 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Flamingo: a Visual Language Model for Few-Shot Learning
Apr 29, 2022
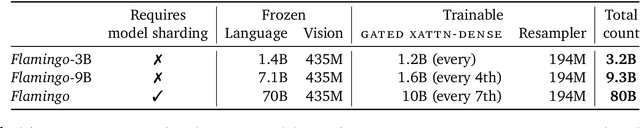
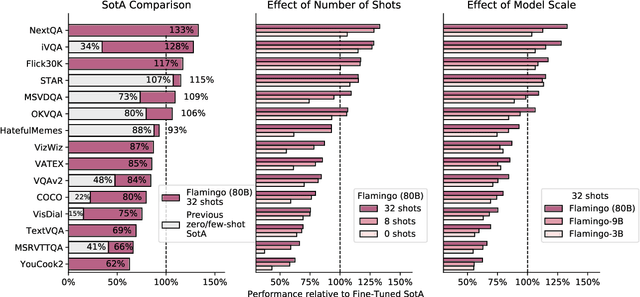
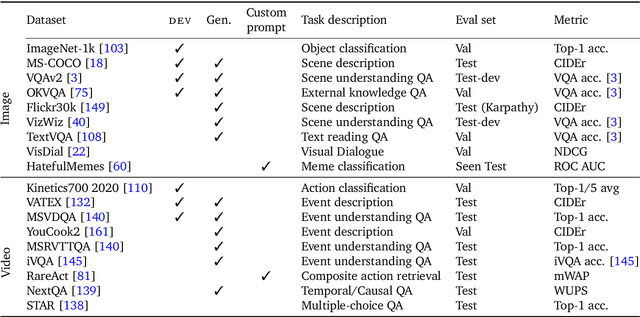
Building models that can be rapidly adapted to numerous tasks using only a handful of annotated examples is an open challenge for multimodal machine learning research. We introduce Flamingo, a family of Visual Language Models (VLM) with this ability. Flamingo models include key architectural innovations to: (i) bridge powerful pretrained vision-only and language-only models, (ii) handle sequences of arbitrarily interleaved visual and textual data, and (iii) seamlessly ingest images or videos as inputs. Thanks to their flexibility, Flamingo models can be trained on large-scale multimodal web corpora containing arbitrarily interleaved text and images, which is key to endow them with in-context few-shot learning capabilities. We perform a thorough evaluation of the proposed Flamingo models, exploring and measuring their ability to rapidly adapt to a variety of image and video understanding benchmarks. These include open-ended tasks such as visual question-answering, where the model is prompted with a question which it has to answer, captioning tasks, which evaluate the ability to describe a scene or an event, and close-ended tasks such as multiple choice visual question-answering. For tasks lying anywhere on this spectrum, we demonstrate that a single Flamingo model can achieve a new state of the art for few-shot learning, simply by prompting the model with task-specific examples. On many of these benchmarks, Flamingo actually surpasses the performance of models that are fine-tuned on thousands of times more task-specific data.
