Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBe Precise or Fuzzy: Learning the Meaning of Cardinals and Quantifiers from Vision
Paper and Code
Feb 17, 2017
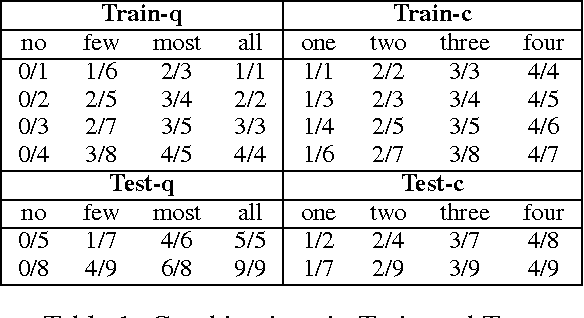
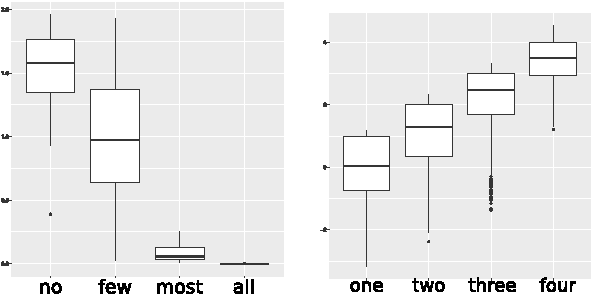
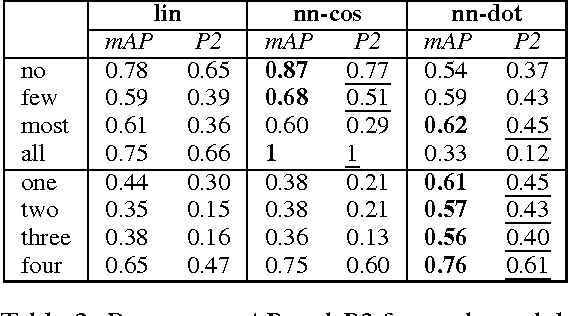
People can refer to quantities in a visual scene by using either exact cardinals (e.g. one, two, three) or natural language quantifiers (e.g. few, most, all). In humans, these two processes underlie fairly different cognitive and neural mechanisms. Inspired by this evidence, the present study proposes two models for learning the objective meaning of cardinals and quantifiers from visual scenes containing multiple objects. We show that a model capitalizing on a 'fuzzy' measure of similarity is effective for learning quantifiers, whereas the learning of exact cardinals is better accomplished when information about number is provided.
* Accepted at EACL2017. 7 pages
View paper on