 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWanting to be Understood
Apr 10, 2025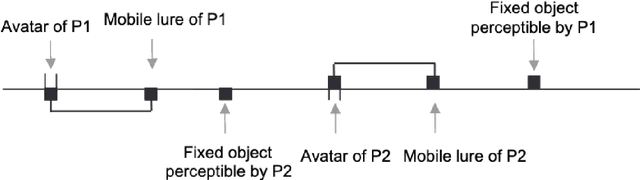
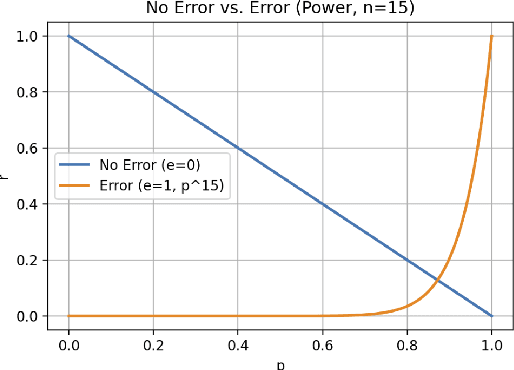
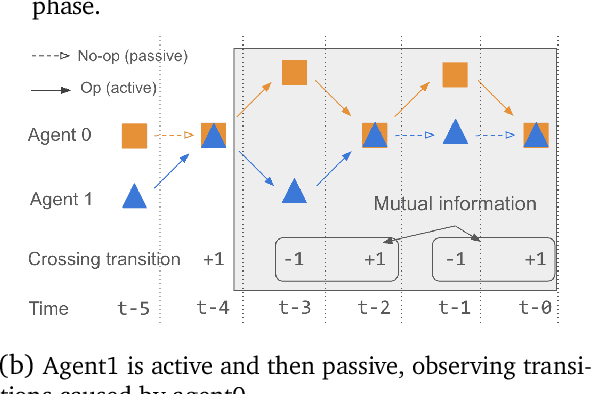
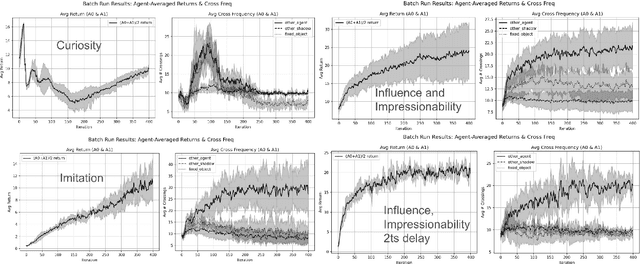
This paper explores an intrinsic motivation for mutual awareness, hypothesizing that humans possess a fundamental drive to understand and to be understood even in the absence of extrinsic rewards. Through simulations of the perceptual crossing paradigm, we explore the effect of various internal reward functions in reinforcement learning agents. The drive to understand is implemented as an active inference type artificial curiosity reward, whereas the drive to be understood is implemented through intrinsic rewards for imitation, influence/impressionability, and sub-reaction time anticipation of the other. Results indicate that while artificial curiosity alone does not lead to a preference for social interaction, rewards emphasizing reciprocal understanding successfully drive agents to prioritize interaction. We demonstrate that this intrinsic motivation can facilitate cooperation in tasks where only one agent receives extrinsic reward for the behaviour of the other.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution
Sep 28, 2023



Popular prompt strategies like Chain-of-Thought Prompting can dramatically improve the reasoning abilities of Large Language Models (LLMs) in various domains. However, such hand-crafted prompt-strategies are often sub-optimal. In this paper, we present Promptbreeder, a general-purpose self-referential self-improvement mechanism that evolves and adapts prompts for a given domain. Driven by an LLM, Promptbreeder mutates a population of task-prompts, and subsequently evaluates them for fitness on a training set. Crucially, the mutation of these task-prompts is governed by mutation-prompts that the LLM generates and improves throughout evolution in a self-referential way. That is, Promptbreeder is not just improving task-prompts, but it is also improving the mutationprompts that improve these task-prompts. Promptbreeder outperforms state-of-the-art prompt strategies such as Chain-of-Thought and Plan-and-Solve Prompting on commonly used arithmetic and commonsense reasoning benchmarks. Furthermore, Promptbreeder is able to evolve intricate task-prompts for the challenging problem of hate speech classification.
Perception Test: A Diagnostic Benchmark for Multimodal Video Models
May 23, 2023


