 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI tutoring can safely and effectively support students: An exploratory RCT in UK classrooms
Dec 29, 2025One-to-one tutoring is widely considered the gold standard for personalized education, yet it remains prohibitively expensive to scale. To evaluate whether generative AI might help expand access to this resource, we conducted an exploratory randomized controlled trial (RCT) with $N = 165$ students across five UK secondary schools. We integrated LearnLM -- a generative AI model fine-tuned for pedagogy -- into chat-based tutoring sessions on the Eedi mathematics platform. In the RCT, expert tutors directly supervised LearnLM, with the remit to revise each message it drafted until they would be satisfied sending it themselves. LearnLM proved to be a reliable source of pedagogical instruction, with supervising tutors approving 76.4% of its drafted messages making zero or minimal edits (i.e., changing only one or two characters). This translated into effective tutoring support: students guided by LearnLM performed at least as well as students chatting with human tutors on each learning outcome we measured. In fact, students who received support from LearnLM were 5.5 percentage points more likely to solve novel problems on subsequent topics (with a success rate of 66.2%) than those who received tutoring from human tutors alone (rate of 60.7%). In interviews, tutors highlighted LearnLM's strength at drafting Socratic questions that encouraged deeper reflection from students, with multiple tutors even reporting that they learned new pedagogical practices from the model. Overall, our results suggest that pedagogically fine-tuned AI tutoring systems may play a promising role in delivering effective, individualized learning support at scale.
Evaluating Gemini in an arena for learning
May 30, 2025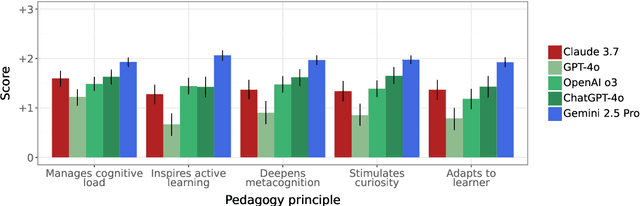

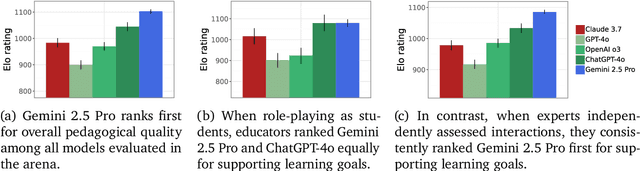
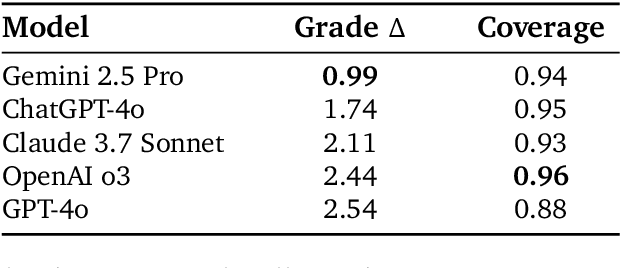
Artificial intelligence (AI) is poised to transform education, but the research community lacks a robust, general benchmark to evaluate AI models for learning. To assess state-of-the-art support for educational use cases, we ran an "arena for learning" where educators and pedagogy experts conduct blind, head-to-head, multi-turn comparisons of leading AI models. In particular, $N = 189$ educators drew from their experience to role-play realistic learning use cases, interacting with two models sequentially, after which $N = 206$ experts judged which model better supported the user's learning goals. The arena evaluated a slate of state-of-the-art models: Gemini 2.5 Pro, Claude 3.7 Sonnet, GPT-4o, and OpenAI o3. Excluding ties, experts preferred Gemini 2.5 Pro in 73.2% of these match-ups -- ranking it first overall in the arena. Gemini 2.5 Pro also demonstrated markedly higher performance across key principles of good pedagogy. Altogether, these results position Gemini 2.5 Pro as a leading model for learning.
