 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Theater Stage as Laboratory: Review of Real-Time Comedy LLM Systems for Live Performance
Jan 14, 2025In this position paper, we review the eclectic recent history of academic and artistic works involving computational systems for humor generation, and focus specifically on live performance. We make the case that AI comedy should be evaluated in live conditions, in front of audiences sharing either physical or online spaces, and under real-time constraints. We further suggest that improvised comedy is therefore the perfect substrate for deploying and assessing computational humor systems. Using examples of successful AI-infused shows, we demonstrate that live performance raises three sets of challenges for computational humor generation: 1) questions around robotic embodiment, anthropomorphism and competition between humans and machines, 2) questions around comedic timing and the nature of audience interaction, and 3) questions about the human interpretation of seemingly absurd AI-generated humor. We argue that these questions impact the choice of methodologies for evaluating computational humor, as any such method needs to work around the constraints of live audiences and performance spaces. These interrogations also highlight different types of collaborative relationship of human comedians towards AI tools.
A Robot Walks into a Bar: Can Language Models Serve as Creativity Support Tools for Comedy? An Evaluation of LLMs' Humour Alignment with Comedians
Jun 03, 2024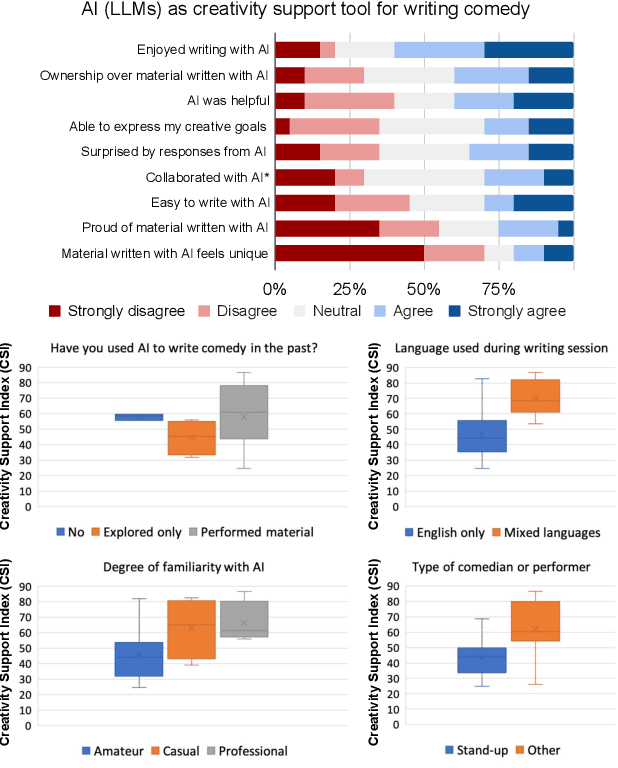
We interviewed twenty professional comedians who perform live shows in front of audiences and who use artificial intelligence in their artistic process as part of 3-hour workshops on ``AI x Comedy'' conducted at the Edinburgh Festival Fringe in August 2023 and online. The workshop consisted of a comedy writing session with large language models (LLMs), a human-computer interaction questionnaire to assess the Creativity Support Index of AI as a writing tool, and a focus group interrogating the comedians' motivations for and processes of using AI, as well as their ethical concerns about bias, censorship and copyright. Participants noted that existing moderation strategies used in safety filtering and instruction-tuned LLMs reinforced hegemonic viewpoints by erasing minority groups and their perspectives, and qualified this as a form of censorship. At the same time, most participants felt the LLMs did not succeed as a creativity support tool, by producing bland and biased comedy tropes, akin to ``cruise ship comedy material from the 1950s, but a bit less racist''. Our work extends scholarship about the subtle difference between, one the one hand, harmful speech, and on the other hand, ``offensive'' language as a practice of resistance, satire and ``punching up''. We also interrogate the global value alignment behind such language models, and discuss the importance of community-based value alignment and data ownership to build AI tools that better suit artists' needs.