 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillful joint probabilistic weather forecasting from marginals
Jun 12, 2025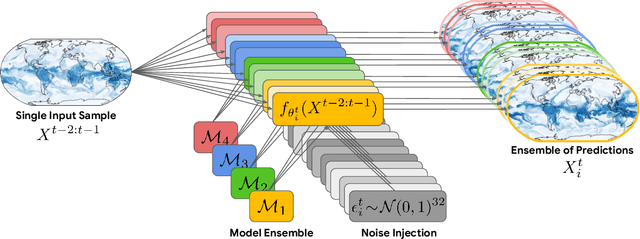
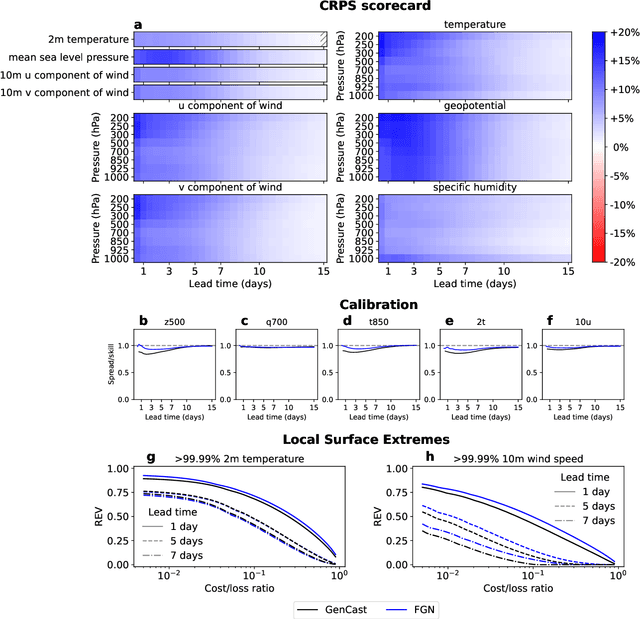
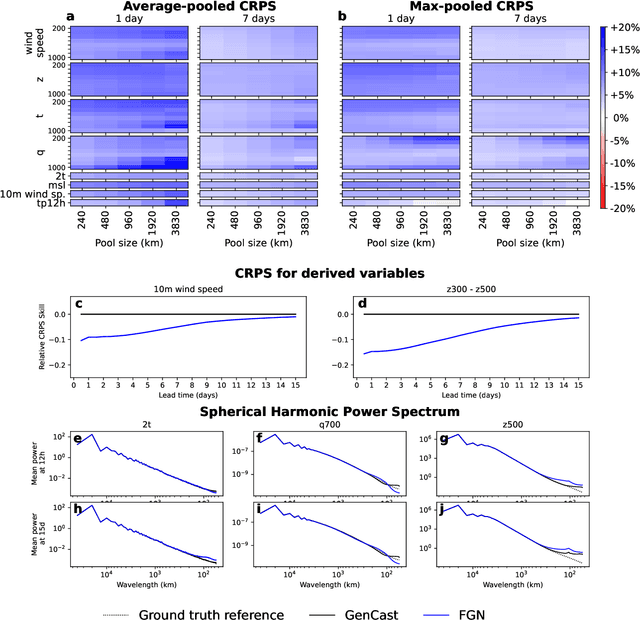
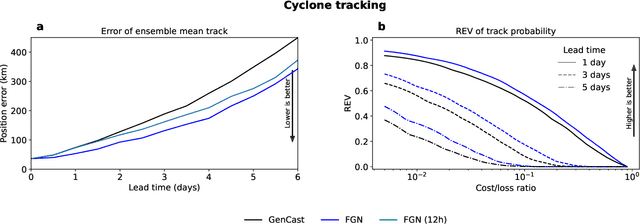
Machine learning (ML)-based weather models have rapidly risen to prominence due to their greater accuracy and speed than traditional forecasts based on numerical weather prediction (NWP), recently outperforming traditional ensembles in global probabilistic weather forecasting. This paper presents FGN, a simple, scalable and flexible modeling approach which significantly outperforms the current state-of-the-art models. FGN generates ensembles via learned model-perturbations with an ensemble of appropriately constrained models. It is trained directly to minimize the continuous rank probability score (CRPS) of per-location forecasts. It produces state-of-the-art ensemble forecasts as measured by a range of deterministic and probabilistic metrics, makes skillful ensemble tropical cyclone track predictions, and captures joint spatial structure despite being trained only on marginals.
