 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillful joint probabilistic weather forecasting from marginals
Jun 12, 2025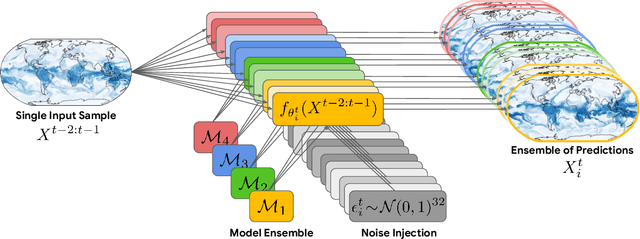
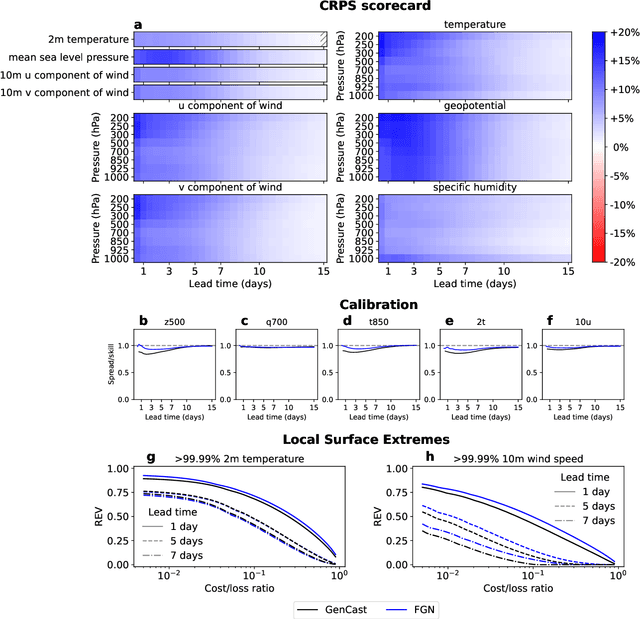
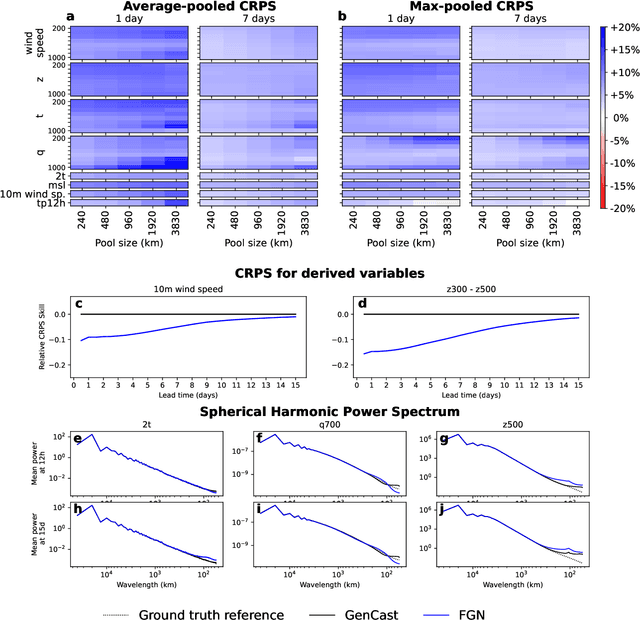
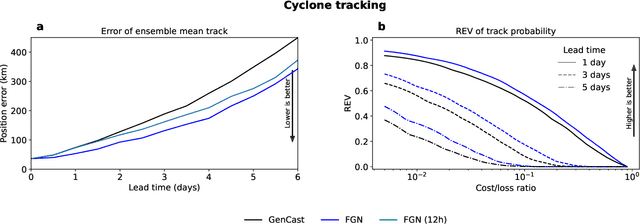
Machine learning (ML)-based weather models have rapidly risen to prominence due to their greater accuracy and speed than traditional forecasts based on numerical weather prediction (NWP), recently outperforming traditional ensembles in global probabilistic weather forecasting. This paper presents FGN, a simple, scalable and flexible modeling approach which significantly outperforms the current state-of-the-art models. FGN generates ensembles via learned model-perturbations with an ensemble of appropriately constrained models. It is trained directly to minimize the continuous rank probability score (CRPS) of per-location forecasts. It produces state-of-the-art ensemble forecasts as measured by a range of deterministic and probabilistic metrics, makes skillful ensemble tropical cyclone track predictions, and captures joint spatial structure despite being trained only on marginals.
