 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow should the advent of large language models affect the practice of science?
Dec 05, 2023Large language models (LLMs) are being increasingly incorporated into scientific workflows. However, we have yet to fully grasp the implications of this integration. How should the advent of large language models affect the practice of science? For this opinion piece, we have invited four diverse groups of scientists to reflect on this query, sharing their perspectives and engaging in debate. Schulz et al. make the argument that working with LLMs is not fundamentally different from working with human collaborators, while Bender et al. argue that LLMs are often misused and over-hyped, and that their limitations warrant a focus on more specialized, easily interpretable tools. Marelli et al. emphasize the importance of transparent attribution and responsible use of LLMs. Finally, Botvinick and Gershman advocate that humans should retain responsibility for determining the scientific roadmap. To facilitate the discussion, the four perspectives are complemented with a response from each group. By putting these different perspectives in conversation, we aim to bring attention to important considerations within the academic community regarding the adoption of LLMs and their impact on both current and future scientific practices.
The challenge of representation learning: Improved accuracy in deep vision models does not come with better predictions of perceptual similarity
Mar 13, 2023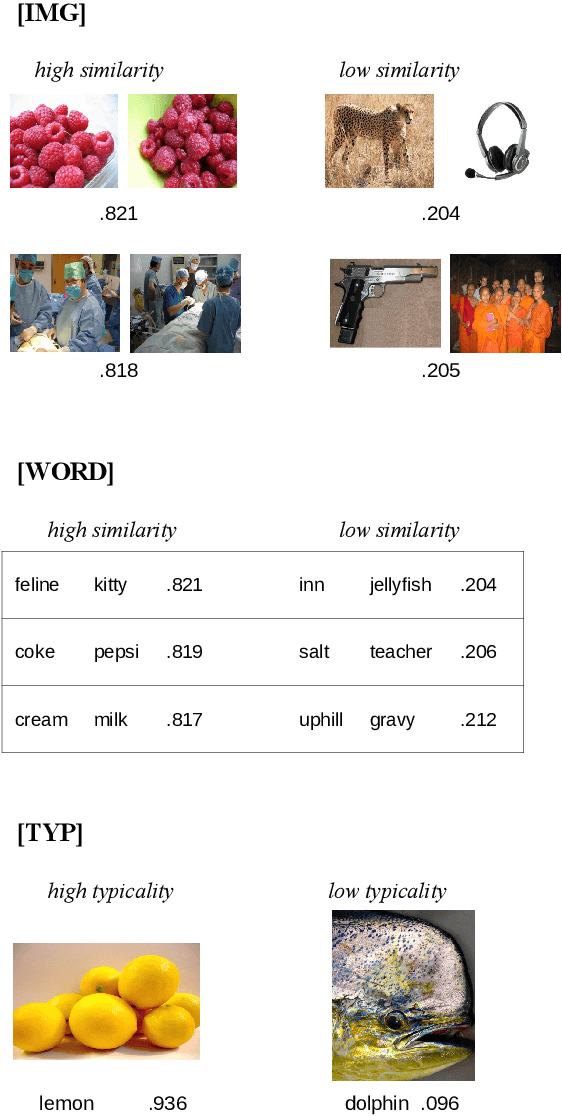
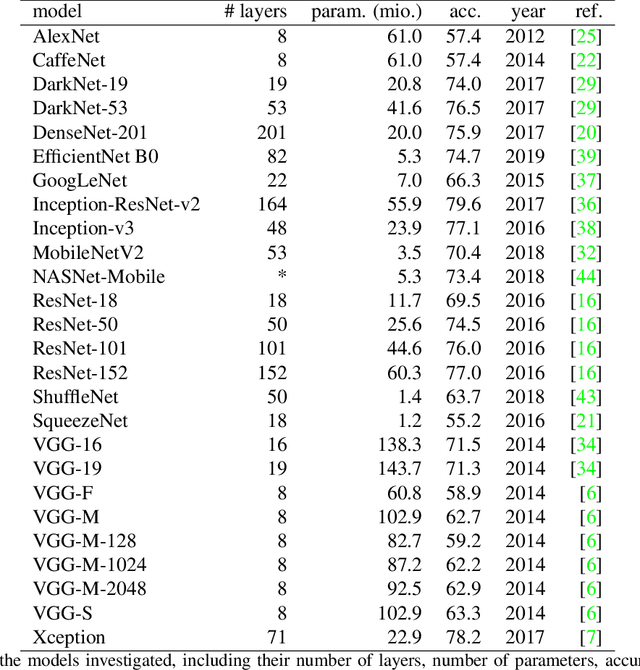
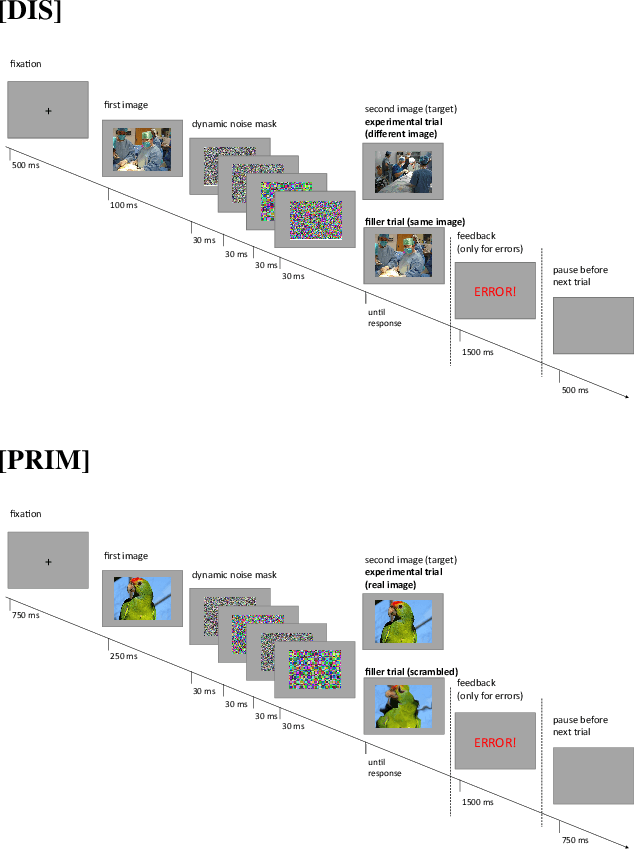
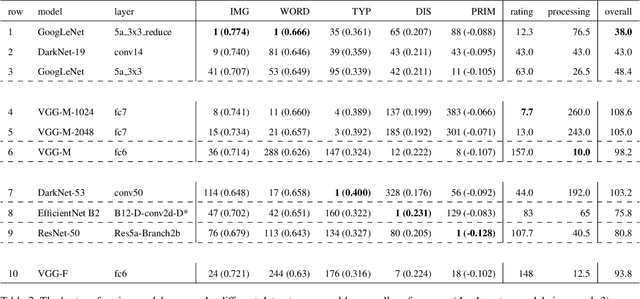