Functional Risk Minimization
Dec 30, 2024The field of Machine Learning has changed significantly since the 1970s. However, its most basic principle, Empirical Risk Minimization (ERM), remains unchanged. We propose Functional Risk Minimization~(FRM), a general framework where losses compare functions rather than outputs. This results in better performance in supervised, unsupervised, and RL experiments. In the FRM paradigm, for each data point $(x_i,y_i)$ there is function $f_{\theta_i}$ that fits it: $y_i = f_{\theta_i}(x_i)$. This allows FRM to subsume ERM for many common loss functions and to capture more realistic noise processes. We also show that FRM provides an avenue towards understanding generalization in the modern over-parameterized regime, as its objective can be framed as finding the simplest model that fits the training data.
GenCast: Diffusion-based ensemble forecasting for medium-range weather
Dec 25, 2023



Probabilistic weather forecasting is critical for decision-making in high-impact domains such as flood forecasting, energy system planning or transportation routing, where quantifying the uncertainty of a forecast -- including probabilities of extreme events -- is essential to guide important cost-benefit trade-offs and mitigation measures. Traditional probabilistic approaches rely on producing ensembles from physics-based models, which sample from a joint distribution over spatio-temporally coherent weather trajectories, but are expensive to run. An efficient alternative is to use a machine learning (ML) forecast model to generate the ensemble, however state-of-the-art ML forecast models for medium-range weather are largely trained to produce deterministic forecasts which minimise mean-squared-error. Despite improving skills scores, they lack physical consistency, a limitation that grows at longer lead times and impacts their ability to characterize the joint distribution. We introduce GenCast, a ML-based generative model for ensemble weather forecasting, trained from reanalysis data. It forecasts ensembles of trajectories for 84 weather variables, for up to 15 days at 1 degree resolution globally, taking around a minute per ensemble member on a single Cloud TPU v4 device. We show that GenCast is more skillful than ENS, a top operational ensemble forecast, for more than 96\% of all 1320 verification targets on CRPS and Ensemble-Mean RMSE, while maintaining good reliability and physically consistent power spectra. Together our results demonstrate that ML-based probabilistic weather forecasting can now outperform traditional ensemble systems at 1 degree, opening new doors to skillful, fast weather forecasts that are useful in key applications.
Neural Relational Inference with Fast Modular Meta-learning
Oct 10, 2023\textit{Graph neural networks} (GNNs) are effective models for many dynamical systems consisting of entities and relations. Although most GNN applications assume a single type of entity and relation, many situations involve multiple types of interactions. \textit{Relational inference} is the problem of inferring these interactions and learning the dynamics from observational data. We frame relational inference as a \textit{modular meta-learning} problem, where neural modules are trained to be composed in different ways to solve many tasks. This meta-learning framework allows us to implicitly encode time invariance and infer relations in context of one another rather than independently, which increases inference capacity. Framing inference as the inner-loop optimization of meta-learning leads to a model-based approach that is more data-efficient and capable of estimating the state of entities that we do not observe directly, but whose existence can be inferred from their effect on observed entities. To address the large search space of graph neural network compositions, we meta-learn a \textit{proposal function} that speeds up the inner-loop simulated annealing search within the modular meta-learning algorithm, providing two orders of magnitude increase in the size of problems that can be addressed.
