 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue with the Machine and Dialogue with the Art World: Evaluating Generative AI for Culturally-Situated Creativity
Dec 18, 2024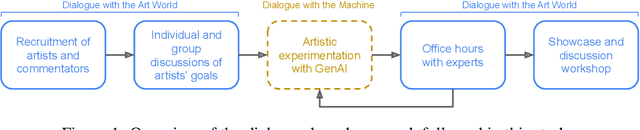
This paper proposes dialogue as a method for evaluating generative AI tools for culturally-situated creative practice, that recognizes the socially situated nature of art. Drawing on sociologist Howard Becker's concept of Art Worlds, this method expands the scope of traditional AI and creativity evaluations beyond benchmarks, user studies with crowd-workers, or focus groups conducted with artists. Our method involves two mutually informed dialogues: 1) 'dialogues with art worlds' placing artists in conversation with experts such as art historians, curators, and archivists, and 2)'dialogues with the machine,' facilitated through structured artist- and critic-led experimentation with state-of-the-art generative AI tools. We demonstrate the value of this method through a case study with artists and experts steeped in non-western art worlds, specifically the Persian Gulf. We trace how these dialogues help create culturally rich and situated forms of evaluation for representational possibilities of generative AI that mimic the reception of generative artwork in the broader art ecosystem. Putting artists in conversation with commentators also allow artists to shift their use of the tools to respond to their cultural and creative context. Our study can provide generative AI researchers an understanding of the complex dynamics of technology, human creativity and the socio-politics of art worlds, to build more inclusive machines for diverse art worlds.
Neural Compression of Atmospheric States
Jul 16, 2024



Atmospheric states derived from reanalysis comprise a substantial portion of weather and climate simulation outputs. Many stakeholders -- such as researchers, policy makers, and insurers -- use this data to better understand the earth system and guide policy decisions. Atmospheric states have also received increased interest as machine learning approaches to weather prediction have shown promising results. A key issue for all audiences is that dense time series of these high-dimensional states comprise an enormous amount of data, precluding all but the most well resourced groups from accessing and using historical data and future projections. To address this problem, we propose a method for compressing atmospheric states using methods from the neural network literature, adapting spherical data to processing by conventional neural architectures through the use of the area-preserving HEALPix projection. We investigate two model classes for building neural compressors: the hyperprior model from the neural image compression literature and recent vector-quantised models. We show that both families of models satisfy the desiderata of small average error, a small number of high-error reconstructed pixels, faithful reproduction of extreme events such as hurricanes and heatwaves, preservation of the spectral power distribution across spatial scales. We demonstrate compression ratios in excess of 1000x, with compression and decompression at a rate of approximately one second per global atmospheric state.
Designing and Evaluating Dialogue LLMs for Co-Creative Improvised Theatre
May 11, 2024


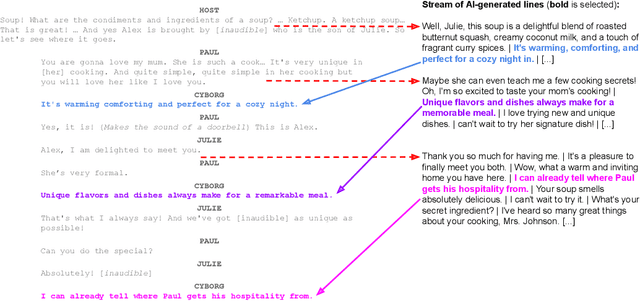
Social robotics researchers are increasingly interested in multi-party trained conversational agents. With a growing demand for real-world evaluations, our study presents Large Language Models (LLMs) deployed in a month-long live show at the Edinburgh Festival Fringe. This case study investigates human improvisers co-creating with conversational agents in a professional theatre setting. We explore the technical capabilities and constraints of on-the-spot multi-party dialogue, providing comprehensive insights from both audience and performer experiences with AI on stage. Our human-in-the-loop methodology underlines the challenges of these LLMs in generating context-relevant responses, stressing the user interface's crucial role. Audience feedback indicates an evolving interest for AI-driven live entertainment, direct human-AI interaction, and a diverse range of expectations about AI's conversational competence and utility as a creativity support tool. Human performers express immense enthusiasm, varied satisfaction, and the evolving public opinion highlights mixed emotions about AI's role in arts.
