 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Training Compute-Optimal Large Language Models
Mar 29, 2022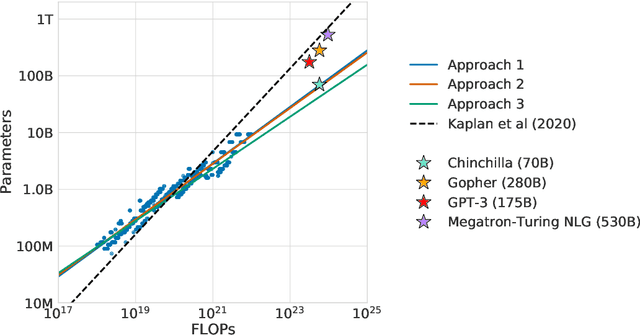
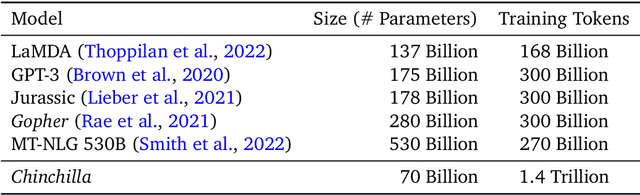
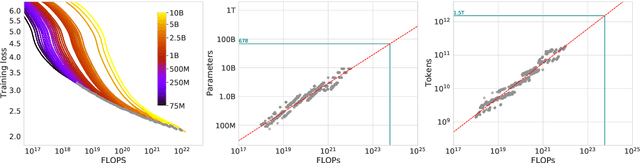

We investigate the optimal model size and number of tokens for training a transformer language model under a given compute budget. We find that current large language models are significantly undertrained, a consequence of the recent focus on scaling language models whilst keeping the amount of training data constant. By training over \nummodels language models ranging from 70 million to over 16 billion parameters on 5 to 500 billion tokens, we find that for compute-optimal training, the model size and the number of training tokens should be scaled equally: for every doubling of model size the number of training tokens should also be doubled. We test this hypothesis by training a predicted compute-optimal model, \chinchilla, that uses the same compute budget as \gopher but with 70B parameters and 4$\times$ more more data. \chinchilla uniformly and significantly outperforms \Gopher (280B), GPT-3 (175B), Jurassic-1 (178B), and Megatron-Turing NLG (530B) on a large range of downstream evaluation tasks. This also means that \chinchilla uses substantially less compute for fine-tuning and inference, greatly facilitating downstream usage. As a highlight, \chinchilla reaches a state-of-the-art average accuracy of 67.5\% on the MMLU benchmark, greater than a 7\% improvement over \gopher.
Improving language models by retrieving from trillions of tokens
Jan 11, 2022



We enhance auto-regressive language models by conditioning on document chunks retrieved from a large corpus, based on local similarity with preceding tokens. With a $2$ trillion token database, our Retrieval-Enhanced Transformer (RETRO) obtains comparable performance to GPT-3 and Jurassic-1 on the Pile, despite using 25$\times$ fewer parameters. After fine-tuning, RETRO performance translates to downstream knowledge-intensive tasks such as question answering. RETRO combines a frozen Bert retriever, a differentiable encoder and a chunked cross-attention mechanism to predict tokens based on an order of magnitude more data than what is typically consumed during training. We typically train RETRO from scratch, yet can also rapidly RETROfit pre-trained transformers with retrieval and still achieve good performance. Our work opens up new avenues for improving language models through explicit memory at unprecedented scale.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Dec 08, 2021