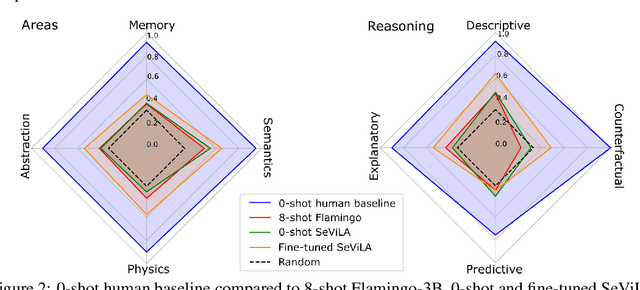
We propose a novel multimodal video benchmark - the Perception Test - to evaluate the perception and reasoning skills of pre-trained multimodal models (e.g. Flamingo, BEiT-3, or GPT-4). Compared to existing benchmarks that focus on computational tasks (e.g. classification, detection or tracking), the Perception Test focuses on skills (Memory, Abstraction, Physics, Semantics) and types of reasoning (descriptive, explanatory, predictive, counterfactual) across video, audio, and text modalities, to provide a comprehensive and efficient evaluation tool. The benchmark probes pre-trained models for their transfer capabilities, in a zero-shot / few-shot or limited finetuning regime. For these purposes, the Perception Test introduces 11.6k real-world videos, 23s average length, designed to show perceptually interesting situations, filmed by around 100 participants worldwide. The videos are densely annotated with six types of labels (multiple-choice and grounded video question-answers, object and point tracks, temporal action and sound segments), enabling both language and non-language evaluations. The fine-tuning and validation splits of the benchmark are publicly available (CC-BY license), in addition to a challenge server with a held-out test split. Human baseline results compared to state-of-the-art video QA models show a significant gap in performance (91.4% vs 43.6%), suggesting that there is significant room for improvement in multimodal video understanding. Dataset, baselines code, and challenge server are available at https://github.com/deepmind/perception_test
CLIP-CLOP: CLIP-Guided Collage and Photomontage
May 19, 2022
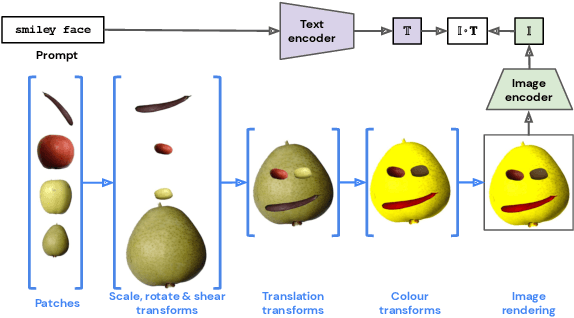
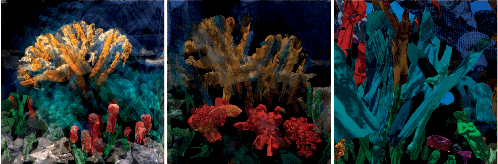
The unabated mystique of large-scale neural networks, such as the CLIP dual image-and-text encoder, popularized automatically generated art. Increasingly more sophisticated generators enhanced the artworks' realism and visual appearance, and creative prompt engineering enabled stylistic expression. Guided by an artist-in-the-loop ideal, we design a gradient-based generator to produce collages. It requires the human artist to curate libraries of image patches and to describe (with prompts) the whole image composition, with the option to manually adjust the patches' positions during generation, thereby allowing humans to reclaim some control of the process and achieve greater creative freedom. We explore the aesthetic potentials of high-resolution collages, and provide an open-source Google Colab as an artistic tool.
Generative Art Using Neural Visual Grammars and Dual Encoders
May 04, 2021