Skillful Precipitation Nowcasting using Deep Generative Models of Radar
Apr 02, 2021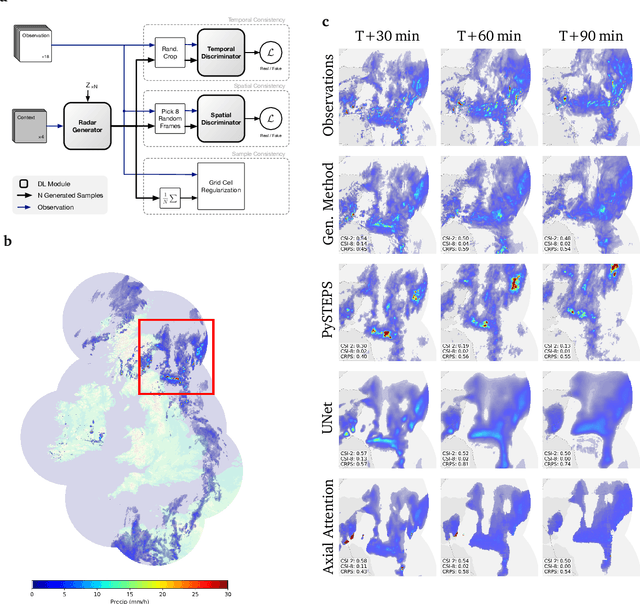
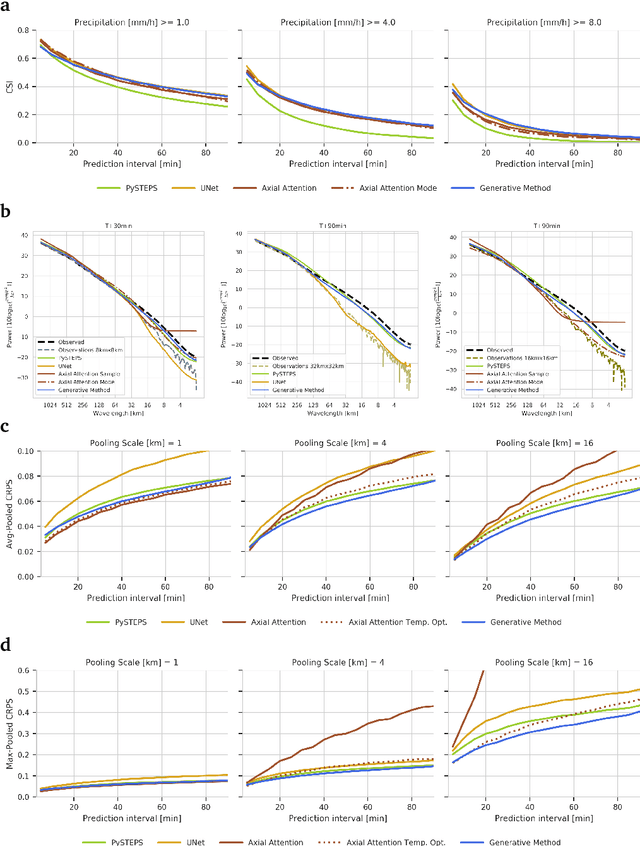
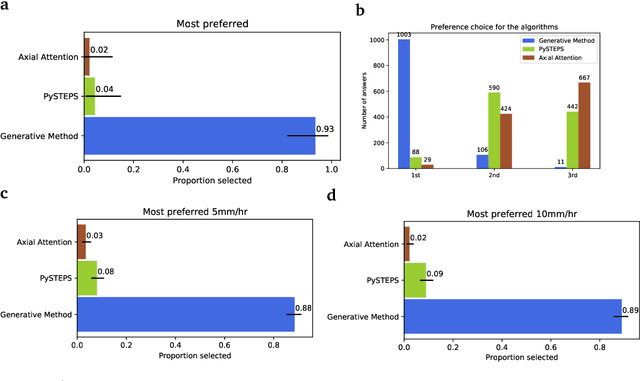
Precipitation nowcasting, the high-resolution forecasting of precipitation up to two hours ahead, supports the real-world socio-economic needs of many sectors reliant on weather-dependent decision-making. State-of-the-art operational nowcasting methods typically advect precipitation fields with radar-based wind estimates, and struggle to capture important non-linear events such as convective initiations. Recently introduced deep learning methods use radar to directly predict future rain rates, free of physical constraints. While they accurately predict low-intensity rainfall, their operational utility is limited because their lack of constraints produces blurry nowcasts at longer lead times, yielding poor performance on more rare medium-to-heavy rain events. To address these challenges, we present a Deep Generative Model for the probabilistic nowcasting of precipitation from radar. Our model produces realistic and spatio-temporally consistent predictions over regions up to 1536 km x 1280 km and with lead times from 5-90 min ahead. In a systematic evaluation by more than fifty expert forecasters from the Met Office, our generative model ranked first for its accuracy and usefulness in 88% of cases against two competitive methods, demonstrating its decision-making value and ability to provide physical insight to real-world experts. When verified quantitatively, these nowcasts are skillful without resorting to blurring. We show that generative nowcasting can provide probabilistic predictions that improve forecast value and support operational utility, and at resolutions and lead times where alternative methods struggle.
