 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Neural Networks for Relation Extraction from Biomedical Literature
May 27, 2019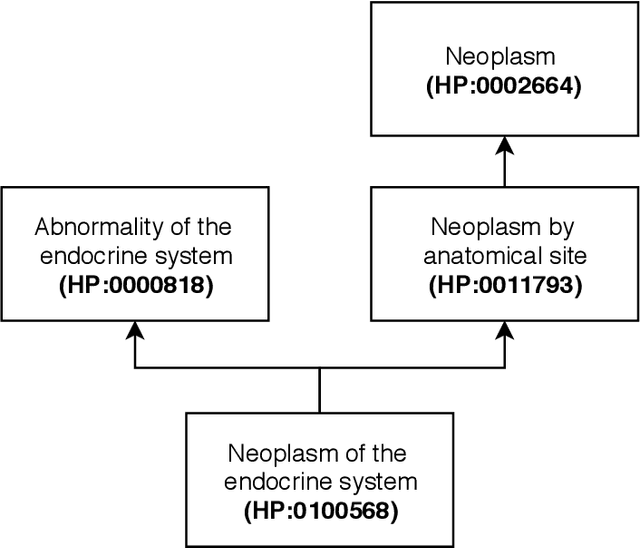
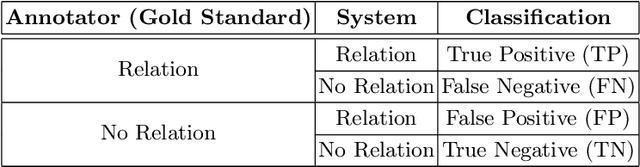

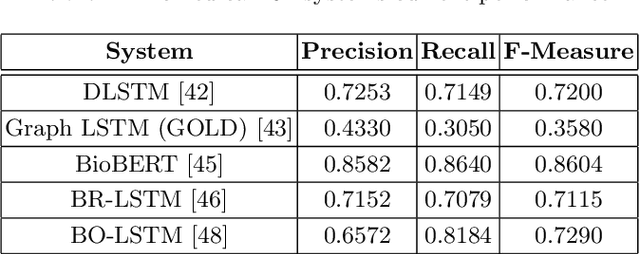
Using different sources of information to support automated extracting of relations between biomedical concepts contributes to the development of our understanding of biological systems. The primary comprehensive source of these relations is biomedical literature. Several relation extraction approaches have been proposed to identify relations between concepts in biomedical literature, namely using neural networks algorithms. The use of multichannel architectures composed of multiple data representations, as in deep neural networks, is leading to state-of-the-art results. The right combination of data representations can eventually lead us to even higher evaluation scores in relation extraction tasks. Thus, biomedical ontologies play a fundamental role by providing semantic and ancestry information about an entity. The incorporation of biomedical ontologies has already been proved to enhance previous state-of-the-art results.
A Silver Standard Corpus of Human Phenotype-Gene Relations
Mar 26, 2019


Human phenotype-gene relations are fundamental to fully understand the origin of some phenotypic abnormalities and their associated diseases. Biomedical literature is the most comprehensive source of these relations, however, we need Relation Extraction tools to automatically recognize them. Most of these tools require an annotated corpus and to the best of our knowledge, there is no corpus available annotated with human phenotype-gene relations. This paper presents the Phenotype-Gene Relations (PGR) corpus, a silver standard corpus of human phenotype and gene annotations and their relations. The corpus consists of 1712 abstracts, 5676 human phenotype annotations, 13835 gene annotations, and 4283 relations. We generated this corpus using Named-Entity Recognition tools, whose results were partially evaluated by eight curators, obtaining a precision of 87.01%. By using the corpus we were able to obtain promising results with two state-of-the-art deep learning tools, namely 78.05% of precision. The PGR corpus was made publicly available to the research community.