Co-Writing Screenplays and Theatre Scripts with Language Models: An Evaluation by Industry Professionals
Sep 29, 2022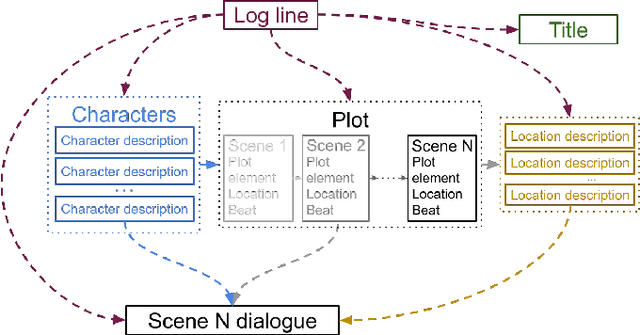

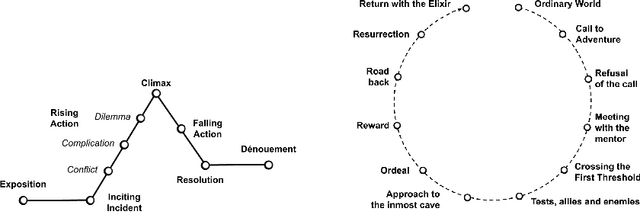
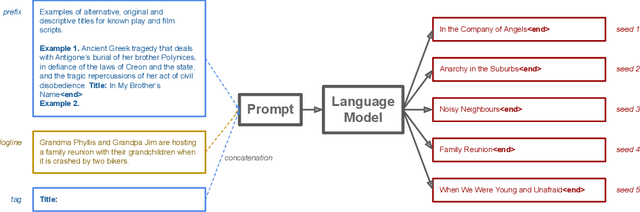
Language models are increasingly attracting interest from writers. However, such models lack long-range semantic coherence, limiting their usefulness for longform creative writing. We address this limitation by applying language models hierarchically, in a system we call Dramatron. By building structural context via prompt chaining, Dramatron can generate coherent scripts and screenplays complete with title, characters, story beats, location descriptions, and dialogue. We illustrate Dramatron's usefulness as an interactive co-creative system with a user study of 15 theatre and film industry professionals. Participants co-wrote theatre scripts and screenplays with Dramatron and engaged in open-ended interviews. We report critical reflections both from our interviewees and from independent reviewers who watched stagings of the works to illustrate how both Dramatron and hierarchical text generation could be useful for human-machine co-creativity. Finally, we discuss the suitability of Dramatron for co-creativity, ethical considerations -- including plagiarism and bias -- and participatory models for the design and deployment of such tools.
CLIP-CLOP: CLIP-Guided Collage and Photomontage
May 19, 2022
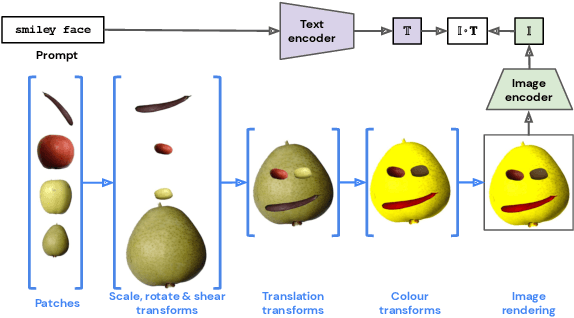
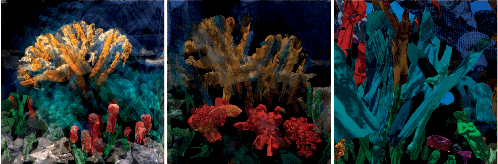
The unabated mystique of large-scale neural networks, such as the CLIP dual image-and-text encoder, popularized automatically generated art. Increasingly more sophisticated generators enhanced the artworks' realism and visual appearance, and creative prompt engineering enabled stylistic expression. Guided by an artist-in-the-loop ideal, we design a gradient-based generator to produce collages. It requires the human artist to curate libraries of image patches and to describe (with prompts) the whole image composition, with the option to manually adjust the patches' positions during generation, thereby allowing humans to reclaim some control of the process and achieve greater creative freedom. We explore the aesthetic potentials of high-resolution collages, and provide an open-source Google Colab as an artistic tool.