Non-Differentiable Supervised Learning with Evolution Strategies and Hybrid Methods
Jun 07, 2019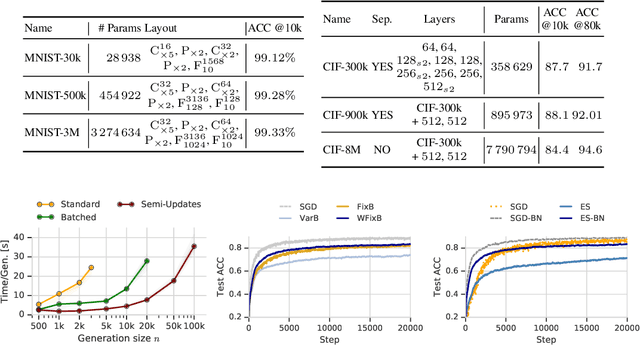



In this work we show that Evolution Strategies (ES) are a viable method for learning non-differentiable parameters of large supervised models. ES are black-box optimization algorithms that estimate distributions of model parameters; however they have only been used for relatively small problems so far. We show that it is possible to scale ES to more complex tasks and models with millions of parameters. While using ES for differentiable parameters is computationally impractical (although possible), we show that a hybrid approach is practically feasible in the case where the model has both differentiable and non-differentiable parameters. In this approach we use standard gradient-based methods for learning differentiable weights, while using ES for learning non-differentiable parameters - in our case sparsity masks of the weights. This proposed method is surprisingly competitive, and when parallelized over multiple devices has only negligible training time overhead compared to training with gradient descent. Additionally, this method allows to train sparse models from the first training step, so they can be much larger than when using methods that require training dense models first. We present results and analysis of supervised feed-forward models (such as MNIST and CIFAR-10 classification), as well as recurrent models, such as SparseWaveRNN for text-to-speech.
Large scale evaluation of local image feature detectors on homography datasets
Jul 20, 2018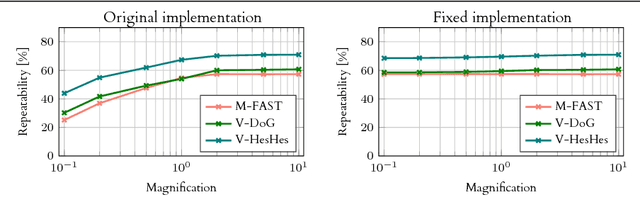
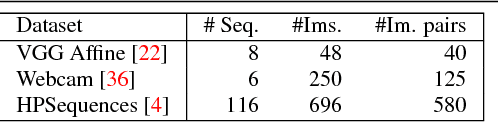
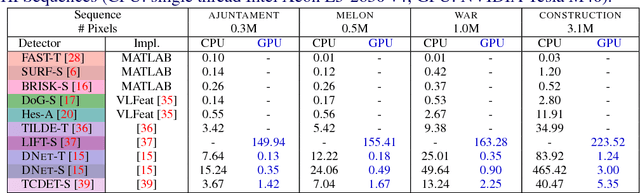
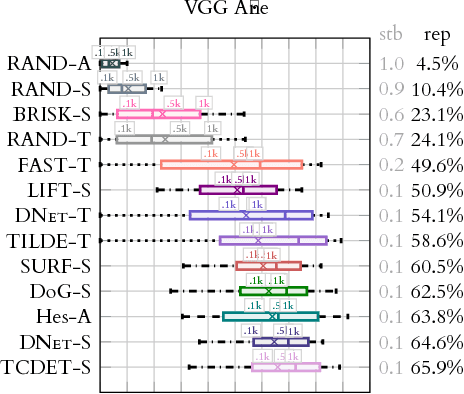
We present a large scale benchmark for the evaluation of local feature detectors. Our key innovation is the introduction of a new evaluation protocol which extends and improves the standard detection repeatability measure. The new protocol is better for assessment on a large number of images and reduces the dependency of the results on unwanted distractors such as the number of detected features and the feature magnification factor. Additionally, our protocol provides a comprehensive assessment of the expected performance of detectors under several practical scenarios. Using images from the recently-introduced HPatches dataset, we evaluate a range of state-of-the-art local feature detectors on two main tasks: viewpoint and illumination invariant detection. Contrary to previous detector evaluations, our study contains an order of magnitude more image sequences, resulting in a quantitative evaluation significantly more robust to over-fitting. We also show that traditional detectors are still very competitive when compared to recent deep-learning alternatives.