GraphCast: Learning skillful medium-range global weather forecasting
Dec 24, 2022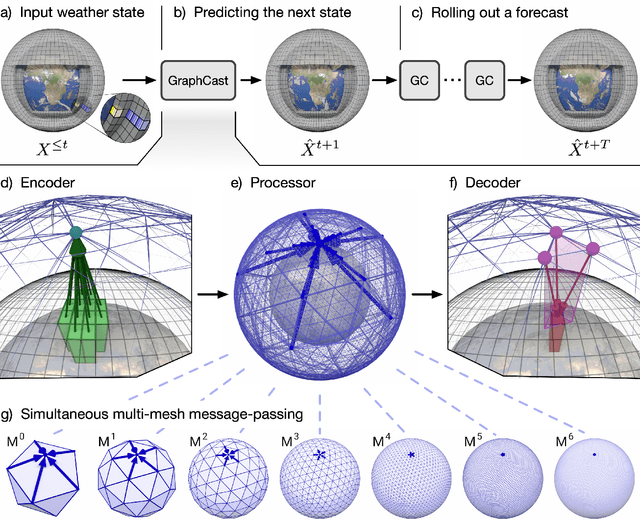
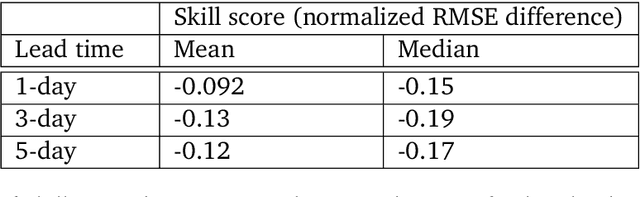
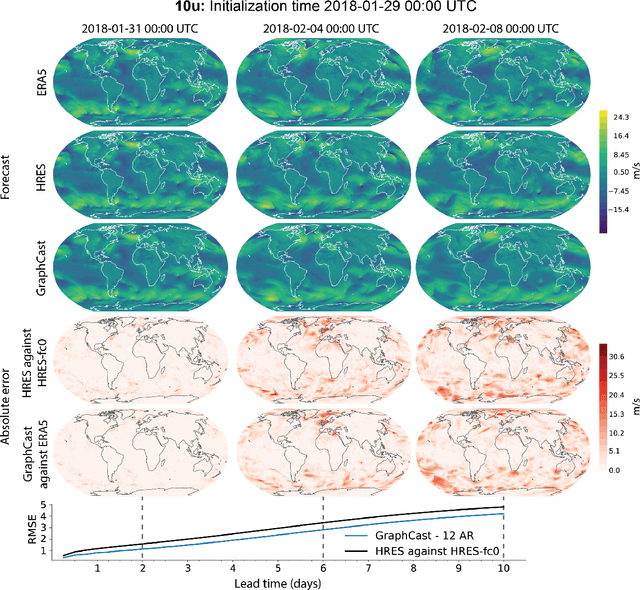
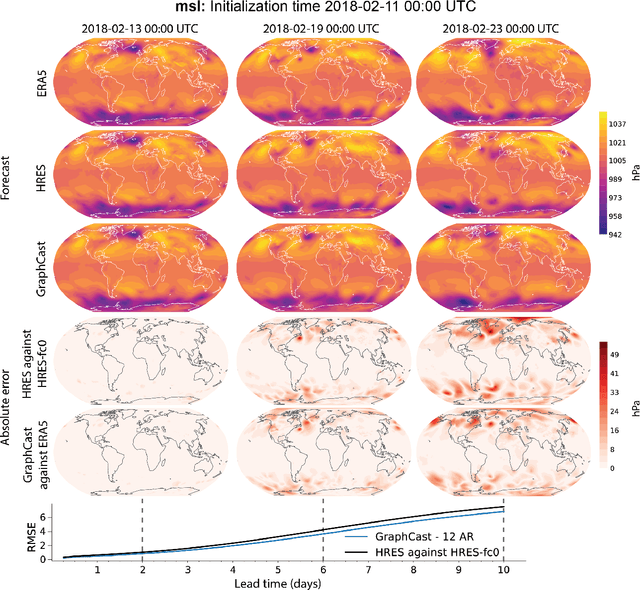
We introduce a machine-learning (ML)-based weather simulator--called "GraphCast"--which outperforms the most accurate deterministic operational medium-range weather forecasting system in the world, as well as all previous ML baselines. GraphCast is an autoregressive model, based on graph neural networks and a novel high-resolution multi-scale mesh representation, which we trained on historical weather data from the European Centre for Medium-Range Weather Forecasts (ECMWF)'s ERA5 reanalysis archive. It can make 10-day forecasts, at 6-hour time intervals, of five surface variables and six atmospheric variables, each at 37 vertical pressure levels, on a 0.25-degree latitude-longitude grid, which corresponds to roughly 25 x 25 kilometer resolution at the equator. Our results show GraphCast is more accurate than ECMWF's deterministic operational forecasting system, HRES, on 90.0% of the 2760 variable and lead time combinations we evaluated. GraphCast also outperforms the most accurate previous ML-based weather forecasting model on 99.2% of the 252 targets it reported. GraphCast can generate a 10-day forecast (35 gigabytes of data) in under 60 seconds on Cloud TPU v4 hardware. Unlike traditional forecasting methods, ML-based forecasting scales well