 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid X-Linker: Automated Data Generation and Extreme Multi-label Ranking for Biomedical Entity Linking
Jul 08, 2024State-of-the-art deep learning entity linking methods rely on extensive human-labelled data, which is costly to acquire. Current datasets are limited in size, leading to inadequate coverage of biomedical concepts and diminished performance when applied to new data. In this work, we propose to automatically generate data to create large-scale training datasets, which allows the exploration of approaches originally developed for the task of extreme multi-label ranking in the biomedical entity linking task. We propose the hybrid X-Linker pipeline that includes different modules to link disease and chemical entity mentions to concepts in the MEDIC and the CTD-Chemical vocabularies, respectively. X-Linker was evaluated on several biomedical datasets: BC5CDR-Disease, BioRED-Disease, NCBI-Disease, BC5CDR-Chemical, BioRED-Chemical, and NLM-Chem, achieving top-1 accuracies of 0.8307, 0.7969, 0.8271, 0.9511, 0.9248, and 0.7895, respectively. X-Linker demonstrated superior performance in three datasets: BC5CDR-Disease, NCBI-Disease, and BioRED-Chemical. In contrast, SapBERT outperformed X-Linker in the remaining three datasets. Both models rely only on the mention string for their operations. The source code of X-Linker and its associated data are publicly available for performing biomedical entity linking without requiring pre-labelled entities with identifiers from specific knowledge organization systems.
LASIGE and UNICAGE solution to the NASA LitCoin NLP Competition
Aug 10, 2023Biomedical Natural Language Processing (NLP) tends to become cumbersome for most researchers, frequently due to the amount and heterogeneity of text to be processed. To address this challenge, the industry is continuously developing highly efficient tools and creating more flexible engineering solutions. This work presents the integration between industry data engineering solutions for efficient data processing and academic systems developed for Named Entity Recognition (LasigeUnicage\_NER) and Relation Extraction (BiOnt). Our design reflects an integration of those components with external knowledge in the form of additional training data from other datasets and biomedical ontologies. We used this pipeline in the 2022 LitCoin NLP Challenge, where our team LasigeUnicage was awarded the 7th Prize out of approximately 200 participating teams, reflecting a successful collaboration between the academia (LASIGE) and the industry (Unicage). The software supporting this work is available at \url{https://github.com/lasigeBioTM/Litcoin-Lasige_Unicage}.
Using Neural Networks for Relation Extraction from Biomedical Literature
May 27, 2019

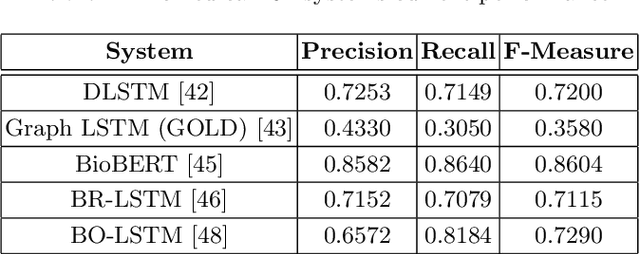
Using different sources of information to support automated extracting of relations between biomedical concepts contributes to the development of our understanding of biological systems. The primary comprehensive source of these relations is biomedical literature. Several relation extraction approaches have been proposed to identify relations between concepts in biomedical literature, namely using neural networks algorithms. The use of multichannel architectures composed of multiple data representations, as in deep neural networks, is leading to state-of-the-art results. The right combination of data representations can eventually lead us to even higher evaluation scores in relation extraction tasks. Thus, biomedical ontologies play a fundamental role by providing semantic and ancestry information about an entity. The incorporation of biomedical ontologies has already been proved to enhance previous state-of-the-art results.