HPatches: A benchmark and evaluation of handcrafted and learned local descriptors
Apr 19, 2017

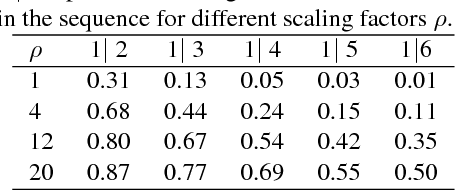

In this paper, we propose a novel benchmark for evaluating local image descriptors. We demonstrate that the existing datasets and evaluation protocols do not specify unambiguously all aspects of evaluation, leading to ambiguities and inconsistencies in results reported in the literature. Furthermore, these datasets are nearly saturated due to the recent improvements in local descriptors obtained by learning them from large annotated datasets. Therefore, we introduce a new large dataset suitable for training and testing modern descriptors, together with strictly defined evaluation protocols in several tasks such as matching, retrieval and classification. This allows for more realistic, and thus more reliable comparisons in different application scenarios. We evaluate the performance of several state-of-the-art descriptors and analyse their properties. We show that a simple normalisation of traditional hand-crafted descriptors can boost their performance to the level of deep learning based descriptors within a realistic benchmarks evaluation.
Learning Covariant Feature Detectors
Sep 09, 2016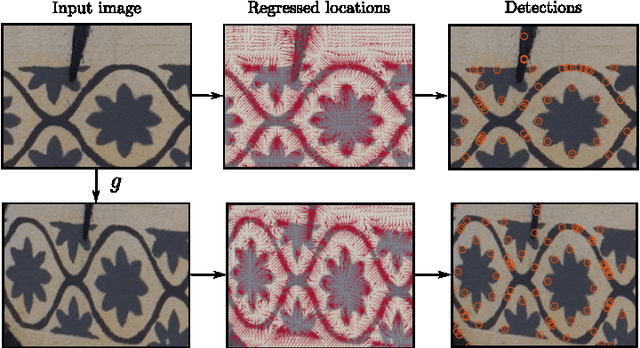

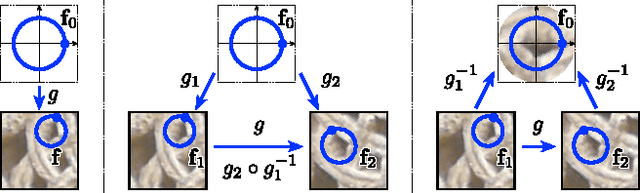

Local covariant feature detection, namely the problem of extracting viewpoint invariant features from images, has so far largely resisted the application of machine learning techniques. In this paper, we propose the first fully general formulation for learning local covariant feature detectors. We propose to cast detection as a regression problem, enabling the use of powerful regressors such as deep neural networks. We then derive a covariance constraint that can be used to automatically learn which visual structures provide stable anchors for local feature detection. We support these ideas theoretically, proposing a novel analysis of local features in term of geometric transformations, and we show that all common and many uncommon detectors can be derived in this framework. Finally, we present empirical results on translation and rotation covariant detectors on standard feature benchmarks, showing the power and flexibility of the framework.