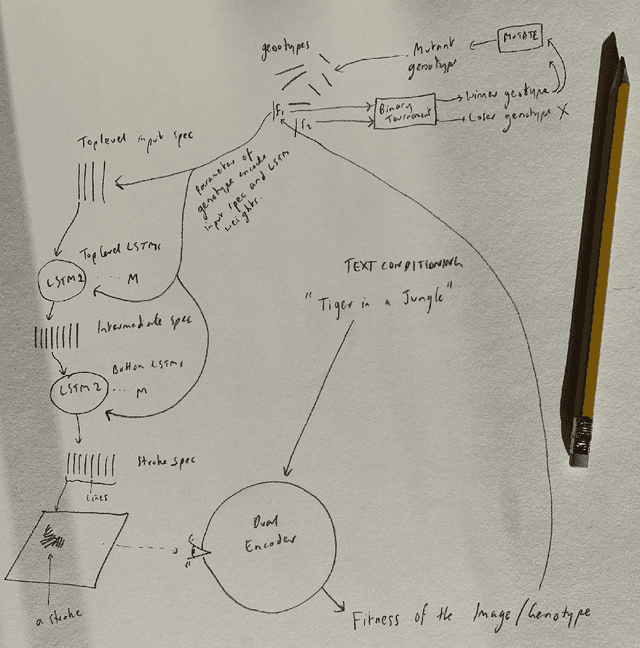
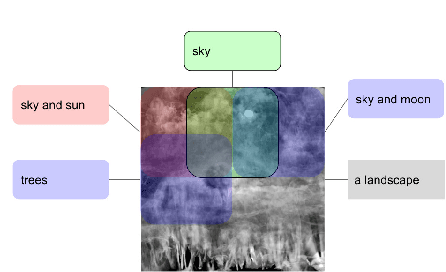
Whilst there are perhaps only a few scientific methods, there seem to be almost as many artistic methods as there are artists. Artistic processes appear to inhabit the highest order of open-endedness. To begin to understand some of the processes of art making it is helpful to try to automate them even partially. In this paper, a novel algorithm for producing generative art is described which allows a user to input a text string, and which in a creative response to this string, outputs an image which interprets that string. It does so by evolving images using a hierarchical neural Lindenmeyer system, and evaluating these images along the way using an image text dual encoder trained on billions of images and their associated text from the internet. In doing so we have access to and control over an instance of an artistic process, allowing analysis of which aspects of the artistic process become the task of the algorithm, and which elements remain the responsibility of the artist.
PathNet: Evolution Channels Gradient Descent in Super Neural Networks
Jan 30, 2017



For artificial general intelligence (AGI) it would be efficient if multiple users trained the same giant neural network, permitting parameter reuse, without catastrophic forgetting. PathNet is a first step in this direction. It is a neural network algorithm that uses agents embedded in the neural network whose task is to discover which parts of the network to re-use for new tasks. Agents are pathways (views) through the network which determine the subset of parameters that are used and updated by the forwards and backwards passes of the backpropogation algorithm. During learning, a tournament selection genetic algorithm is used to select pathways through the neural network for replication and mutation. Pathway fitness is the performance of that pathway measured according to a cost function. We demonstrate successful transfer learning; fixing the parameters along a path learned on task A and re-evolving a new population of paths for task B, allows task B to be learned faster than it could be learned from scratch or after fine-tuning. Paths evolved on task B re-use parts of the optimal path evolved on task A. Positive transfer was demonstrated for binary MNIST, CIFAR, and SVHN supervised learning classification tasks, and a set of Atari and Labyrinth reinforcement learning tasks, suggesting PathNets have general applicability for neural network training. Finally, PathNet also significantly improves the robustness to hyperparameter choices of a parallel asynchronous reinforcement learning algorithm (A3C).
Convolution by Evolution: Differentiable Pattern Producing Networks
Jun 08, 2016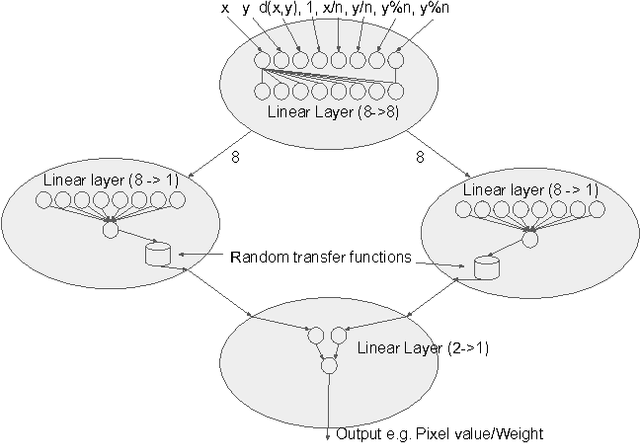



In this work we introduce a differentiable version of the Compositional Pattern Producing Network, called the DPPN. Unlike a standard CPPN, the topology of a DPPN is evolved but the weights are learned. A Lamarckian algorithm, that combines evolution and learning, produces DPPNs to reconstruct an image. Our main result is that DPPNs can be evolved/trained to compress the weights of a denoising autoencoder from 157684 to roughly 200 parameters, while achieving a reconstruction accuracy comparable to a fully connected network with more than two orders of magnitude more parameters. The regularization ability of the DPPN allows it to rediscover (approximate) convolutional network architectures embedded within a fully connected architecture. Such convolutional architectures are the current state of the art for many computer vision applications, so it is satisfying that DPPNs are capable of discovering this structure rather than having to build it in by design. DPPNs exhibit better generalization when tested on the Omniglot dataset after being trained on MNIST, than directly encoded fully connected autoencoders. DPPNs are therefore a new framework for integrating learning and evolution.