LearnLM: Improving Gemini for Learning
Dec 21, 2024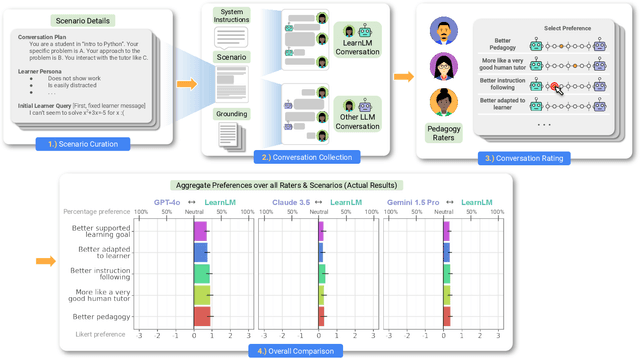
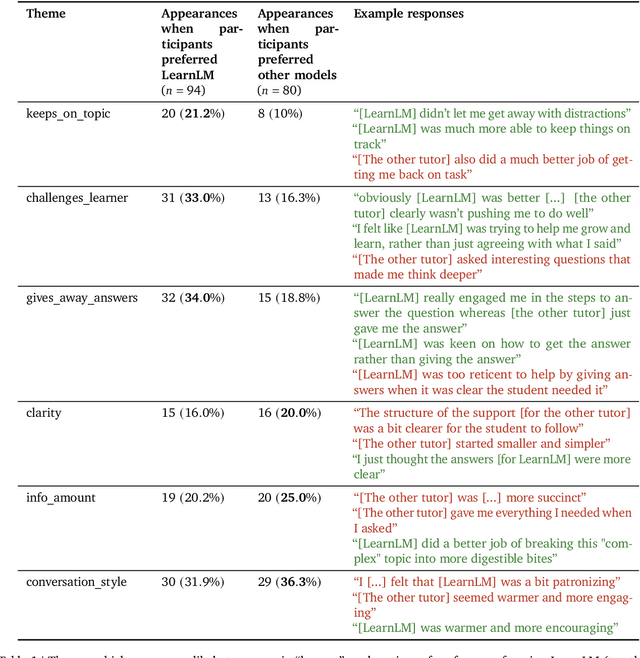
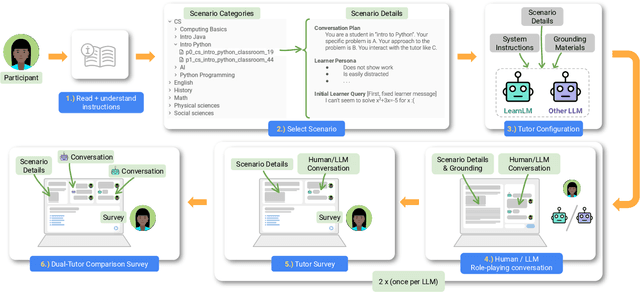
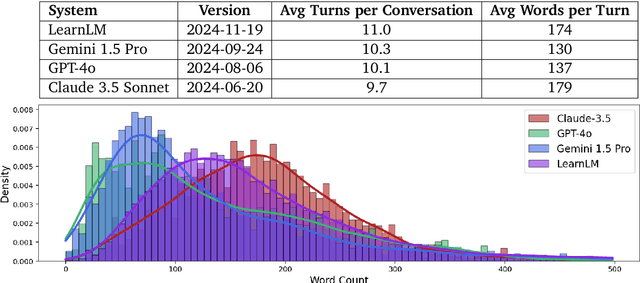
Today's generative AI systems are tuned to present information by default rather than engage users in service of learning as a human tutor would. To address the wide range of potential education use cases for these systems, we reframe the challenge of injecting pedagogical behavior as one of \textit{pedagogical instruction following}, where training and evaluation examples include system-level instructions describing the specific pedagogy attributes present or desired in subsequent model turns. This framing avoids committing our models to any particular definition of pedagogy, and instead allows teachers or developers to specify desired model behavior. It also clears a path to improving Gemini models for learning -- by enabling the addition of our pedagogical data to post-training mixtures -- alongside their rapidly expanding set of capabilities. Both represent important changes from our initial tech report. We show how training with pedagogical instruction following produces a LearnLM model (available on Google AI Studio) that is preferred substantially by expert raters across a diverse set of learning scenarios, with average preference strengths of 31\% over GPT-4o, 11\% over Claude 3.5, and 13\% over the Gemini 1.5 Pro model LearnLM was based on.