Collaborative Storytelling with Human Actors and AI Narrators
Sep 29, 2021
Large language models can be used for collaborative storytelling. In this work we report on using GPT-3 \cite{brown2020language} to co-narrate stories. The AI system must track plot progression and character arcs while the human actors perform scenes. This event report details how a novel conversational agent was employed as creative partner with a team of professional improvisers to explore long-form spontaneous story narration in front of a live public audience. We introduced novel constraints on our language model to produce longer narrative text and tested the model in rehearsals with a team of professional improvisers. We then field tested the model with two live performances for public audiences as part of a live theatre festival in Europe. We surveyed audience members after each performance as well as performers to evaluate how well the AI performed in its role as narrator. Audiences and performers responded positively to AI narration and indicated preference for AI narration over AI characters within a scene. Performers also responded positively to AI narration and expressed enthusiasm for the creative and meaningful novel narrative directions introduced to the scenes. Our findings support improvisational theatre as a useful test-bed to explore how different language models can collaborate with humans in a variety of social contexts.
Generative Art Using Neural Visual Grammars and Dual Encoders
May 04, 2021


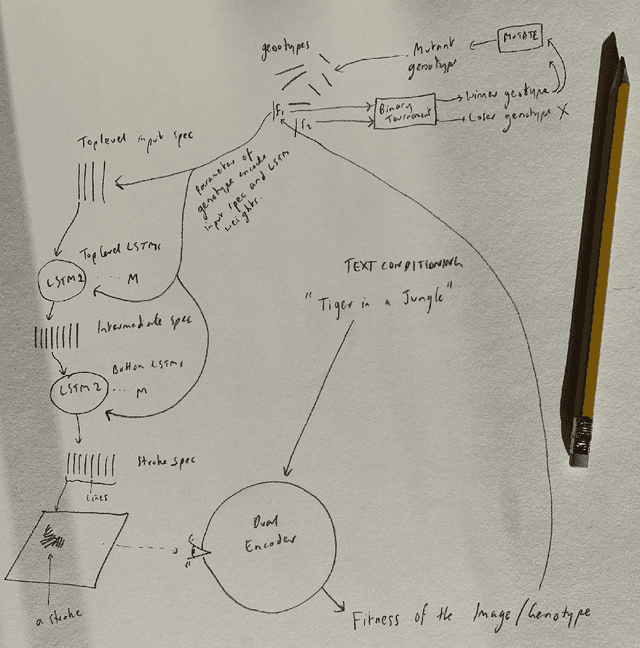
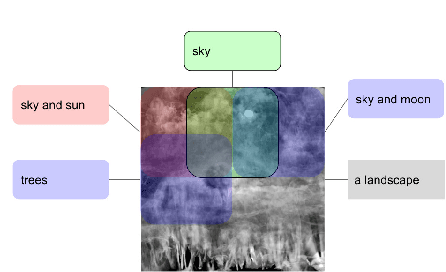
Whilst there are perhaps only a few scientific methods, there seem to be almost as many artistic methods as there are artists. Artistic processes appear to inhabit the highest order of open-endedness. To begin to understand some of the processes of art making it is helpful to try to automate them even partially. In this paper, a novel algorithm for producing generative art is described which allows a user to input a text string, and which in a creative response to this string, outputs an image which interprets that string. It does so by evolving images using a hierarchical neural Lindenmeyer system, and evaluating these images along the way using an image text dual encoder trained on billions of images and their associated text from the internet. In doing so we have access to and control over an instance of an artistic process, allowing analysis of which aspects of the artistic process become the task of the algorithm, and which elements remain the responsibility of the artist.