Over the last years, advancements in deep learning models for computer vision have led to a dramatic improvement in their image classification accuracy. However, models with a higher accuracy in the task they were trained on do not necessarily develop better image representations that allow them to also perform better in other tasks they were not trained on. In order to investigate the representation learning capabilities of prominent high-performing computer vision models, we investigated how well they capture various indices of perceptual similarity from large-scale behavioral datasets. We find that higher image classification accuracy rates are not associated with a better performance on these datasets, and in fact we observe no improvement in performance since GoogLeNet (released 2015) and VGG-M (released 2014). We speculate that more accurate classification may result from hyper-engineering towards very fine-grained distinctions between highly similar classes, which does not incentivize the models to capture overall perceptual similarities.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
SWEAT: Scoring Polarization of Topics across Different Corpora
Sep 15, 2021
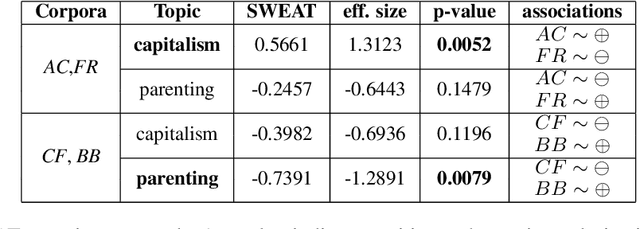

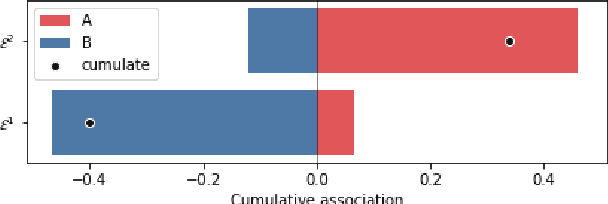
Understanding differences of viewpoints across corpora is a fundamental task for computational social sciences. In this paper, we propose the Sliced Word Embedding Association Test (SWEAT), a novel statistical measure to compute the relative polarization of a topical wordset across two distributional representations. To this end, SWEAT uses two additional wordsets, deemed to have opposite valence, to represent two different poles. We validate our approach and illustrate a case study to show the usefulness of the introduced measure.