with data: by training on bigger, higher quality, and more recent data, the skill of the forecasts can improve. Together these results represent a key step forward in complementing and improving weather modeling with ML, open new opportunities for fast, accurate forecasting, and help realize the promise of ML-based simulation in the physical sciences.
Noether Networks: Meta-Learning Useful Conserved Quantities
Dec 06, 2021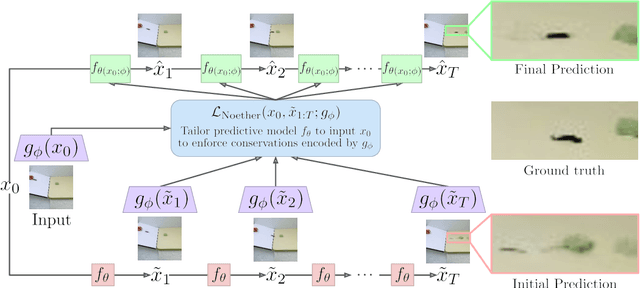
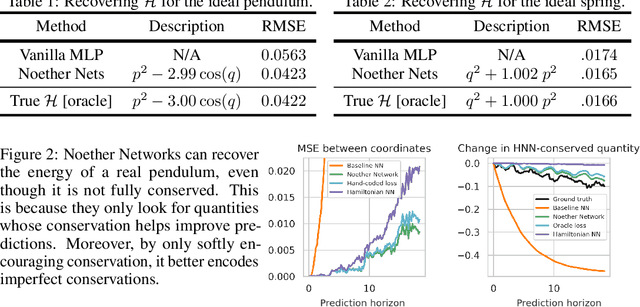
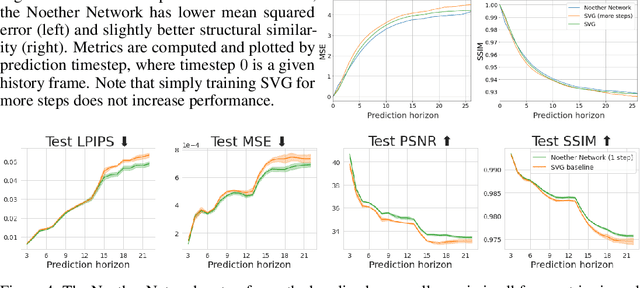

Progress in machine learning (ML) stems from a combination of data availability, computational resources, and an appropriate encoding of inductive biases. Useful biases often exploit symmetries in the prediction problem, such as convolutional networks relying on translation equivariance. Automatically discovering these useful symmetries holds the potential to greatly improve the performance of ML systems, but still remains a challenge. In this work, we focus on sequential prediction problems and take inspiration from Noether's theorem to reduce the problem of finding inductive biases to meta-learning useful conserved quantities. We propose Noether Networks: a new type of architecture where a meta-learned conservation loss is optimized inside the prediction function. We show, theoretically and experimentally, that Noether Networks improve prediction quality, providing a general framework for discovering inductive biases in sequential problems.