Skillful Precipitation Nowcasting using Deep Generative Models of Radar
Apr 02, 2021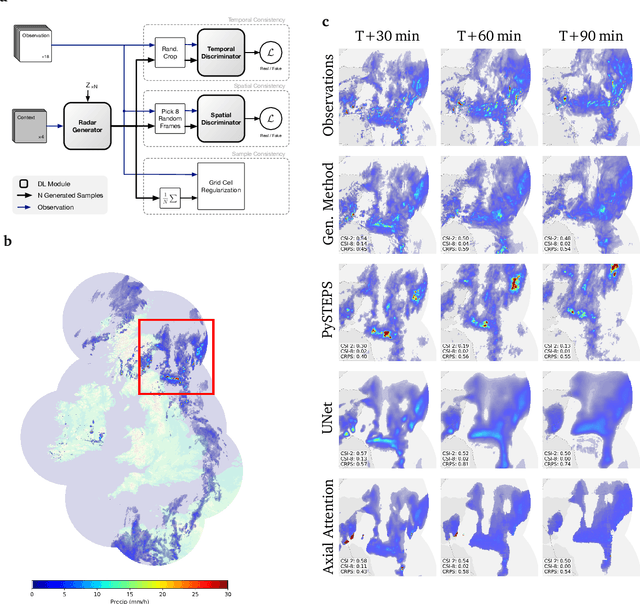
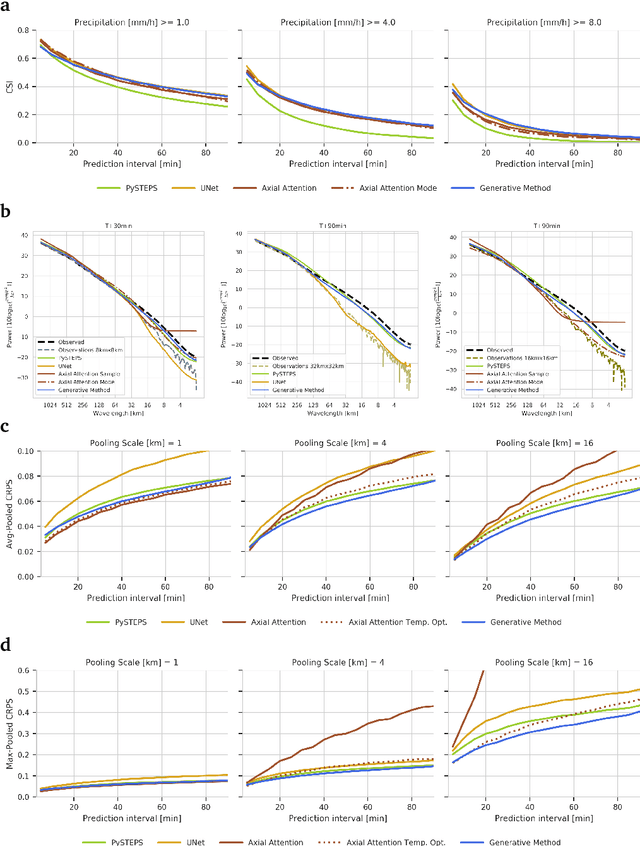
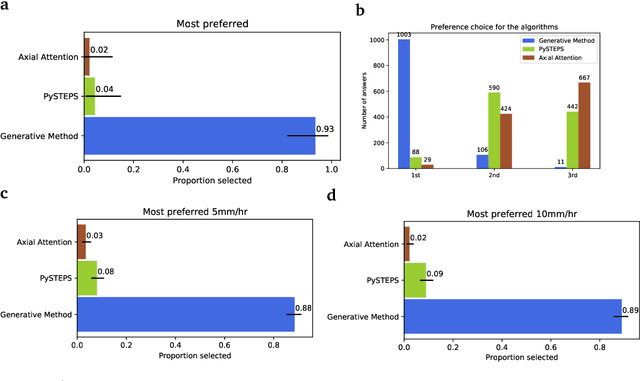
Precipitation nowcasting, the high-resolution forecasting of precipitation up to two hours ahead, supports the real-world socio-economic needs of many sectors reliant on weather-dependent decision-making. State-of-the-art operational nowcasting methods typically advect precipitation fields with radar-based wind estimates, and struggle to capture important non-linear events such as convective initiations. Recently introduced deep learning methods use radar to directly predict future rain rates, free of physical constraints. While they accurately predict low-intensity rainfall, their operational utility is limited because their lack of constraints produces blurry nowcasts at longer lead times, yielding poor performance on more rare medium-to-heavy rain events. To address these challenges, we present a Deep Generative Model for the probabilistic nowcasting of precipitation from radar. Our model produces realistic and spatio-temporally consistent predictions over regions up to 1536 km x 1280 km and with lead times from 5-90 min ahead. In a systematic evaluation by more than fifty expert forecasters from the Met Office, our generative model ranked first for its accuracy and usefulness in 88% of cases against two competitive methods, demonstrating its decision-making value and ability to provide physical insight to real-world