represented.
SWEAT: Scoring Polarization of Topics across Different Corpora
Sep 15, 2021
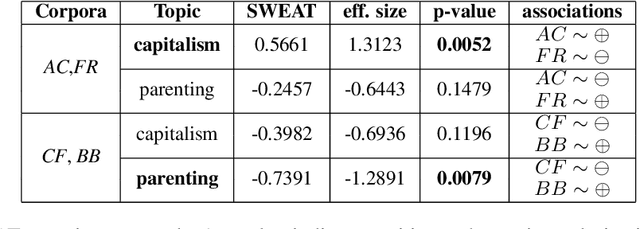

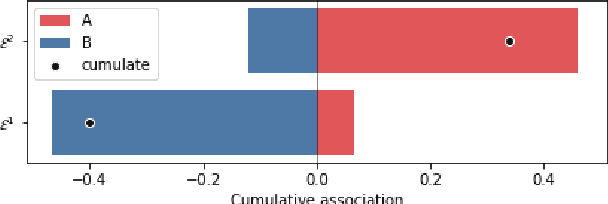
Understanding differences of viewpoints across corpora is a fundamental task for computational social sciences. In this paper, we propose the Sliced Word Embedding Association Test (SWEAT), a novel statistical measure to compute the relative polarization of a topical wordset across two distributional representations. To this end, SWEAT uses two additional wordsets, deemed to have opposite valence, to represent two different poles. We validate our approach and illustrate a case study to show the usefulness of the introduced measure.
Knowledge Graph Embeddings and Explainable AI
Apr 30, 2020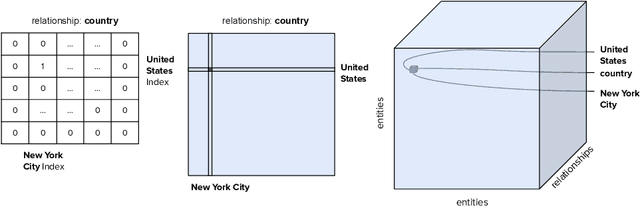

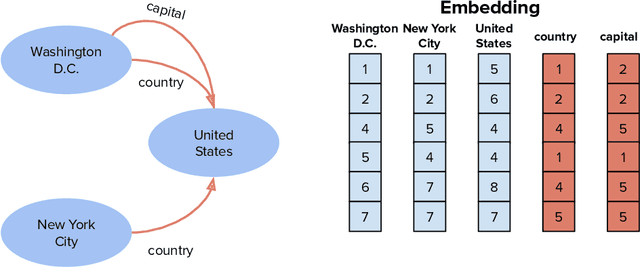

Knowledge graph embeddings are now a widely adopted approach to knowledge representation in which entities and relationships are embedded in vector spaces. In this chapter, we introduce the reader to the concept of knowledge graph embeddings by explaining what they are, how they can be generated and how they can be evaluated. We summarize the state-of-the-art in this field by describing the approaches that have been introduced to represent knowledge in the vector space. In relation to knowledge representation, we consider the problem of explainability, and discuss models and methods for explaining predictions obtained via knowledge graph embeddings.
Compass-aligned Distributional Embeddings for Studying Semantic Differences across Corpora
Apr 13, 2020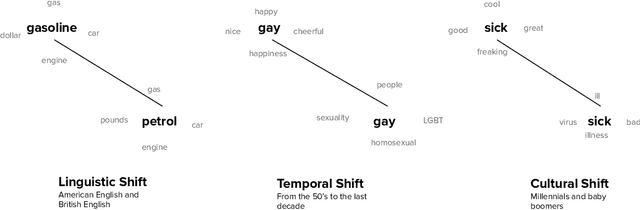
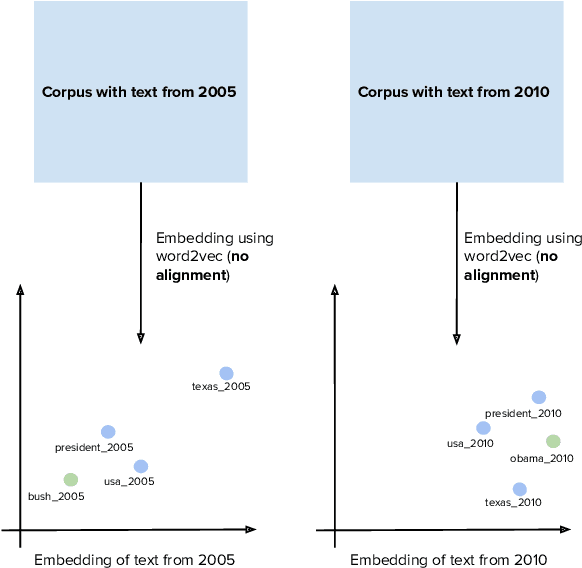
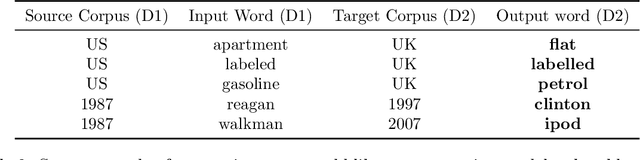
Word2vec is one of the most used algorithms to generate word embeddings because of a good mix of efficiency, quality of the generated representations and cognitive grounding. However, word meaning is not static and depends on the context in which words are used. Differences in word meaning that depends on time, location, topic, and other factors, can be studied by analyzing embeddings generated from different corpora in collections that are representative of these factors. For example, language evolution can be studied using a collection of news articles published in different time periods. In this paper, we present a general framework to support cross-corpora language studies with word embeddings, where embeddings generated from different corpora can be compared to find correspondences and differences in meaning across the corpora. CADE is the core component of our framework and solves the key problem of aligning the embeddings generated from different corpora. In particular, we focus on providing solid evidence about the effectiveness, generality, and robustness of CADE. To this end, we conduct quantitative and qualitative experiments in different domains, from temporal word embeddings to language localization and topical analysis. The results of our experiments suggest that CADE achieves state-of-the-art or superior performance on tasks where several competing approaches are available, yet providing a general method that can be used in a variety of domains. Finally, our experiments shed light on the conditions under which the alignment is reliable, which substantially depends on the degree of cross-corpora vocabulary overlap.