Epistemic Injustice in Generative AI
Aug 21, 2024
This paper investigates how generative AI can potentially undermine the integrity of collective knowledge and the processes we rely on to acquire, assess, and trust information, posing a significant threat to our knowledge ecosystem and democratic discourse. Grounded in social and political philosophy, we introduce the concept of \emph{generative algorithmic epistemic injustice}. We identify four key dimensions of this phenomenon: amplified and manipulative testimonial injustice, along with hermeneutical ignorance and access injustice. We illustrate each dimension with real-world examples that reveal how generative AI can produce or amplify misinformation, perpetuate representational harm, and create epistemic inequities, particularly in multilingual contexts. By highlighting these injustices, we aim to inform the development of epistemically just generative AI systems, proposing strategies for resistance, system design principles, and two approaches that leverage generative AI to foster a more equitable information ecosystem, thereby safeguarding democratic values and the integrity of knowledge production.
Neural Compression of Atmospheric States
Jul 16, 2024



Atmospheric states derived from reanalysis comprise a substantial portion of weather and climate simulation outputs. Many stakeholders -- such as researchers, policy makers, and insurers -- use this data to better understand the earth system and guide policy decisions. Atmospheric states have also received increased interest as machine learning approaches to weather prediction have shown promising results. A key issue for all audiences is that dense time series of these high-dimensional states comprise an enormous amount of data, precluding all but the most well resourced groups from accessing and using historical data and future projections. To address this problem, we propose a method for compressing atmospheric states using methods from the neural network literature, adapting spherical data to processing by conventional neural architectures through the use of the area-preserving HEALPix projection. We investigate two model classes for building neural compressors: the hyperprior model from the neural image compression literature and recent vector-quantised models. We show that both families of models satisfy the desiderata of small average error, a small number of high-error reconstructed pixels, faithful reproduction of extreme events such as hurricanes and heatwaves, preservation of the spectral power distribution across spatial scales. We demonstrate compression ratios in excess of 1000x, with compression and decompression at a rate of approximately one second per global atmospheric state.
A Robot Walks into a Bar: Can Language Models Serve as Creativity Support Tools for Comedy? An Evaluation of LLMs' Humour Alignment with Comedians
Jun 03, 2024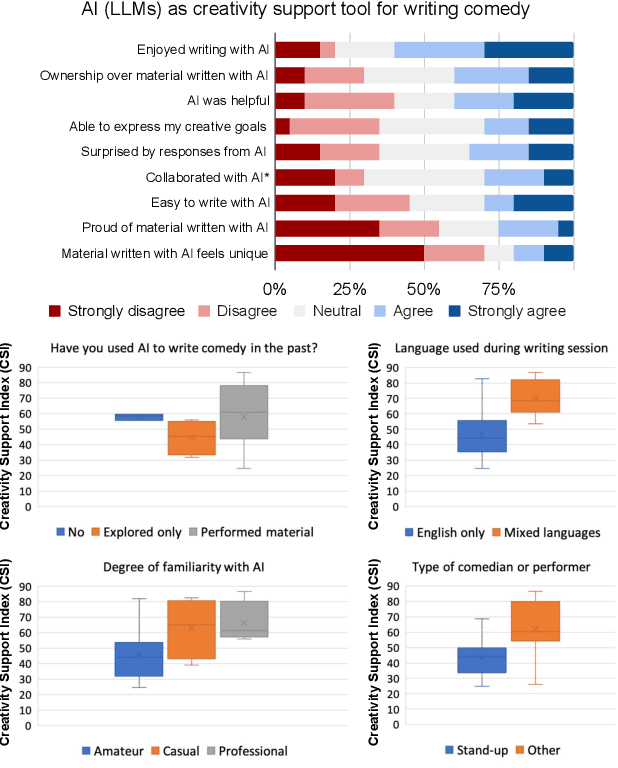
We interviewed twenty professional comedians who perform live shows in front of audiences and who use artificial intelligence in their artistic process as part of 3-hour workshops on ``AI x Comedy'' conducted at the Edinburgh Festival Fringe in August 2023 and online. The workshop consisted of a comedy writing session with large language models (LLMs), a human-computer interaction questionnaire to assess the Creativity Support Index of AI as a writing tool, and a focus group interrogating the comedians' motivations for and processes of using AI, as well as their ethical concerns about bias, censorship and copyright. Participants noted that existing moderation strategies used in safety filtering and instruction-tuned LLMs reinforced hegemonic viewpoints by erasing minority groups