Tailoring: encoding inductive biases by optimizing unsupervised objectives at prediction time
Oct 14, 2020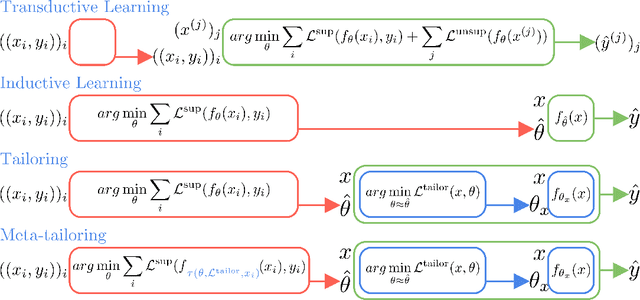
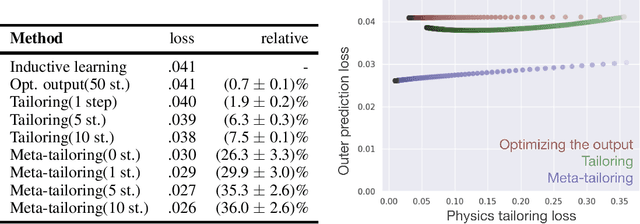
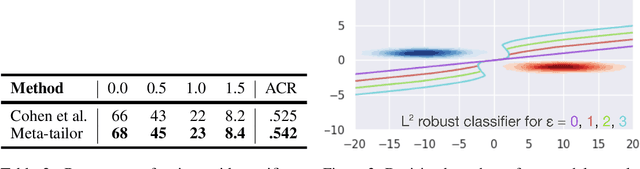
From CNNs to attention mechanisms, encoding inductive biases into neural networks has been a fruitful source of improvement in machine learning. Auxiliary losses are a general way of encoding biases in order to help networks learn better representations by adding extra terms to the loss function. However, since they are minimized on the training data, they suffer from the same generalization gap as regular task losses. Moreover, by changing the loss function, the network is optimizing a different objective than the one we care about. In this work we solve both problems: first, we take inspiration from \textit{transductive learning} and note that, after receiving an input but before making a prediction, we can fine-tune our models on any unsupervised objective. We call this process tailoring, because we customize the model to each input. Second, we formulate a nested optimization (similar to those in meta-learning) and train our models to perform well on the task loss after adapting to the tailoring loss. The advantages of tailoring and meta-tailoring are discussed theoretically and demonstrated empirically on several diverse examples: encoding inductive conservation laws from physics to improve predictions, improving local smoothness to increase robustness to adversarial examples, and using contrastive losses on the query image to improve generalization.