Language modelling provides a step towards intelligent communication systems by harnessing large repositories of written human knowledge to better predict and understand the world. In this paper, we present an analysis of Transformer-based language model performance across a wide range of model scales -- from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit. We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity. Finally we discuss the application of language models to AI safety and the mitigation of downstream harms.
Transformation-based Adversarial Video Prediction on Large-Scale Data
Mar 09, 2020
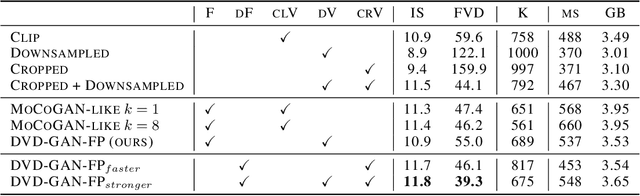
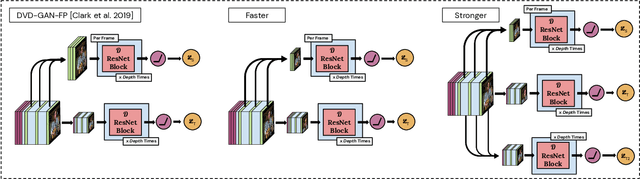
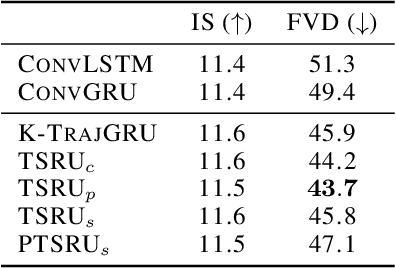
Recent breakthroughs in adversarial generative modeling have led to models capable of producing video samples of high quality, even on large and complex datasets of real-world video. In this work, we focus on the task of video prediction, where given a sequence of frames extracted from a video, the goal is to generate a plausible future sequence. We first improve the state of the art by performing a systematic empirical study of discriminator decompositions and proposing an architecture that yields faster convergence and higher performance than previous approaches. We then analyze recurrent units in the generator, and propose a novel recurrent unit which transforms its past hidden state according to predicted motion-like features, and refines it to to handle dis-occlusions, scene changes and other complex behavior. We show that this recurrent unit consistently outperforms previous designs. Our final model leads to a leap in the state-of-the-art performance, obtaining a test set Frechet Video Distance of 25.7, down from 69.2, on the large-scale Kinetics-600 dataset.
DeepMind Control Suite
Jan 02, 2018
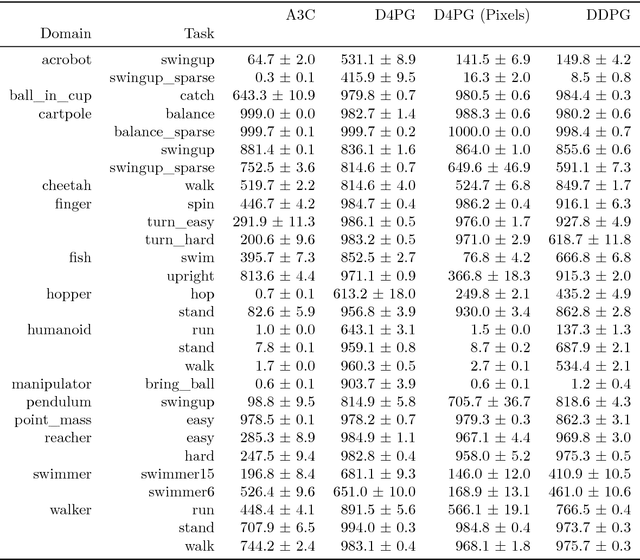
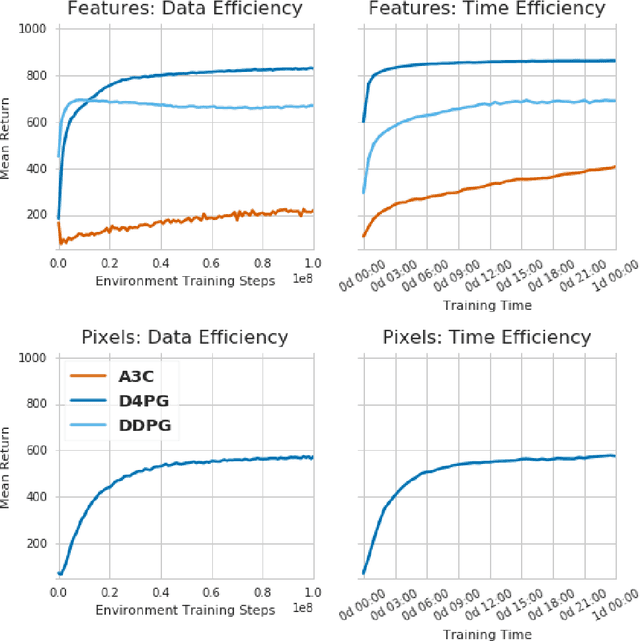
The DeepMind Control Suite is a set of continuous control tasks with a standardised structure and interpretable rewards, intended to serve as performance benchmarks for reinforcement learning agents. The tasks are written in Python and powered by the MuJoCo physics engine, making them easy to use and modify. We include benchmarks for several learning algorithms. The Control Suite is publicly available at https://www.github.com/deepmind/dm_control . A video summary of all tasks is available at http://youtu.be/rAai4QzcYbs .