and their perspectives, and qualified this as a form of censorship. At the same time, most participants felt the LLMs did not succeed as a creativity support tool, by producing bland and biased comedy tropes, akin to ``cruise ship comedy material from the 1950s, but a bit less racist''. Our work extends scholarship about the subtle difference between, one the one hand, harmful speech, and on the other hand, ``offensive'' language as a practice of resistance, satire and ``punching up''. We also interrogate the global value alignment behind such language models, and discuss the importance of community-based value alignment and data ownership to build AI tools that better suit artists' needs.
GenCast: Diffusion-based ensemble forecasting for medium-range weather
Dec 25, 2023



Probabilistic weather forecasting is critical for decision-making in high-impact domains such as flood forecasting, energy system planning or transportation routing, where quantifying the uncertainty of a forecast -- including probabilities of extreme events -- is essential to guide important cost-benefit trade-offs and mitigation measures. Traditional probabilistic approaches rely on producing ensembles from physics-based models, which sample from a joint distribution over spatio-temporally coherent weather trajectories, but are expensive to run. An efficient alternative is to use a machine learning (ML) forecast model to generate the ensemble, however state-of-the-art ML forecast models for medium-range weather are largely trained to produce deterministic forecasts which minimise mean-squared-error. Despite improving skills scores, they lack physical consistency, a limitation that grows at longer lead times and impacts their ability to characterize the joint distribution. We introduce GenCast, a ML-based generative model for ensemble weather forecasting, trained from reanalysis data. It forecasts ensembles of trajectories for 84 weather variables, for up to 15 days at 1 degree resolution globally, taking around a minute per ensemble member on a single Cloud TPU v4 device. We show that GenCast is more skillful than ENS, a top operational ensemble forecast, for more than 96\% of all 1320 verification targets on CRPS and Ensemble-Mean RMSE, while maintaining good reliability and physically consistent power spectra. Together our results demonstrate that ML-based probabilistic weather forecasting can now outperform traditional ensemble systems at 1 degree, opening new doors to skillful, fast weather forecasts that are useful in key applications.
Understanding Deep Generative Models with Generalized Empirical Likelihoods
Jun 16, 2023Understanding how well a deep generative model captures a distribution of high-dimensional data remains an important open challenge. It is especially difficult for certain model classes, such as Generative Adversarial Networks and Diffusion Models, whose models do not admit exact likelihoods. In this work, we demonstrate that generalized empirical likelihood (GEL) methods offer a family of diagnostic tools that can identify many deficiencies of deep generative models (DGMs). We show, with appropriate specification of moment conditions, that the proposed method can identify which modes have been dropped, the degree to which DGMs are mode imbalanced, and whether DGMs sufficiently capture intra-class diversity. We show how to combine techniques from Maximum Mean Discrepancy and Generalized Empirical Likelihood to create not only distribution tests that retain per-sample interpretability, but also metrics that include label information. We find that such tests predict the degree of mode dropping and mode imbalance up to 60% better than metrics such as improved precision/recall.