Meta-learning curiosity algorithms
Mar 11, 2020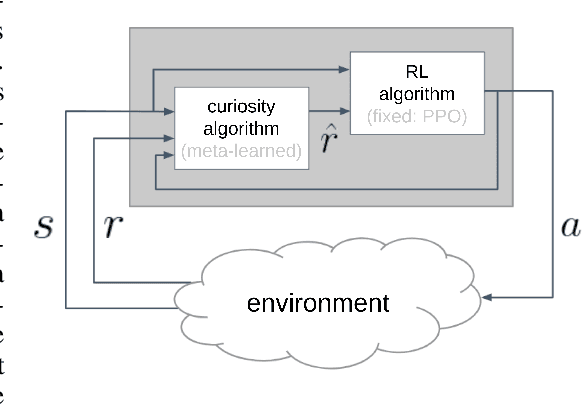
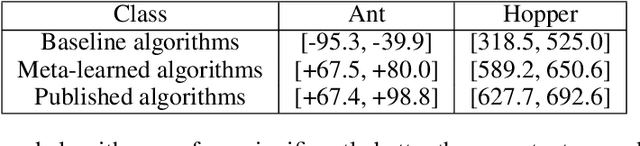
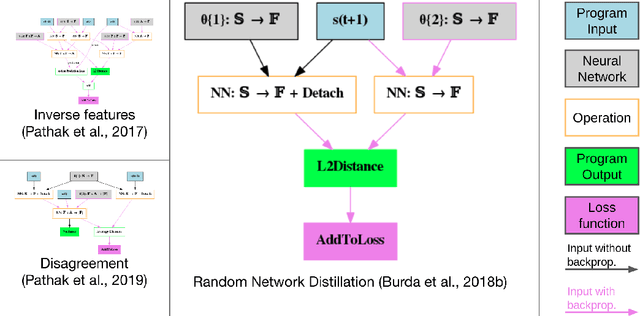
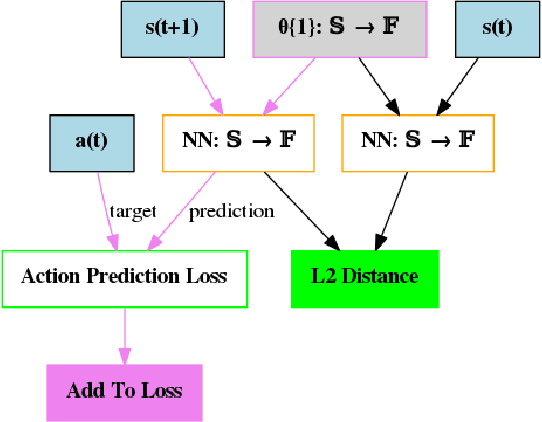
We hypothesize that curiosity is a mechanism found by evolution that encourages meaningful exploration early in an agent's life in order to expose it to experiences that enable it to obtain high rewards over the course of its lifetime. We formulate the problem of generating curious behavior as one of meta-learning: an outer loop will search over a space of curiosity mechanisms that dynamically adapt the agent's reward signal, and an inner loop will perform standard reinforcement learning using the adapted reward signal. However, current meta-RL methods based on transferring neural network weights have only generalized between very similar tasks. To broaden the generalization, we instead propose to meta-learn algorithms: pieces of code similar to those designed by humans in ML papers. Our rich language of programs combines neural networks with other building blocks such as buffers, nearest-neighbor modules and custom loss functions. We demonstrate the effectiveness of the approach empirically, finding two novel curiosity algorithms that perform on par or better than human-designed published curiosity algorithms in domains as disparate as grid navigation with image inputs, acrobot, lunar lander, ant and hopper.
Omnipush: accurate, diverse, real-world dataset of pushing dynamics with RGB-D video
Oct 01, 2019


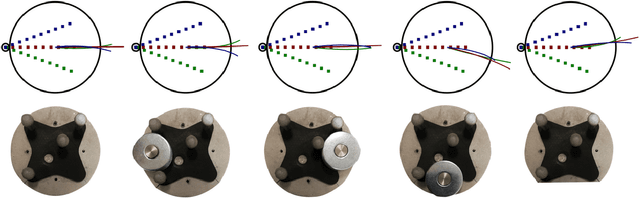
Pushing is a fundamental robotic skill. Existing work has shown how to exploit models of pushing to achieve a variety of tasks, including grasping under uncertainty, in-hand manipulation and clearing clutter. Such models, however, are approximate, which limits their applicability. Learning-based methods can reason directly from raw sensory data with accuracy, and have the potential to generalize to a wider diversity of scenarios. However, developing and testing such methods requires rich-enough datasets. In this paper we introduce Omnipush, a dataset with high variety of planar pushing behavior. In particular, we provide 250 pushes for each of 250 objects, all recorded with RGB-D and a high precision tracking system. The objects are constructed so as to systematically explore key factors that affect pushing --the shape of the object and its mass distribution-- which have not been broadly explored in previous datasets, and allow to study generalization in model learning. Omnipush includes a benchmark for meta-learning dynamic models, which requires algorithms that make good predictions and estimate their own uncertainty. We also provide an RGB video prediction benchmark and propose other relevant tasks that can be suited with this dataset. Data and code are available at \url{https://web.mit.edu/mcube/omnipush-dataset/}.
