 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompass-aligned Distributional Embeddings for Studying Semantic Differences across Corpora
Apr 13, 2020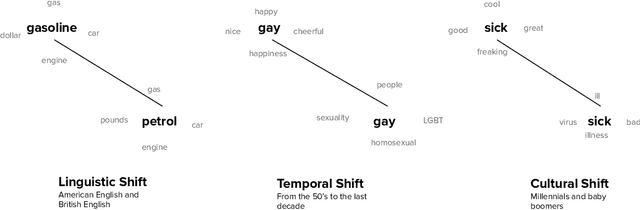
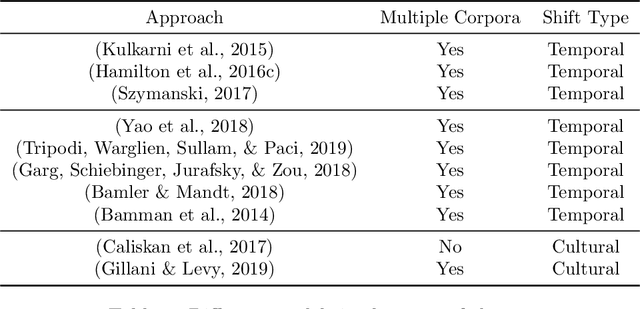
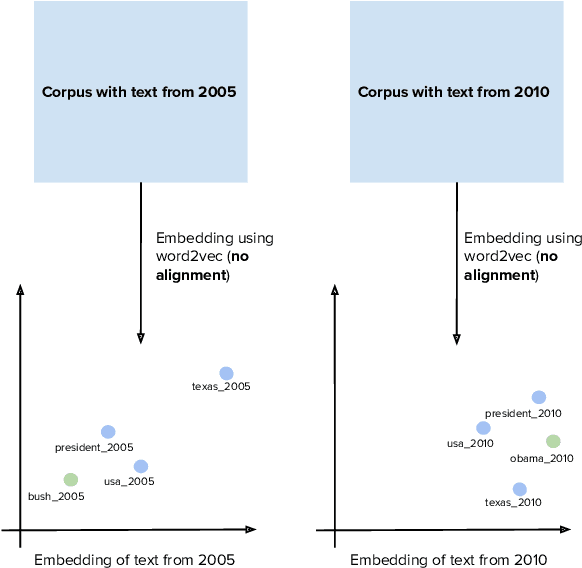
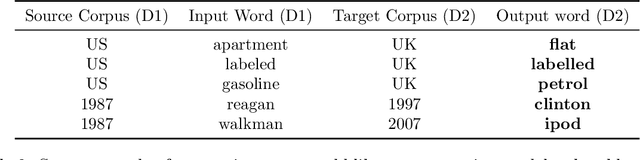
Word2vec is one of the most used algorithms to generate word embeddings because of a good mix of efficiency, quality of the generated representations and cognitive grounding. However, word meaning is not static and depends on the context in which words are used. Differences in word meaning that depends on time, location, topic, and other factors, can be studied by analyzing embeddings generated from different corpora in collections that are representative of these factors. For example, language evolution can be studied using a collection of news articles published in different time periods. In this paper, we present a general framework to support cross-corpora language studies with word embeddings, where embeddings generated from different corpora can be compared to find correspondences and differences in meaning across the corpora. CADE is the core component of our framework and solves the key problem of aligning the embeddings generated from different corpora. In particular, we focus on providing solid evidence about the effectiveness, generality, and robustness of CADE. To this end, we conduct quantitative and qualitative experiments in different domains, from temporal word embeddings to language localization and topical analysis. The results of our experiments suggest that CADE achieves state-of-the-art or superior performance on tasks where several competing approaches are available, yet providing a general method that can be used in a variety of domains. Finally, our experiments shed light on the conditions under which the alignment is reliable, which substantially depends on the degree of cross-corpora vocabulary overlap.
Training Temporal Word Embeddings with a Compass
Jun 05, 2019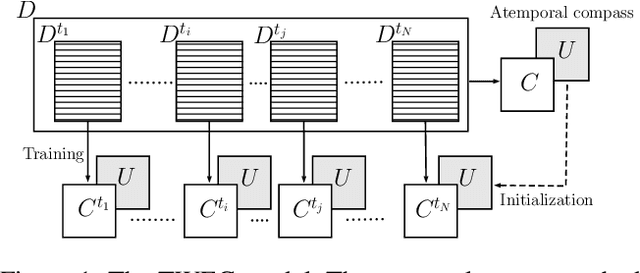
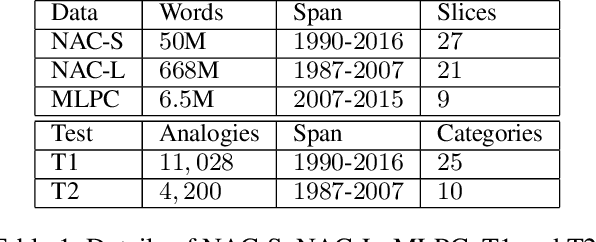
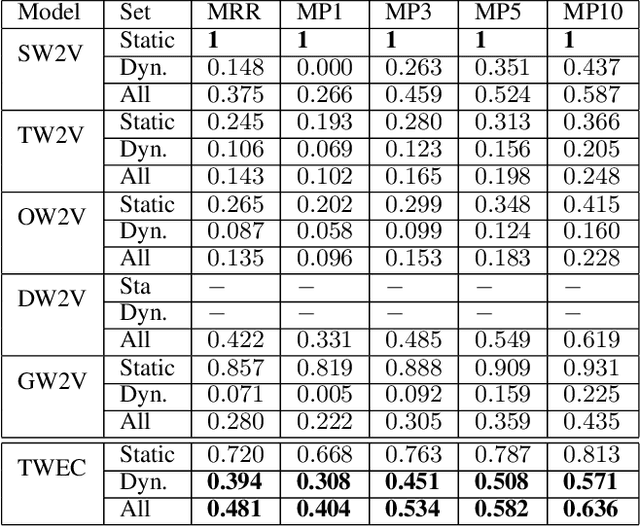
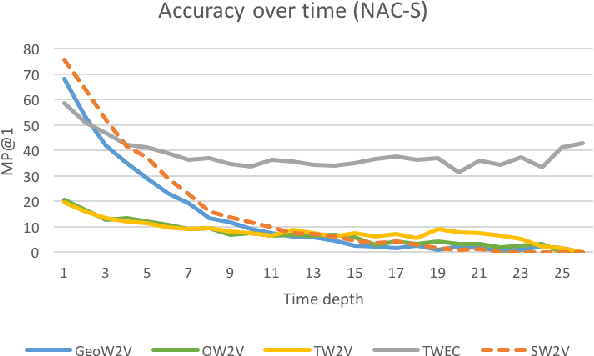
Temporal word embeddings have been proposed to support the analysis of word meaning shifts during time and to study the evolution of languages. Different approaches have been proposed to generate vector representations of words that embed their meaning during a specific time interval. However, the training process used in these approaches is complex, may be inefficient or it may require large text corpora. As a consequence, these approaches may be difficult to apply in resource-scarce domains or by scientists with limited in-depth knowledge of embedding models. In this paper, we propose a new heuristic to train temporal word embeddings based on the Word2vec model. The heuristic consists in using atemporal vectors as a reference, i.e., as a compass, when training the representations specific to a given time interval. The use of the compass simplifies the training process and makes it more efficient. Experiments conducted using state-of-the-art datasets and methodologies suggest that our approach outperforms or equals comparable approaches while being more robust in terms of the required corpus size.