GraphCast: Learning skillful medium-range global weather forecasting
Dec 24, 2022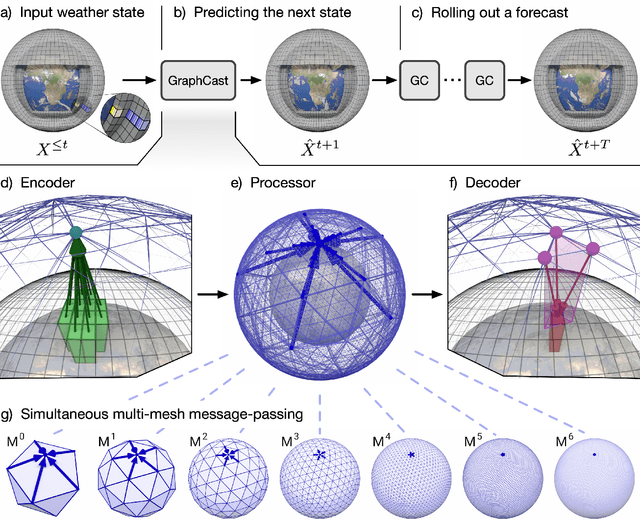
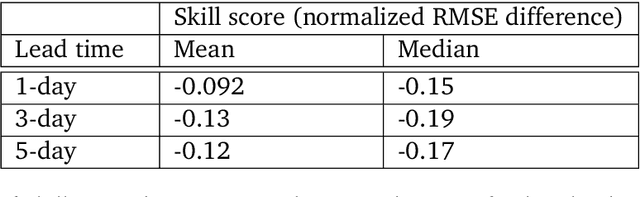
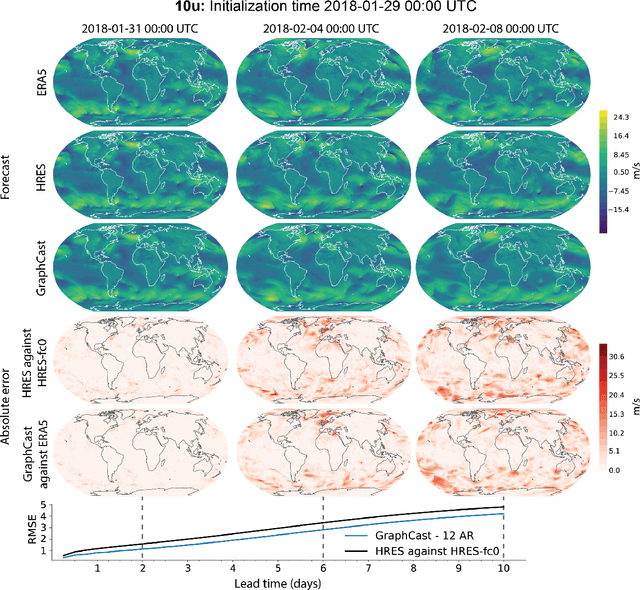
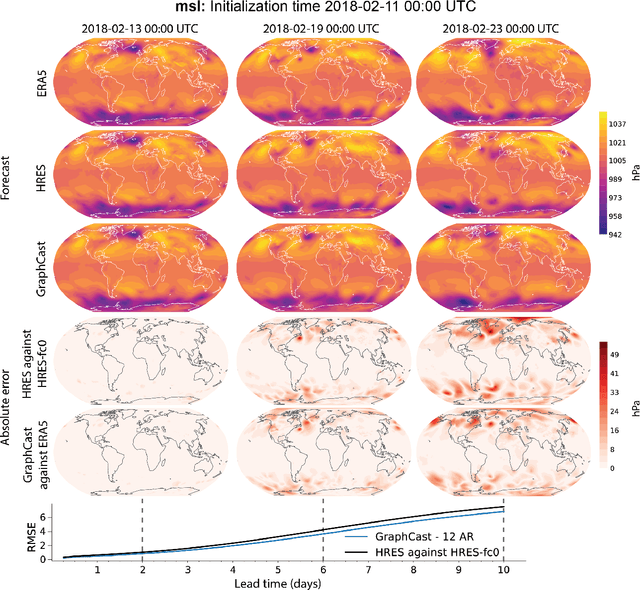
We introduce a machine-learning (ML)-based weather simulator--called "GraphCast"--which outperforms the most accurate deterministic operational medium-range weather forecasting system in the world, as well as all previous ML baselines. GraphCast is an autoregressive model, based on graph neural networks and a novel high-resolution multi-scale mesh representation, which we trained on historical weather data from the European Centre for Medium-Range Weather Forecasts (ECMWF)'s ERA5 reanalysis archive. It can make 10-day forecasts, at 6-hour time intervals, of five surface variables and six atmospheric variables, each at 37 vertical pressure levels, on a 0.25-degree latitude-longitude grid, which corresponds to roughly 25 x 25 kilometer resolution at the equator. Our results show GraphCast is more accurate than ECMWF's deterministic operational forecasting system, HRES, on 90.0% of the 2760 variable and lead time combinations we evaluated. GraphCast also outperforms the most accurate previous ML-based weather forecasting model on 99.2% of the 252 targets it reported. GraphCast can generate a 10-day forecast (35 gigabytes of data) in under 60 seconds on Cloud TPU v4 hardware. Unlike