 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOAST: Fast and scalable auto-partitioning based on principled static analysis
Aug 20, 2025Partitioning large machine learning models across distributed accelerator systems is a complex process, requiring a series of interdependent decisions that are further complicated by internal sharding ambiguities. Consequently, existing auto-partitioners often suffer from out-of-memory errors or are prohibitively slow when exploring the exponentially large space of possible partitionings. To mitigate this, they artificially restrict the search space, but this approach frequently yields infeasible solutions that violate device memory constraints or lead to sub-optimal performance. We propose a system that combines a novel static compiler analysis with a Monte Carlo Tree Search. Our analysis constructs an efficient decision space by identifying (i) tensor dimensions requiring identical sharding, and (ii) partitioning "conflicts" that require resolution. Our system significantly outperforms state-of-the-art industrial methods across diverse hardware platforms and model architectures, discovering previously unknown, superior solutions, and the process is fully automated even for complex and large models.
Automap: Towards Ergonomic Automated Parallelism for ML Models
Dec 06, 2021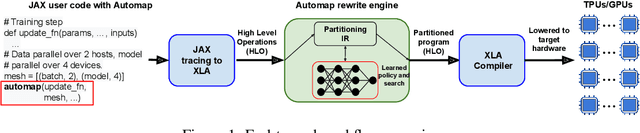
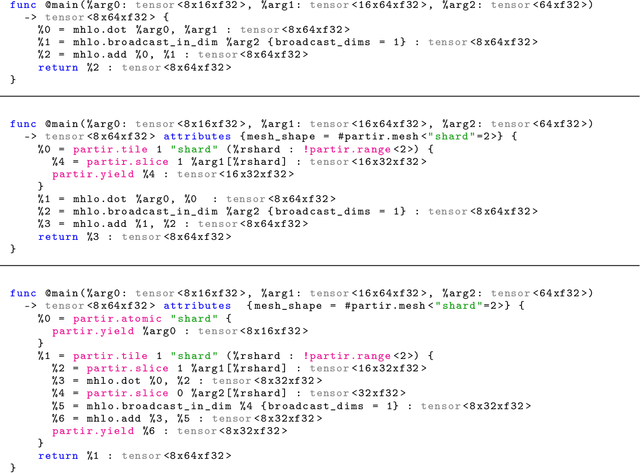


The rapid rise in demand for training large neural network architectures has brought into focus the need for partitioning strategies, for example by using data, model, or pipeline parallelism. Implementing these methods is increasingly supported through program primitives, but identifying efficient partitioning strategies requires expensive experimentation and expertise. We present the prototype of an automated partitioner that seamlessly integrates into existing compilers and existing user workflows. Our partitioner enables SPMD-style parallelism that encompasses data parallelism and parameter/activation sharding. Through a combination of inductive tactics and search in a platform-independent partitioning IR, automap can recover expert partitioning strategies such as Megatron sharding for transformer layers.