Graph Element Networks: adaptive, structured computation and memory
May 13, 2019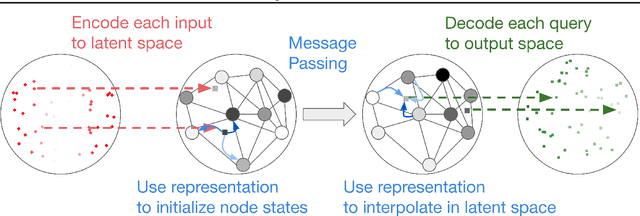
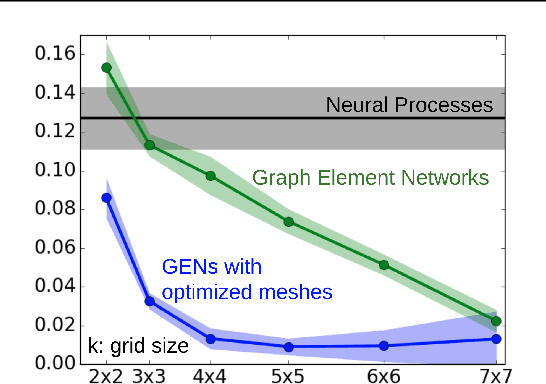
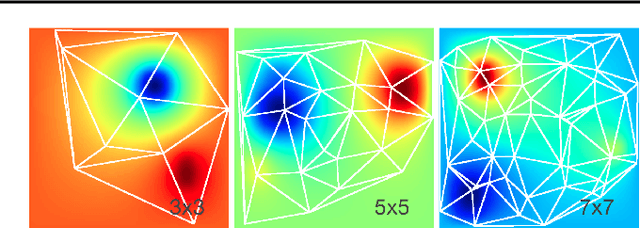
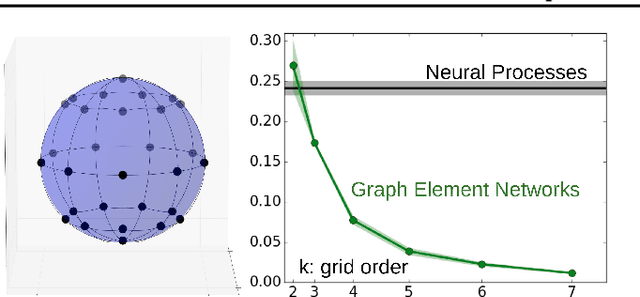
We explore the use of graph neural networks (GNNs) to model spatial processes in which there is no a priori graphical structure. Similar to finite element analysis, we assign nodes of a GNN to spatial locations and use a computational process defined on the graph to model the relationship between an initial function defined over a space and a resulting function in the same space. We use GNNs as a computational substrate, and show that the locations of the nodes in space as well as their connectivity can be optimized to focus on the most complex parts of the space. Moreover, this representational strategy allows the learned input-output relationship to generalize over the size of the underlying space and run the same model at different levels of precision, trading computation for accuracy. We demonstrate this method on a traditional PDE problem, a physical prediction problem from robotics, and learning to predict scene images from novel viewpoints.