traditional forecasting methods, ML-based forecasting scales well with data: by training on bigger, higher quality, and more recent data, the skill of the forecasts can improve. Together these results represent a key step forward in complementing and improving weather modeling with ML, open new opportunities for fast, accurate forecasting, and help realize the promise of ML-based simulation in the physical sciences.
se-Shweshwe Inspired Fashion Generation
Feb 25, 2022
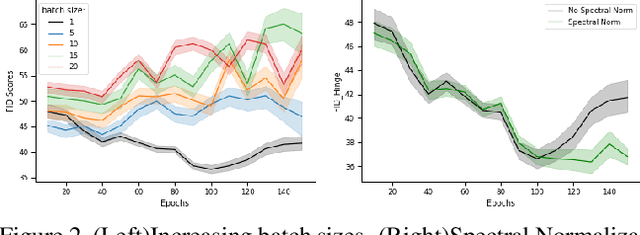
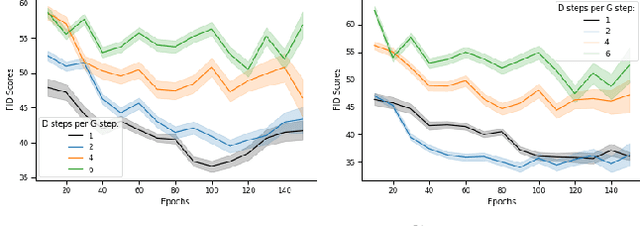
Fashion is one of the ways in which we show ourselves to the world. It is a reflection of our personal decisions and one of the ways in which people distinguish and represent themselves. In this paper, we focus on the fashion design process and expand computer vision for fashion beyond its current focus on western fashion. We discuss the history of Southern African se-Shweshwe fabric fashion, the collection of a se-Shweshwe dataset, and the application of sketch-to-design image generation for affordable fashion-design. The application to fashion raises both technical questions of training with small amounts of data, and also important questions for computer vision beyond fairness, in particular ethical considerations on creating and employing fashion datasets, and how computer vision supports cultural representation and might avoid algorithmic cultural appropriation.