experts. When verified quantitatively, these nowcasts are skillful without resorting to blurring. We show that generative nowcasting can provide probabilistic predictions that improve forecast value and support operational utility, and at resolutions and lead times where alternative methods struggle.
Retouchdown: Adding Touchdown to StreetLearn as a Shareable Resource for Language Grounding Tasks in Street View
Jan 10, 2020
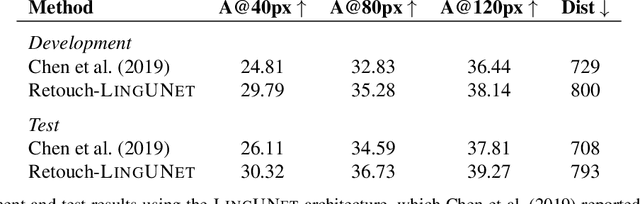

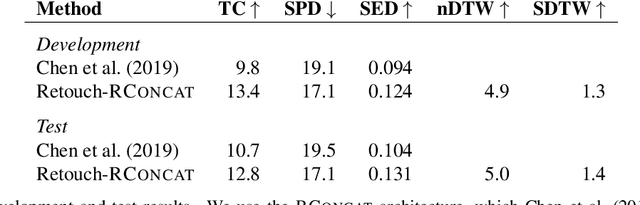
The Touchdown dataset (Chen et al., 2019) provides instructions by human annotators for navigation through New York City streets and for resolving spatial descriptions at a given location. To enable the wider research community to work effectively with the Touchdown tasks, we are publicly releasing the 29k raw Street View panoramas needed for Touchdown. We follow the process used for the StreetLearn data release (Mirowski et al., 2019) to check panoramas for personally identifiable information and blur them as necessary. These have been added to the StreetLearn dataset and can be obtained via the same process as used previously for StreetLearn. We also provide a reference implementation for both of the Touchdown tasks: vision and language navigation (VLN) and spatial description resolution (SDR). We compare our model results to those given in Chen et al. (2019) and show that the panoramas we have added to StreetLearn fully support both Touchdown tasks and can be used effectively for further research and comparison.