Deep Neural Network Initialization with Sparsity Inducing Activations
Feb 25, 2024

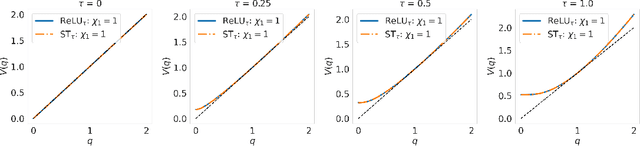
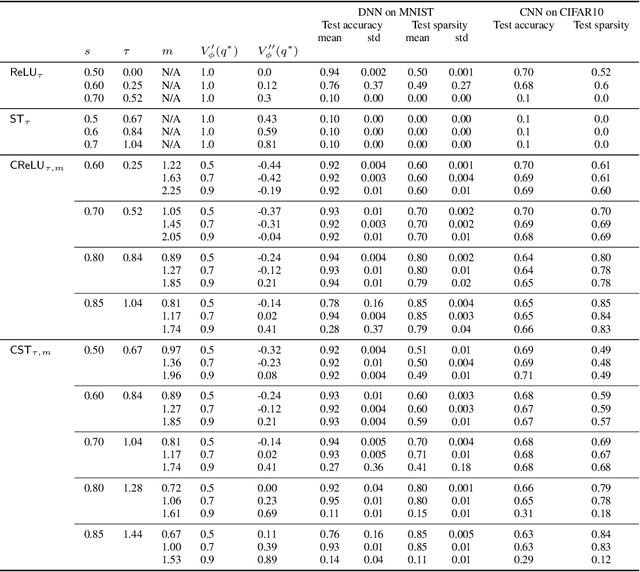
Inducing and leveraging sparse activations during training and inference is a promising avenue for improving the computational efficiency of deep networks, which is increasingly important as network sizes continue to grow and their application becomes more widespread. Here we use the large width Gaussian process limit to analyze the behaviour, at random initialization, of nonlinear activations that induce sparsity in the hidden outputs. A previously unreported form of training instability is proven for arguably two of the most natural candidates for hidden layer sparsification; those being a shifted ReLU ($\phi(x)=\max(0, x-\tau)$ for $\tau\ge 0$) and soft thresholding ($\phi(x)=0$ for $|x|\le\tau$ and $x-\text{sign}(x)\tau$ for $|x|>\tau$). We show that this instability is overcome by clipping the nonlinear activation magnitude, at a level prescribed by the shape of the associated Gaussian process variance map. Numerical experiments verify the theory and show that the proposed magnitude clipped sparsifying activations can be trained with training and test fractional sparsity as high as 85\% while retaining close to full accuracy.
GenCast: Diffusion-based ensemble forecasting for medium-range weather
Dec 25, 2023



Probabilistic weather forecasting is critical for decision-making in high-impact domains such as flood forecasting, energy system planning or transportation routing, where quantifying the uncertainty of a forecast -- including probabilities of extreme events -- is essential to guide important cost-benefit trade-offs and mitigation measures. Traditional probabilistic approaches rely on producing ensembles from physics-based models, which sample from a joint distribution over spatio-temporally coherent weather trajectories, but are expensive to run. An efficient alternative is to use a machine learning (ML) forecast model to generate the ensemble, however state-of-the-art ML forecast models for medium-range weather are largely trained to produce deterministic forecasts which minimise mean-squared-error. Despite improving skills scores, they lack physical consistency, a limitation that grows at longer lead times and impacts their ability to characterize the joint distribution. We introduce GenCast, a ML-based generative model for ensemble weather forecasting, trained from reanalysis data. It forecasts ensembles of trajectories for 84 weather variables, for up to 15 days at 1 degree resolution globally, taking around a minute per ensemble member on a single Cloud TPU v4 device. We show that GenCast is more skillful than ENS, a top operational ensemble forecast, for more than 96\% of all 1320 verification targets on CRPS and Ensemble-Mean RMSE, while maintaining good reliability and physically consistent power spectra. Together our results demonstrate that ML-based probabilistic weather forecasting can now outperform traditional ensemble systems at 1 degree, opening new doors to skillful, fast weather forecasts that are useful in key applications.