MatConvNet - Convolutional Neural Networks for MATLAB
May 05, 2016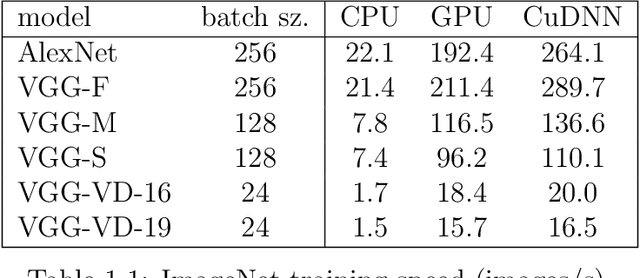
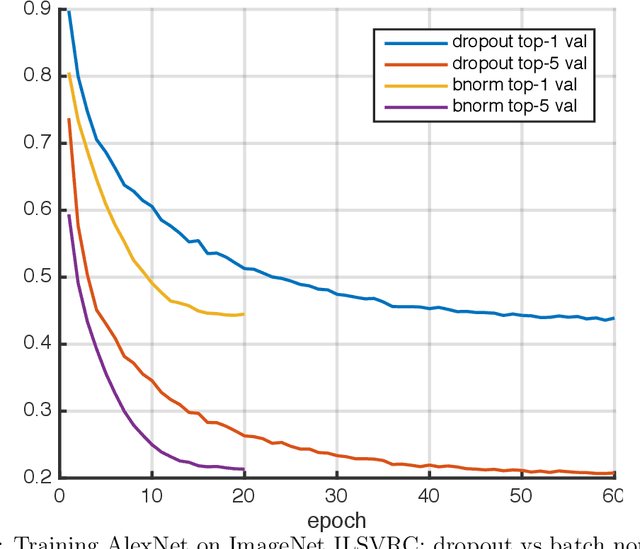


MatConvNet is an implementation of Convolutional Neural Networks (CNNs) for MATLAB. The toolbox is designed with an emphasis on simplicity and flexibility. It exposes the building blocks of CNNs as easy-to-use MATLAB functions, providing routines for computing linear convolutions with filter banks, feature pooling, and many more. In this manner, MatConvNet allows fast prototyping of new CNN architectures; at the same time, it supports efficient computation on CPU and GPU allowing to train complex models on large datasets such as ImageNet ILSVRC. This document provides an overview of CNNs and how they are implemented in MatConvNet and gives the technical details of each computational block in the toolbox.
R-CNN minus R
Jun 23, 2015
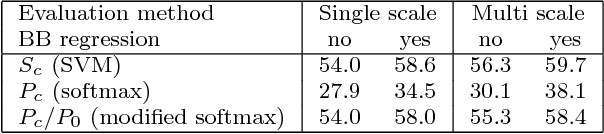
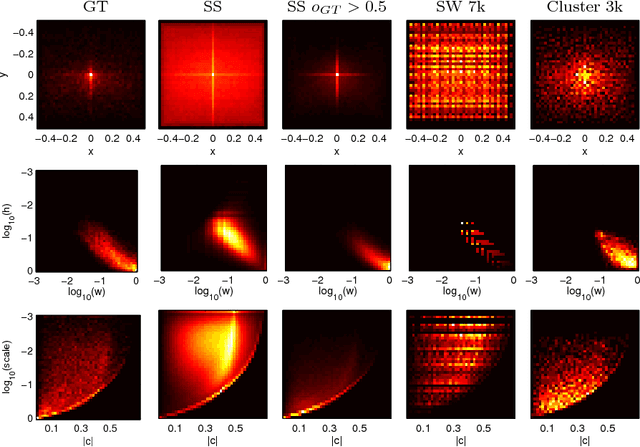

Deep convolutional neural networks (CNNs) have had a major impact in most areas of image understanding, including object category detection. In object detection, methods such as R-CNN have obtained excellent results by integrating CNNs with region proposal generation algorithms such as selective search. In this paper, we investigate the role of proposal generation in CNN-based detectors in order to determine whether it is a necessary modelling component, carrying essential geometric information not contained in the CNN, or whether it is merely a way of accelerating detection. We do so by designing and evaluating a detector that uses a trivial region generation scheme, constant for each image. Combined with SPP, this results in an excellent and fast detector that does not require to process an image with algorithms other than the CNN itself. We also streamline and simplify the training of CNN-based detectors by integrating several learning steps in a single algorithm, as well as by proposing a number of improvements that accelerate detection.