Exploring Processing of Nested Dependencies in Neural-Network Language Models and Humans
Jun 19, 2020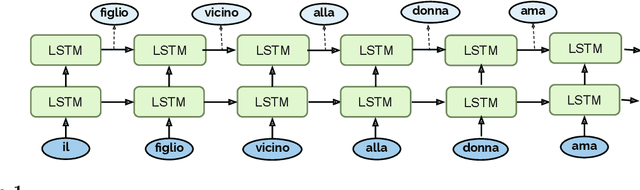

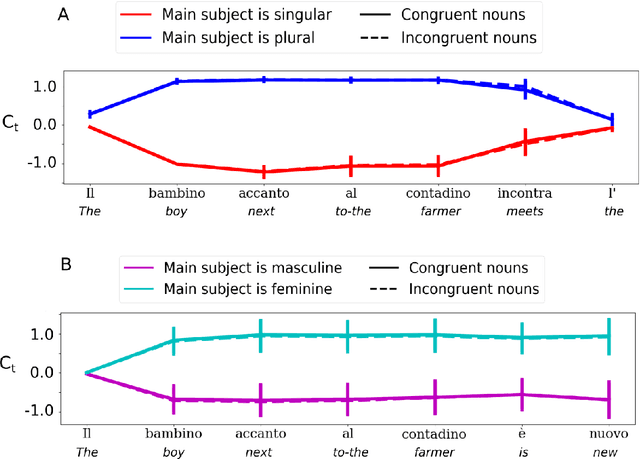

Recursive processing in sentence comprehension is considered a hallmark of human linguistic abilities. However, its underlying neural mechanisms remain largely unknown. We studied whether a recurrent neural network with Long Short-Term Memory units can mimic a central aspect of human sentence processing, namely the handling of long-distance agreement dependencies. Although the network was solely trained to predict the next word in a large corpus, analysis showed the emergence of a small set of specialized units that successfully handled local and long-distance syntactic agreement for grammatical number. However, simulations showed that this mechanism does not support full recursion and fails with some long-range embedded dependencies. We tested the model's predictions in a behavioral experiment where humans detected violations in number agreement in sentences with systematic variations in the singular/plural status of multiple nouns, with or without embedding. Human and model error patterns were remarkably similar, showing that the model echoes various effects observed in human data. However, a key difference was that, with embedded long-range dependencies, humans remained above chance level, while the model's systematic errors brought it below chance. Overall, our study shows that exploring the ways in which modern artificial neural networks process sentences leads to precise and testable hypotheses about human linguistic performance.
Be Precise or Fuzzy: Learning the Meaning of Cardinals and Quantifiers from Vision
Feb 17, 2017
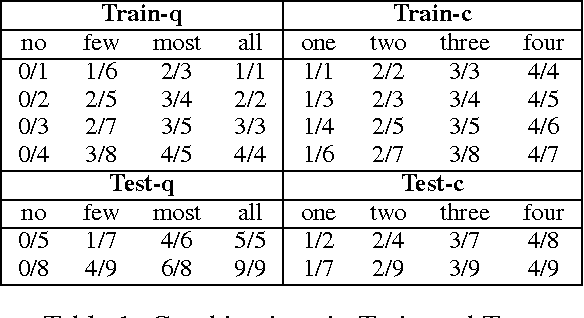
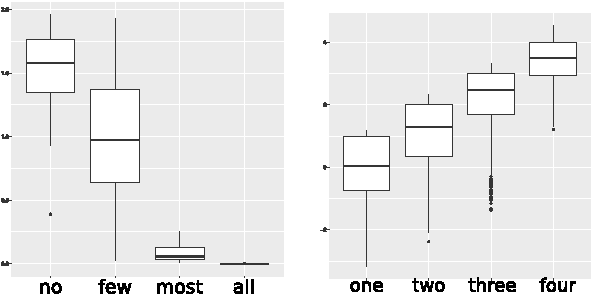
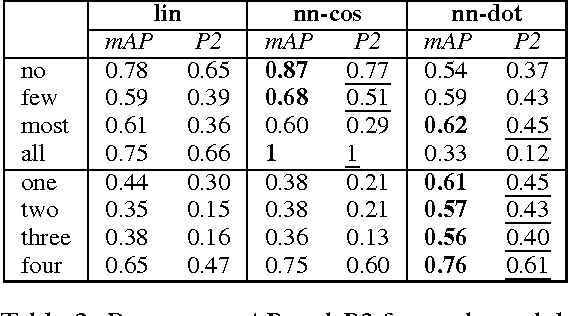
People can refer to quantities in a visual scene by using either exact cardinals (e.g. one, two, three) or natural language quantifiers (e.g. few, most, all). In humans, these two processes underlie fairly different cognitive and neural mechanisms. Inspired by this evidence, the present study proposes two models for learning the objective meaning of cardinals and quantifiers from visual scenes containing multiple objects. We show that a model capitalizing on a 'fuzzy' measure of similarity is effective for learning quantifiers, whereas the learning of exact cardinals is better accomplished when information about number is provided.