Cross-View Policy Learning for Street Navigation
Jun 13, 2019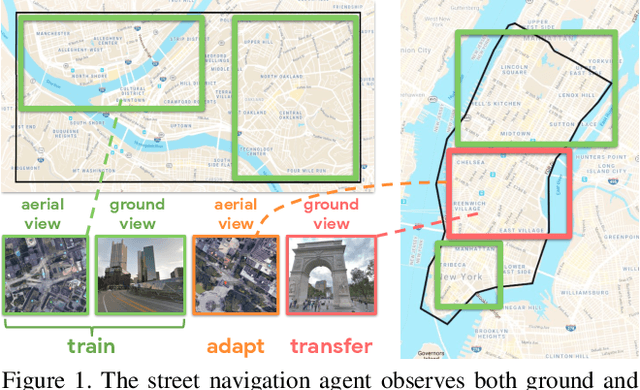
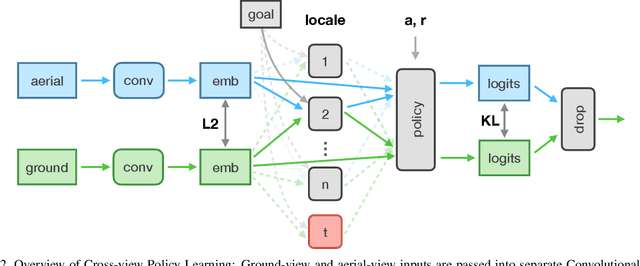
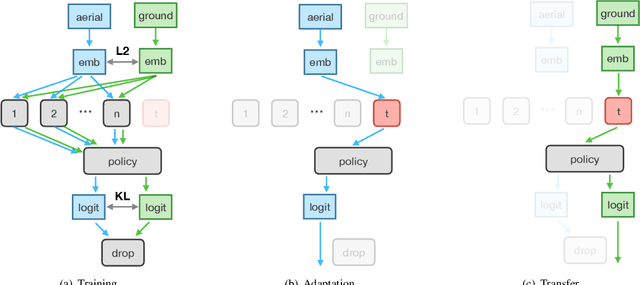
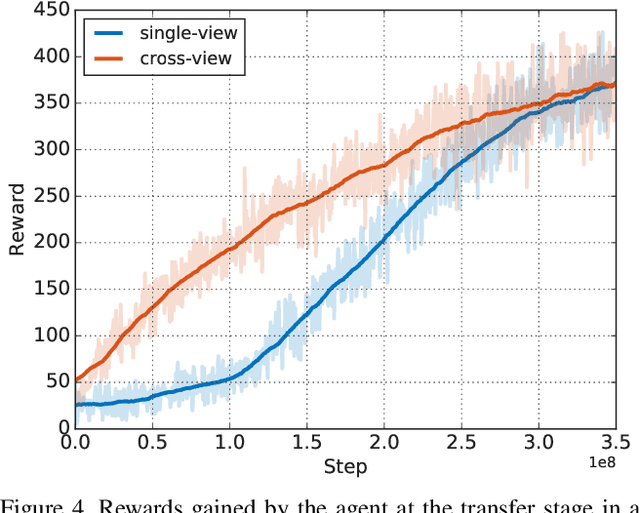
The ability to navigate from visual observations in unfamiliar environments is a core component of intelligent agents and an ongoing challenge for Deep Reinforcement Learning (RL). Street View can be a sensible testbed for such RL agents, because it provides real-world photographic imagery at ground level, with diverse street appearances; it has been made into an interactive environment called StreetLearn and used for research on navigation. However, goal-driven street navigation agents have not so far been able to transfer to unseen areas without extensive retraining, and relying on simulation is not a scalable solution. Since aerial images are easily and globally accessible, we propose instead to train a multi-modal policy on ground and aerial views, then transfer the ground view policy to unseen (target) parts of the city by utilizing aerial view observations. Our core idea is to pair the ground view with an aerial view and to learn a joint policy that is transferable across views. We achieve this by learning a similar embedding space for both views, distilling the policy across views and dropping out visual modalities. We further reformulate the transfer learning paradigm into three stages: 1) cross-modal training, when the agent is initially trained on multiple city regions, 2) aerial view-only adaptation to a new area, when the agent is adapted to a held-out region using only the easily obtainable aerial view, and 3) ground view-only transfer, when the agent is tested on navigation tasks on unseen ground views, without aerial imagery. Experimental results suggest that the proposed cross-view policy learning enables better generalization of the agent and allows for more effective transfer to unseen environments.