Improved Projection Learning for Lower Dimensional Feature Maps
Oct 27, 2022



The requirement to repeatedly move large feature maps off- and on-chip during inference with convolutional neural networks (CNNs) imposes high costs in terms of both energy and time. In this work we explore an improved method for compressing all feature maps of pre-trained CNNs to below a specified limit. This is done by means of learned projections trained via end-to-end finetuning, which can then be folded and fused into the pre-trained network. We also introduce a new `ceiling compression' framework in which evaluate such techniques in view of the future goal of performing inference fully on-chip.
Increasing the accuracy and resolution of precipitation forecasts using deep generative models
Mar 23, 2022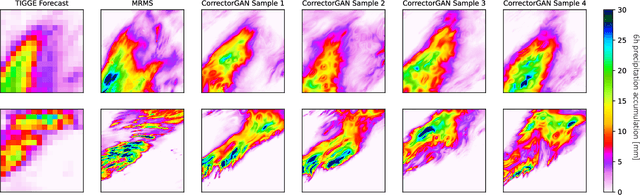
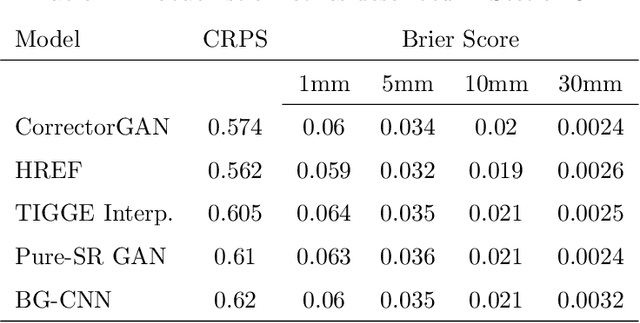
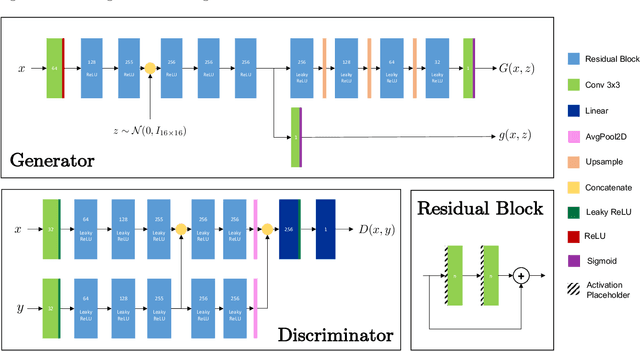
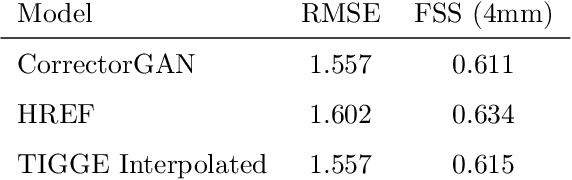
Accurately forecasting extreme rainfall is notoriously difficult, but is also ever more crucial for society as climate change increases the frequency of such extremes. Global numerical weather prediction models often fail to capture extremes, and are produced at too low a resolution to be actionable, while regional, high-resolution models are hugely expensive both in computation and labour. In this paper we explore the use of deep generative models to simultaneously correct and downscale (super-resolve) global ensemble forecasts over the Continental US. Specifically, using fine-grained radar observations as our ground truth, we train a conditional Generative Adversarial Network -- coined CorrectorGAN -- via a custom training procedure and augmented loss function, to produce ensembles of high-resolution, bias-corrected forecasts based on coarse, global precipitation forecasts in addition to other relevant meteorological fields. Our model outperforms an interpolation baseline, as well as super-resolution-only and CNN-based univariate methods, and approaches the performance of an operational regional high-resolution model across an array of established probabilistic metrics. Crucially, CorrectorGAN, once trained, produces predictions in seconds on a single machine. These results raise exciting questions about the necessity of regional models, and whether data-driven downscaling and correction methods can be transferred to data-poor regions that so far have had no access to high-resolution forecasts.