A Silver Standard Corpus of Human Phenotype-Gene Relations
Mar 26, 2019


Human phenotype-gene relations are fundamental to fully understand the origin of some phenotypic abnormalities and their associated diseases. Biomedical literature is the most comprehensive source of these relations, however, we need Relation Extraction tools to automatically recognize them. Most of these tools require an annotated corpus and to the best of our knowledge, there is no corpus available annotated with human phenotype-gene relations. This paper presents the Phenotype-Gene Relations (PGR) corpus, a silver standard corpus of human phenotype and gene annotations and their relations. The corpus consists of 1712 abstracts, 5676 human phenotype annotations, 13835 gene annotations, and 4283 relations. We generated this corpus using Named-Entity Recognition tools, whose results were partially evaluated by eight curators, obtaining a precision of 87.01%. By using the corpus we were able to obtain promising results with two state-of-the-art deep learning tools, namely 78.05% of precision. The PGR corpus was made publicly available to the research community.
WS4A: a Biomedical Question and Answering System based on public Web Services and Ontologies
Nov 17, 2016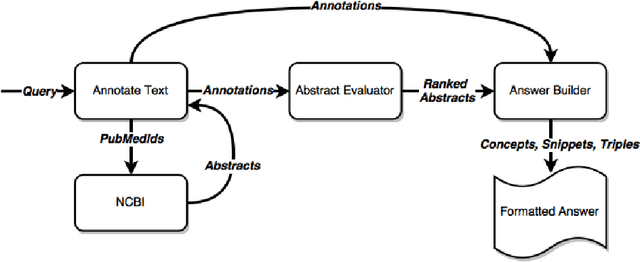
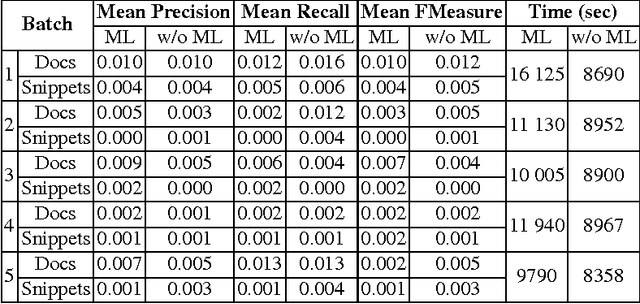
This paper describes our system, dubbed WS4A (Web Services for All), that participated in the fourth edition of the BioASQ challenge (2016). We used WS4A to perform the Question and Answering (QA) task 4b, which consisted on the retrieval of relevant concepts, documents, snippets, RDF triples, exact answers and ideal answers for each given question. The novelty in our approach consists on the maximum exploitation of existing web services in each step of WS4A, such as the annotation of text, and the retrieval of metadata for each annotation. The information retrieved included concept identifiers, ontologies, ancestors, and most importantly, PubMed identifiers. The paper describes the WS4A pipeline and also presents the precision, recall and f-measure values obtained in task 4b. Our system achieved two second places in two subtasks on one of the five batches.
Testing the AgreementMaker System in the Anatomy Task of OAEI 2012
Dec 07, 2012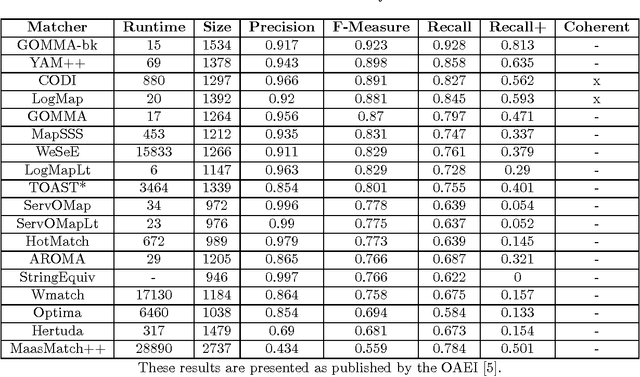
The AgreementMaker system was the leading system in the anatomy task of the Ontology Alignment Evaluation Initiative (OAEI) competition in 2011. While AgreementMaker did not compete in OAEI 2012, here we report on its performance in the 2012 anatomy task, using the same configurations of AgreementMaker submitted to OAEI 2011. Additionally, we also test AgreementMaker using an updated version of the UBERON ontology as a mediating ontology, and otherwise identical configurations. AgreementMaker achieved an F-measure of 91.8% with the 2011 configurations, and an F-measure of 92.2% with the updated UBERON ontology. Thus, AgreementMaker would have been the second best system had it competed in the anatomy task of OAEI 2012, and only 0.1% below the F-measure of the best system.