Dense for the Price of Sparse: Improved Performance of Sparsely Initialized Networks via a Subspace Offset
Feb 12, 2021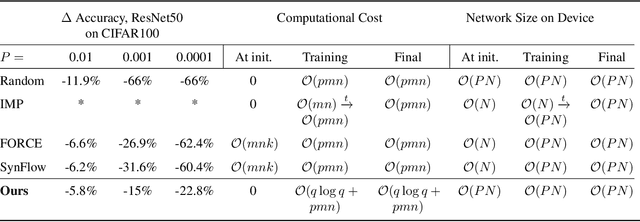
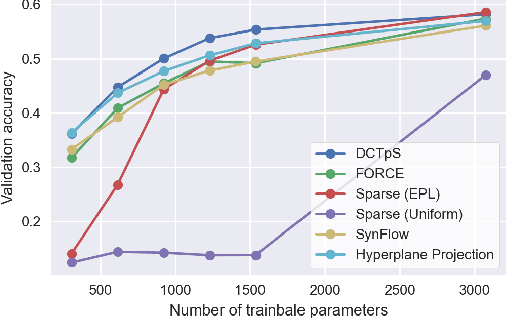
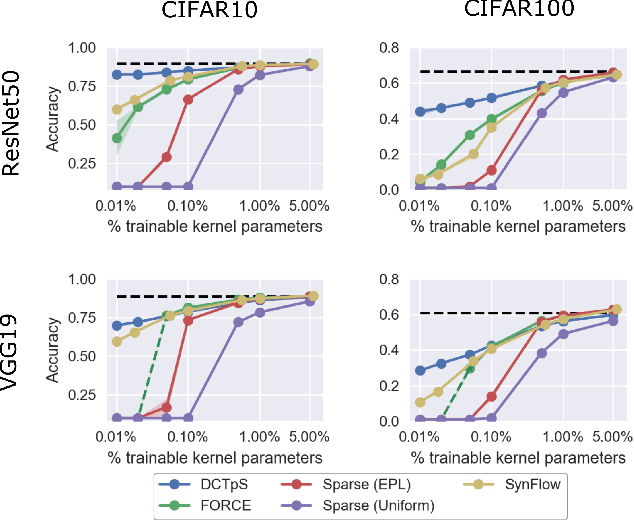

That neural networks may be pruned to high sparsities and retain high accuracy is well established. Recent research efforts focus on pruning immediately after initialization so as to allow the computational savings afforded by sparsity to extend to the training process. In this work, we introduce a new `DCT plus Sparse' layer architecture, which maintains information propagation and trainability even with as little as 0.01% trainable kernel parameters remaining. We show that standard training of networks built with these layers, and pruned at initialization, achieves state-of-the-art accuracy for extreme sparsities on a variety of benchmark network architectures and datasets. Moreover, these results are achieved using only simple heuristics to determine the locations of the trainable parameters in the network, and thus without having to initially store or compute with the full, unpruned network, as is required by competing prune-at-initialization algorithms. Switching from standard sparse layers to DCT plus Sparse layers does not increase the storage footprint of a network and incurs only a small additional computational overhead.
Six Attributes of Unhealthy Conversation
Oct 14, 2020
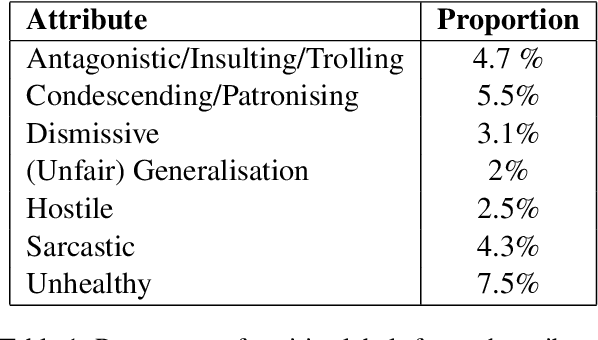
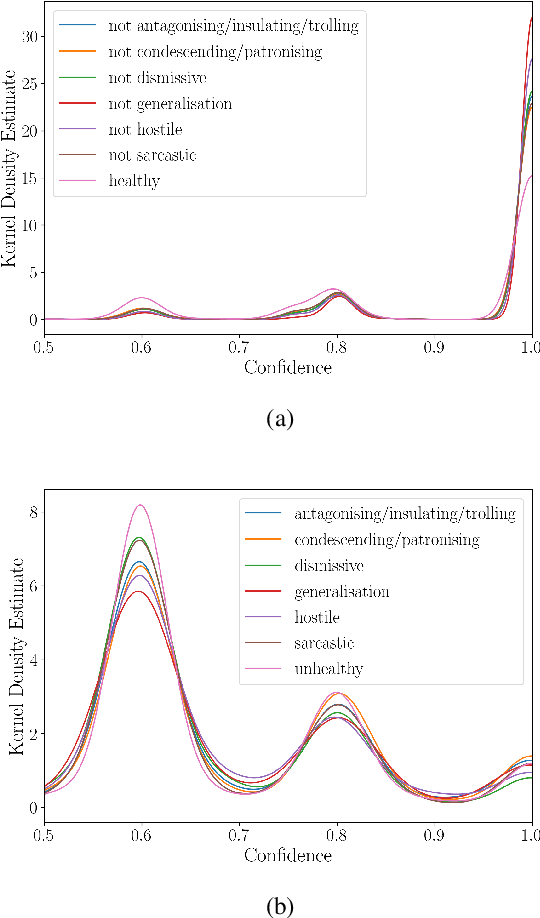

We present a new dataset of approximately 44000 comments labeled by crowdworkers. Each comment is labelled as either 'healthy' or 'unhealthy', in addition to binary labels for the presence of six potentially 'unhealthy' sub-attributes: (1) hostile; (2) antagonistic, insulting, provocative or trolling; (3) dismissive; (4) condescending or patronising; (5) sarcastic; and/or (6) an unfair generalisation. Each label also has an associated confidence score. We argue that there is a need for datasets which enable research based on a broad notion of 'unhealthy online conversation'. We build this typology to encompass a substantial proportion of the individual comments which contribute to unhealthy online conversation. For some of these attributes, this is the first publicly available dataset of this scale. We explore the quality of the dataset, present some summary statistics and initial models to illustrate the utility of this data, and highlight limitations and directions for further research.
Trajectory growth lower bounds for random sparse deep ReLU networks
Nov 25, 2019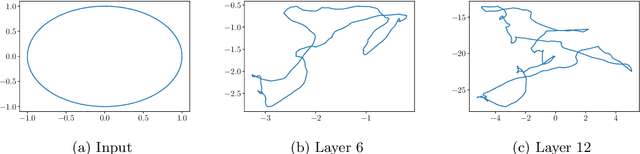

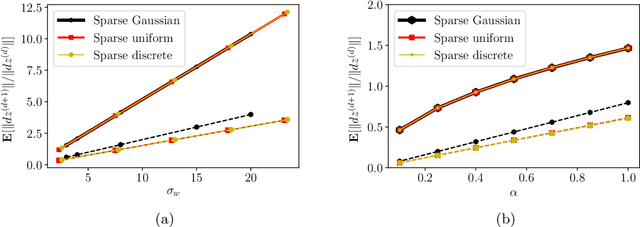

This paper considers the growth in the length of one-dimensional trajectories as they are passed through deep ReLU neural networks, which, among other things, is one measure of the expressivity of deep networks. We generalise existing results, providing an alternative, simpler method for lower bounding expected trajectory growth through random networks, for a more general class of weights distributions, including sparsely connected networks. We illustrate this approach by deriving bounds for sparse-Gaussian, sparse-uniform, and sparse-discrete-valued random nets. We prove that trajectory growth can remain exponential in depth with these new distributions, including their sparse variants, with the sparsity parameter appearing in the base of the exponent.